
Užití teorie množin v jazykovědě
Anna Jaurisová, Miroslav Jauris
[Rozhledy]
Применение теории множеств в языкознании / Emploi de la théorie des ensembles en linguistique
O. S. Kulaginová, žačka prof. A. A. Ljapunova, předního představitele sovětských matematiků pracujících na otázkách strojového překladu, uvažuje v článku O způsobu definování gramatických pojmů na základě teorie množin[1] o vytvoření speciálních metod vhodných pro analýzu a popis kteréhokoli jazyka. V úvodu ukazuje na to, že vytvoření algoritmu pro strojový překlad předpokládá přesně definovaný gramatický systém. Dosavadní gramatiky jím vždy nejsou. Užívají pojmů, které není nutno přesně definovat a které bývají objasňovány opisem, nezřídka s odkazem na smysl; předpokládají ovšem jako uživatele člověka. (I ve zpracování, jaké předpokládá autorka, pracuje se s jednotkami „smyslu“, pokud je lze zachycovat vhodným formálním způsobem.) Stanovit přesnými definicemi soustavu gramatických vztahů a na tomto základě vytvořit algoritmy pro strojový překlad je jedním z úkolů matematické lingvistiky. Příspěvkem k tomu je i článek O. S. Kulaginové.
Metody, kterých O. S. Kulaginová užívá, jsou obdobné metodám užívaným při vytváření matematických teorií. Nepředpokládá žádný dosavadní gramatický systém a za základ svého zkoumání si volí pojmy, které jsou dány zvnějšku a které v daném systému nedefinuje. Jsou to: 1. konečná množina[2] slov ![]() (nazveme si ji slovníkem);[3] konečné posloupnosti[4] slov — i prázdné —, v kterých se totéž slovo může objevovat i na více místech, nazývají se větami; 2. množina vyznačených (otmečennych) vět v dalším textu budeme nazývat vyznačené věty správnými větami;[5] 3. systém vzájemně disjunktních podmnožin slov[35]níku,[6] okruhy slova;[7] slovník s daným systémem okruhů a s danou množinou správných vět je nazýván jazykem.
(nazveme si ji slovníkem);[3] konečné posloupnosti[4] slov — i prázdné —, v kterých se totéž slovo může objevovat i na více místech, nazývají se větami; 2. množina vyznačených (otmečennych) vět v dalším textu budeme nazývat vyznačené věty správnými větami;[5] 3. systém vzájemně disjunktních podmnožin slov[35]níku,[6] okruhy slova;[7] slovník s daným systémem okruhů a s danou množinou správných vět je nazýván jazykem.
V úvodu chceme zdůraznit, že podáváme jen podrobnou zprávu o článku s nejnutnějším aparátem teorie množin, bez důkazů teorémů. Zpráva je psána na úrovni méně abstraktní, než jakou má původní práce. Pro názornost doplňujeme zprávu příklady z češtiny. Vycházíme při nich z fragmentárních „slovníků“ a nechceme jimi dokázat obecnou platnost definic v českém jazyce.
Je-li dána nějaká věta A a každému slovu této věty můžeme přiřadit gramatickou kategorii, do které toto slovo patří, pak každé větě (posloupnosti slov) odpovídá příslušná posloupnost gramatických kategorií — struktura této věty.
Kulaginová uvažuje o různých rozkladech[8] slovníku (o rozkladu na soubory stejnovýznamových tvarů, o rozkladu na třídy, o rozkladu na typy) a definuje strukturu dané věty vzhledem k danému rozkladu slovníku. Označíme-li daný rozklad slovníku např. B, strukturu věty A vzhledem k tomuto rozkladu budeme značit B(A). Předpokládejme, že máme nějaký rozklad slovníku a nějakou větu A; napíšeme-li místo každého slova dané věty onen prvek rozkladu, do kterého toto slovo patří, získáme B-strukturu věty A (strukturu věty A vzhledem k rozkladu B). Mějme např. rozklad: {množina podstatných jmen, množina sloves, množina ostatních slov}. Věta „Praha je město“ má vzhledem k tomuto rozkladu takovouto strukturu: množina podstatných jmen, množina sloves, množina podstatných jmen.
B-struktura věty je správná tehdy a jen tehdy, když existuje aspoň jedna správná věta, která tuto strukturu má.
Jedním z nejdůležitějších vztahů mezi dvěma prvky daného rozkladu slovníku je vztah jejich ekvivalence vzhledem k danému rozkladu. Jestliže si daný rozklad slovníku označíme B, pak ekvivalenci dvou prvků tohoto rozkladu vzhledem k tomuto rozkladu budeme nazývat B-ekvivalencí. Předpokládejme, že Bi a Bj jsou dva prvky nějakého rozkladu B. Ty jsou navzájem B-ekvivalentní tehdy a jen tehdy, když v B-struktuře libovolné věty můžeme jeden nahradit druhým, aniž se nám správná struktura změní v nesprávnou nebo naopak. Ilustraci tohoto mimořádně důležitého vztahu uvedeme v dalším textu.
Jedním z nejelementárnějších rozkladů slovníku je jeho jednotkový rozklad.[9] Kulaginová vychází z jednotkového rozkladu slovníku (budeme jej značit Bjed) a bere v úvahu nejprve struktury vzhledem k tomuto rozkladu. Bjed-strukturu věty A budeme značiti Bjed(A).
[36]Uveďme příklad slovníku, jeho jednotkový rozklad, příklad Bjed-struktury a Bjed-ekvivalence.
slovník = {stůl, koberec, stojan, květina, je, zelený, starý, zelená, stará}
Bjed = {{stůl}, {koberec}, {stojan}, {květina}, {je}, {zelený}, {starý}, {zelená}, {stará}}
A = stůl je zelený
Bjed(A) = {stůl}, {je}, {zelený}
B1jed = {stůl}
B2jed = {koberec}
Jestliže se nahrazením {stůl} pomocí {koberec} žádná správná Bjed-struktura nezmění v nesprávnou a naopak, jsou {stůl}, {koberec} vzájemně Bjed-ekvivalentní.
Dále budeme definovat tzv. odvozený rozklad vzhledem k Bjed-rozkladu, označíme si jej B'jed, který je zhrubením[10] Bjed-rozkladu. Definice zní: každý prvek B'jed-rozkladu se rovná sjednocení všech prvků Bjed-rozkladu, které jsou navzájem Bjed-ekvivalentní. B'jed-rozklad námi zvoleného slovníku bude: B'jed = {{stůl, koberec, stojan}, {květina}, {je}, {zelený, starý}, {zelená, stará}}. B'jed-rozklad je rozklad slovníku na tzv. tvarové soubory, tj. soubory stejnovýznamových tvarů (semějstva), prvky tohoto rozkladu jsou tvarové soubory. Jinými slovy řečeno: v tvarovém souboru se sjednocují taková slova, že záměna libovolného slova slovem z téhož tvarového souboru nezmění správnou větu v nesprávnou ani naopak.
Jazyk, na který Kulaginová omezuje svoje další úvahy, nazývá prostým jazykem. Je definován jako jazyk, v kterém platí následující vztahy (x, x', y označují libovolná, blíže neurčená slova):
1. Průnik okruhu, v kterém je slovo x, a tvarového souboru, v kterém je slovo x, obsahuje jediný prvek.
2. Jestliže slovo x' patří do okruhu slova x a slovo y patří do tvarového souboru slova x, pak průnik tvarového souboru slova x' a okruhu slova y není prázdná množina, čili obsahuje aspoň jedno slovo.
Uveďme si příklad, v kterém budou obě podmínky prostého jazyka splněny. Pro označení okruhu si zvolíme grafické znázornění: ![]() a pro označení tvarového souboru:
a pro označení tvarového souboru: ![]()
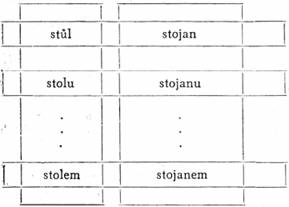
Zvolme si:
x — stolem
x' — stolu
y — stojanem
Ad 1. Průnik okruhu, v kterém je slovo x (stolem) a tvarového souboru, v kterém je slovo x (stolem), obsahuje jediné slovo x (stolem).
[37]Ad 2. Slovo x' (stolu) patří do okruhu slova x (stolem) a slovo y (stojanem) patří do tvarového souboru slova x (stolem) a platí také, že průnik tvarového souboru slova x' (stolu) a okruhu slova y (stojanem) není prázdná množina, obsahuje slovo stojanu.
Podotýkáme, že zvoleným příkladem nedokazujeme, že čeština je prostý jazyk. Neboť z toho, že pro některá česká slova a pro některou volbu trojic slov platí podmínky prostého jazyka, neplyne, že pro všechna slova a pro každou volbu trojic slov jsou podmínky prostého jazyka v češtině splněny.
V poznámce autorka uvádí, že ruština není prostým jazykem. Podstatná jména všech tří rodů, která se v daném pádě v jednotném čísle rozdělují do tří tvarových souborů, se v daném pádě v množném čísle všechna slučují v jeden tvarový soubor, v množném čísle jsou tedy Bjed-ekvivalentní (prichodili znakomyje ženščiny, prichodili znakomyje tovarišči apod.). Schematicky znázorněno:
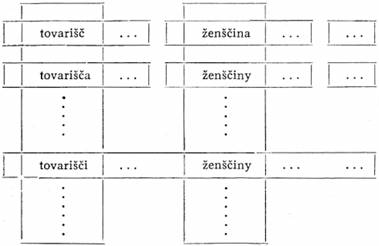
Zvolme si:
x = tovarišči
x' = tovarišč
y = ženščiny
Vidíme, že slovo x' (tovarišč) patří do okruhu slova x (tovarišči) a slovo y (ženščiny) patří do tvarového souboru slova x (tovarišči), avšak průnik tvarového souboru slova x' (tovarišč) a okruhu oslav y (ženščiny) je prázdná množina, čili neobsahuje žádný prvek.
V češtině nepatří v množném čísle podstatná jména rodu mužského, ženského a středního do jednoho tvarového souboru. Proto by nás obdobný příklad v češtině nepřesvědčil o tom, že čeština není prostý jazyk. Můžeme však uvést jiný příklad, v kterém ukážeme, že ani čeština není prostým jazykem. Schematicky znázorněno:
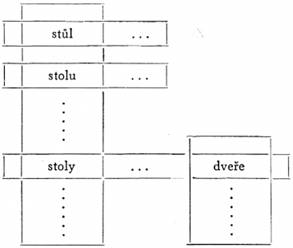
Zvolme si:
x = stoly
x' = stůl
y = dveře
Druhá podmínka prostého jazyka tu není splněna: slovo x' (stůl) patří do okruhu slova x (stoly) a slovo y (dveře) patří do tvarového souboru slova x (stoly), avšak průnik tvarového souboru slova x' (stůl) a okruhu slova y (dveře) je prázdná množina.
[38]Ovšem i z jazyka, který není prostý, lze někdy vybrati takovou část, která tvoří prostý jazyk. V příkladech, které dále pro názornost budeme uvádět, budeme předpokládat úsek češtiny, který splňuje podmínky prostého jazyka.
Další gramatickou kategorií, která je definována v prostém jazyce, je třída.[11] Třídou slova x — označíme si ji K (x) — budeme nazývat množinu slov x', která splňuje aspoň jednu z následujících podmínek: 1. Průnik okruhu slova x a tvarového souboru slova x' není prázdná množina. 2. Průnik okruhu slova x' a tvarového souboru slova x není prázdná množina. Lze dokázat, že v prostém jazyce jsou obě tyto podmínky vzájemně ekvivalentní. Jinak řečeno, jednu třídu tvoří taková slova, že v tvarovém souboru jednoho je slovo z okruhu druhého. Např. do třídy slova stolu patří slovo stojanem, neboť průnik okruhu slova stolu a tvarového souboru slova stojanem není prázdná množina.
Lze dokázati, že množina všech tříd je v prostém jazyce rozkladem slovníku (druhý teorém O. S. Kulaginové); označíme jej Bk.
Uveďme si příklad slovníku a jeho rozkladu na třídy:
slovník = {stůl, stojan, stolu, stojanu, květina, květině, cesta, cestě, je, zelený, zelenému, zelená, zelené}
Bk = {{stůl, stojan, stolu, stojanu}, {květina, květině, cesta, cestě}, {je}, {zelený, zelenému, zelená, zelené}}
Třídy lze definovat i v jazyce neprostém. Pak ale by jedno slovo mohlo patřit do dvou různých tříd a množina všech tříd by nebyla rozkladem slovníku. Uvedeme si konkrétní příklad rozkladu na třídy v neprostém jazyce — v ruštině.
Dokážeme, a) že třída slova ženščina se nerovná třídě slova ženščiny a b) že existuje prvek, který patří do obou těchto navzájem různých tříd.
Ad a) Slovo mužčina nepatří do třídy slova ženščina, protože průnik okruhu slova ženščina a tvarového souboru slova mužčina je prázdná množina a také průnik okruhu slova mužčina a tvarového souboru slova ženščina je prázdná množina. Slovo mužčina patří do třídy slova ženščiny, protože průnik okruhu slova mužčina a tvarového souboru slova ženščiny není prázdná množina.
Ad b) Slovo ženščina patří do třídy slova ženščiny, protože průnik okruhu slova ženščiny a tvarového souboru slova ženščina není prázdná množina. Slovo ženščina patří ovšem také do třídy slova ženščina. Patří tedy toto slovo do dvou různých tříd.
Poslední v řadě definovaných gramatických kategorií jsou typy. Tak jako z Bjed-rozkladu jsme získali sjednocením všech jeho Bjed-ekvivalentních prvků odvozený rozklad, rozklad na tvarové soubory, rozklad na typy je získán obdobně z rozkladu Bk, rozkladu na třídy.
Rozklad na typy, který značíme Bt. je definován takto: Každý prvek Bt-rozkladu se rovná sjednocení všech Bk-ekvivalentních prvků Bk-rozkladu. V rozkladu na typy slučujeme již tedy např. podstatná jména všech rodů do jednoho typu.
Doposud byly sjednocovány prvky rozkladů slovníku do množin obdobných gramatickým kategoriím, do tvarových souborů, tříd a typů. V další části jsou zkoumány gramatické vztahy mezi slovními tvary ve větě. Klíčovým pojmem tu je pojem konfigurace.
Mějme nějaký rozklad B slovníku a strukturu dané věty A vzhledem k tomuto rozkladu, její B-strukturu. B-konfigurací prvého řádu — označíme si ji B̃(1) — je taková B-struktura, která má alespoň dva prvky a ke které existuje prvek — označíme si jej Bα(1) — takový, že B-struktura B(A1) B̃(1) B(A2) dané věty A je správná tehdy a jen tehdy, je-li B-struktura B(A1) Bα(1) B(A2) správná, ať jsou věty A1, A2 jakékoli; přitom A1 nebo A2 nebo obě tyto věty mohou být i prázdnými posloupnostmi slov. Prvek Bα(1), kterým je možno na[39]hradit B-konfiguraci prvního řádu, aniž se nám změní správná B-struktura v nesprávnou nebo naopak, nazývá se výsledným prvkem.
Abychom mohli zavésti konfigurace druhého řádu, budeme nejprve definovat B-strukturu prvého řádu. Je to taková B-struktura, která neobsahuje B-konfigurace prvého řádu. V B-struktuře prvého řádu můžeme obdobně hledat konfigurace, tzv. B-konfigurace druhého řádu, B̃(2). B-strukturou druhého řádu rozumíme takovou B-strukturu, v které se neobjevuje žádná B-konfigurace druhého řádu. Tak bychom mohli pokračovat až ke konfiguraci k-tého řádu a k B-struktuře k-tého řádu.
Mějme nějaký slovník a jeho rozklad na typy:
A = je velmi starý muž
Bt(A) = množina sloves, množina příslovcí, množina přídavných jmen, množina podstatných jmen
Konfigurací prvého řádu B̃t(1) je množina příslovcí + množina přídavných jmen. Jejím výsledným prvkem Btα(1) je množina přídavných jmen. Po nahrazení B̃t(1) pomocí Btα(1) dostaneme Bt-strukturu prvého řádu. V Bt-struktuře získané věty už není B̃t(1), je tedy strukturou prvého řádu a můžeme v ní hledat B̃t(2). V našem příkladě jí bude množina přídavných jmen + množina podstatných jmen s výsledným prvkem: množina podstatných jmen.
Uveďme si ještě v přehledu struktury našeho příkladu:
A = je velmi starý muž
Bt(A) = množina sloves, množina příslovcí, množina příd. jmen, množina podst. jmen
![]()
konfigurace prvého řádu, B̃t(1)
A' = je starý muž
Bt(A') = množina sloves, množina přídavných jmen, množina podst. jmen
![]()
konfigurace druhého řádu, B̃t(2)
(A'') = je muž
Bt(A'') = množina sloves, množina podstatných jmen
V dalším výkladu bere autorka v úvahu dva rozklady B a D slovníku, při čemž rozklad B je zhrubením rozkladu D. Schematický příklad:
slovník = {a, b, c, d, e, f, g, h, i}
D = {{a, b}, {c, d}, {e, f}, {g, h}, {i, j}}
stručně: { X , Y , Z , U , V }
B = {{a, b, c, d}, {e, f, g, h, i, j}}
stručně: { A , B }
Jestliže se některá D-konfigurace zobrazuje[12] do B-konfigurace a její výsledný prvek se zobrazuje do výsledného prvku B-konfigurace, nazývá se D-konfigurace podřazenou dané B-konfiguraci a B-konfigurace nadřazenou dané D-konfiguraci.
[40]Kulaginová rozlišuje tři druhy vztahů, v kterých může býti B ku A vzhledem k rozkladu D. Bez újmy obecnosti uvedeme tři schematické příklady.
I. Předpokládejme, že A, B je B-konfigurací a všechny D-konfigurace, které jsou dané B-konfiguraci podřazeny, jsou: X,Z ; X,U ; X,V ; Y,X ; Y,U ; Y,V. Nyní si rozdělíme všechny D-konfigurace na skupiny: do jedné skupiny budou patřit všechny D-konfigurace, v kterých stojí na prvém místě jeden a týž prvek. Máme tedy v našem příkladě dvě skupiny:
X,Z ; X,U ; X,V ;
Y,Z ; Y,U ; Y,V .
Pro každou skupinu platí, že na druhém místě stojí všechny prvky zobrazené do B. V takovém případě Kulaginová říká, že B je ku A ve vztahu třetího druhu vzhledem k rozkladu D. Takovýto vztah představuje úplnou gramatickou nezávislost B na A vzhledem k rozkladu D.
II. Nyní předpokládejme, že všechny D-konfigurace, které jsou dané B-konfiguraci podřazeny, jsou:
X,Z ; X,U ;
Y,Z ; Y,V .
Tvoří obdobně opět dvě skupiny. Pro každou skupinu platí, že na druhém místě stojí více než jeden prvek zobrazený do B, ale ne všechny. Pokud rozumíme dobře autorčinu výkladu, v takovémto případě je B ku A ve vztahu druhého druhu vzhledem k rozkladu D. Tento vztah představuje částečnou gramatickou závislost B na A vzhledem k rozkladu D.
III. Nyní předpokládejme, že všechny D-konfigurace podřazené B-konfiguraci A, B jsou: X,Z ; Y,V. Pro každou skupinu platí, že na druhém místě stojí jeden a týž prvek zobrazený do B. V takovémto případě je B ku A ve vztahu prvého druhu vzhledem k rozkladu D. Tento vztah představuje jednoznačnou gramatickou závislost B na A vzhledem k rozkladu D.
Na příkladě z češtiny si objasníme ještě vztah třetího, druhého a prvého druhu. Příklad vztahu třetího druhu:
slovník = {velmi, silně, starý, jarní, stará, jarní, staré, jarní}
D-rozklad
na tvarové
soubory = {{velmi, silně}, {starý, jarní}, {stará, jarní}, {staré, jarní}}
stručně: { X , Y , Z , U }
B-rozklad
na typy = {{velmi, silně}, {starý, jarní, stará, jarní, staré, jarní}}
stručně: { A , B }
Předpokládejme, že A, B je B-konfigurací a všechny D-konfigurace, které jsou podřazené B-konfiguraci A, B, jsou:
{velmi, silně}, {starý, jarní}
X , Y
{velmi, silně}, {stará, jarní}
X , Z
{velmi, silně}, {staré, jarní}
X , U
Pro tuto skupinu platí, že na druhém místě stojí všechny tvarové soubory přídavných jmen zobrazené do typu přídavných jmen. V takovém případě je typ přídavných jmen ve vztahu třetího druhu k typu příslovcí vzhledem k rozkladu na tvarové soubory.
Příklad vztahu druhého druhu:
slovník = {vidím, zdravím, ženu, květinu, muže, chlapce, mužům, chlapcům}
D-rozklad
na tvarové
soubory = {{vidím, zdravím}, {ženu, květinu}, {muže, chlapce}, {mužům, chlapcům}}
stručně: { X , Y , Z , U }
B-rozklad
na typy = {{vidím, zdravím}, {ženu, květinu, muže, chlapce, mužům, chlapcům}}
stručně: { A , B }
[41]Předpokládejme, že všechny D-konfigurace, které jsou podřazené B-konfiguraci A, B, jsou:
{vidím, zdravím}, {ženu, květinu}
X , Y
{vidím, zdravím}, {muže, chlapce}
X , Z
Pro tuto skupinu platí, že na druhém místě stojí vždy více než jeden tvarový soubor podstatných jmen zobrazený do typu podstatných jmen, ale ne všechny. V takovém případě je typ podstatných jmen ve vztahu druhého druhu k typu sloves vzhledem k rozkladu na tvarové soubory.
Příklad vztahu prvého druhu:
slovník = {milá, prostá, milý, prostý, žena, květina, muž, chlapec}
D-rozklad
na tvarové
soubory = {{milá, prostá}, {milý, prostý}, {žena, květina}, {muž, chlapec}}
stručně: { X , Y , Z , U }
B-rozklad
na typy = {{milá, prostá, milý, prostý}, {žena, květina, muž, chlapec}}
stručně: { A , B }
Předpokládejme, že všechny D-konfigurace, které jsou dané B-konfiguraci A, B podřazené, jsou:
{prostá, milá}, {žena, květina}
X , Z
{prostý, milý}, {muž, chlapec}
Y , U
Pro každou z těchto skupin platí, že na druhém místě stojí vždy jediný tvarový soubor podstatných jmen zobrazený do typu podstatných jmen. V takovém případě je typ podstatných jmen ve vztahu prvého druhu k typu přídavných jmen vzhledem k rozkladu na tvarové soubory.
[1] Sborník Problemy kibernetiky vydaný za radakce A. A. Ljapunova, Gosizdat., Moskva 1958.
[2] Množinou se rozumí soubor nějakých předmětů (v nejširším smyslu tohoto slova), které se nazývají prvky této množiny. Množinu lze vymezit buď vyjmenováním všech jejích prvků, nebo uvedením vlastnosti, kterou mají všechny její prvky a jenom její prvky. Množina, která obsahuje aspoň jeden prvek, nazývá se neprázdnou, množina, která neobsahuje ani jeden prvek, se nazývá prázdnou. Např. množina všech českých měst, které měly v r. 1958 více než dva milióny obyvatel, je množina prázdná. Množina obsahující konečný počet prvků nazývá se konečnou. Množina, která obsahuje dosti malý počet prvků, např. jen prvky a, b, c, značí se závorkami takto: {a, b, c}. Průnikem (součinem, společnou částí) dvou množin X, Y se nazývá množina obsahující ty a jen ty prvky, které patří zároveň do množiny X i do množiny Y. Sjednocením (součtem) dvou množin X, Y se nazývá množina obsahující ty a a jen ty prvky, které patří buď do množiny X, nebo do množiny Y nebo do obou zároveň. Máme-li např. množiny X = {a, b, c}, Y = {a, c, d, e, f}, pak je průnik množin X, Y = {a, c} sjednocení množin X, Y = {a, b, c, d, e, f}.
Dvě množiny Z, U jsou vzájemně rovné, skládají-li se z týchž prvků. Např. množina Z = {b, a, c} je rovna množině X, to píšeme: Z = X. Množina V se nazývá podmnožinou množiny W tehdy a jen tehdy, když neexistuje prvek množiny V, který by nebyl prvkem množiny W. Máme např. množinu V = {a, e}. Tato množina je podmnožinou množiny Y. Také množina X je podmnožinou množiny Z a naopak. Prázdná množina je ovšem podmnožinou každé množiny.
[3] Termínu „slovo“ užívá Kulaginová ve významu Smirnického „slovoformy“ (slovní tvar).
[4] Posloupností rozumíme množinu, v které je každému prvku určeno místo v pořadí prvků (prvý, druhý atd.). Často (nikoli však v článku O. S. Kulaginové a v našem textu) se posloupnosti značí závorkami ⟨ ⟩. Např. ⟨a, b, c⟩ je posloupnost obsahující prvky a, b, c v pořadí: a na prvém místě, b na druhém, c na třetím. Zatímco {a, b, c} a {b, a, c} jsou dvě množiny vzájemně rovné, ⟨a, b, c⟩ a ⟨b, a, c⟩ jsou dvě různé posloupnosti. Posloupnost, která neobsahuje žádný prvek, nazýváme prázdnou. Posloupnost, která obsahuje konečný počet prvků, nazýváme konečnou.
[5] Autorka v závěru své práce podotýká, že „vyznačenou větou“ rozumí větu gramaticky správnou bez zřetele k tomu, zda má smysl.
[6] Množina, jejímiž prvky jsou množiny, nazývá se množinou množin nebo systémem množin. Množinu, jejímiž prvky jsou např. množiny {a, b}, {a, c}, značíme {{a, b}, {a, c}}. — Dvě množiny se nazývají disjunktními tehdy a jen tehdy, když jejich průnik je prázdná množina, čili, když žádný prvek nepatří do obou zároveň. Např. množiny {a, b}, {a, c} nejsou disjunktní, množiny {a, b}, {c} jsou disjunktní.
[7] V závěru autorka uvádí, že „okruhem daného slova“ rozumí množinu jeho gramatických tvarů (soubor tvarů téhož slova).
[8] Rozkladem dané množiny X je množina, jejímiž prvky jsou neprázdné podmnožiny množiny X, přičemž jsou každé dvě tyto podmnožiny vzájemně disjunktní (žádný prvek nepatří do dvou těchto podmnožin zároveň) a sjednocení všech těchto podmnožin je rovno množině X. Máme např. množinu {a, b, c, d}. Rozklady této množiny jsou
B1 = {{a, b}, {c, d}}
B2 = {{a, b}, {c}, {d}}
B3 = {{a}, {b}, {c}, {d}}
B4 = {{a, b, c, d}} aj. Celkem existuje patnáct možných rozkladů uvedené množiny X.
[9] Jednotkový rozklad množiny je takový její rozklad, jehož prvky jsou toliko množiny obsahující jediný prvek. Např. jednotkovým rozkladem výše uvedené množiny X je rozklad B3.
[10] Jestliže každý prvek rozkladu Bi je podmnožinou nějakého prvku rozkladu Bj a přitom aspoň jeden prvek rozkladu Bj je sjednocením dvou nebo více prvků rozkladu Bi, pak se rozklad Bj nazývá zákrytem, zhrubením rozkladu Bi a rozklad Bi se nazývá zjemněním rozkladu Bj. Např. rozklady B1, B2, B4 jsou zhrubení výše uvedeného rozkladu B3. Rozklad B4 je zhrubením rozkladu B1.
[11] Třídami se rozumějí jednak slovní druhy (substantiva atd.), jednak oblasti užší (např. substantiva ženského rodu apod.).
[12] Mějme nějakou D-konfiguraci a nějakou B-konfiguraci; rozklad B nechť přitom je zhrubením rozkladu D. Jestliže je prvý prvek D-konfigurace podmnožinou prvého prvku B-konfigurace, druhý prvek D-konfigurace podmnožinou druhého prvku B-konfigurace atd., pak budeme říkat, že se tato D-konfigurace zobrazuje do této B-konfigurace. Jestliže přitom je prvek X D-konfigurace podmnožinou prvku Y B-konfigurace, budeme říkat, že se prvek X zobrazuje do prvku Y. Je-li např. posloupnost {a, b}, {g, h} D-konfigurací a posloupnost {a, b, c, d}, {e, f, g, h, i, j} B-konfigurací, pak říkáme, že se uvedená D-konfigurace zobrazuje do uvedené B-konfigurace, a říkáme také, že se prvek {a, b} zobrazuje do prvku {a, b, c, d}.
Slovo a slovesnost, ročník 21 (1960), číslo 1, s. 34-41
Předchozí Dana Konečná: Poznámky k významům „izolovaných“ pádů v současné spisovné češtině
Následující Vladimír Skalička: Z nové typologické literatury
© 2011 – HTML 4.01 – CSS 2.1