
Příspěvek k aplikaci některých sociolingvistických metod na výzkum výslovnosti slov přejatých
Růžena Buchtelová
[Rozhledy]
О применении некоторых социолингвистических методов к изучению произношения заимствованных слов / Contribution à l’application de certaines méthodes sociolinguistiques à la recherche de la prononciation des mots d’emprunt
Práce na současné spisovné výslovnosti slov přejatých ukázaly, že značná část slovního materiálu, který měla Ortoepická komise Ústavu pro jazyk český (dále OK) k dispozici, zhruba jeho 40 %, více nebo méně ve výslovnosti kolísají.[1] Vzhledem k značné rozkolísanosti a nepravidelnosti výslovnosti přejatých slov v češtině pokládala OK za vhodné neřešit výslovnost každého slova izolovaně, nýbrž rozhodovat souhrnně o výslovnosti celých skupin podobných typů předpon nebo přípon. Tyto typy reprezentovaly vyslovnostní problémy obsažené v základním materiálu. Podrobnější zkoumání ukázalo, že daleko více kolísají produktivnější typy přípon, než je tomu u typů méně produktivních. Bylo tedy nutno vyřešit otázku, jakým způsobem má být zjišťován současný stav výslovnosti jednotlivých typů přípon a předpon. Během práce na připravovaném výslovnostním slovníku slov přejatých se podařilo vybudovat širokou síť odborných i vědeckých pracovníků z nejrůznějších oborů, na které se OK průběžně obracela s dotazy o výslovnosti jednotlivých slov patřících k terminologii jejich oboru. Tento způsob však neobrážel v dostatečné míře skutečný postoj naší odborné veřejnosti k současné ortoepické normě přejatých slov a rovněž platnost takto získaných údajů byla příliš omezená, což vyplynulo ze srovnání výpovědí respondentů se záznamy zachycujícími jejich skutečnou výslovnost.[2]
Vzhledem k značné rozsáhlosti materiálu, který celý nelze podrobit šetření, byl přijat v OK plán, aby byl objektivními sociolingvistickými metodami zjištěn skutečný postoj uživatelů jazyka k některým návrhům kodifikace výslovnostní normy slov přejatých, tj. jak uživatelé hodnotí různé typy odchylek od platné kodifikace, a to zejména v stylově neutrálních mluvených projevech. Výsledky tohoto šetření mají [46]poskytnout jeden z podkladů pro další práci OK jak při posuzování jednotlivých návrhů na rozsah úprav výslovnosti slov přejatých, tak i při zpracování normativní příručky určené pro širokou veřejnost.
V prvé etapě práce šlo o vypracování pracovních postupů a o ověření celkové koncepce výzkumu. Proto bylo šetření zaměřeno na úzký soubor respondentů, který tvořili převážně aktivní uživatelé spisovného jazyka v jeho mluvené podobě. U těchto uživatelů bylo rovněž možno předpokládat vyhraněnější názory na spisovnou výslovnost než u uživatelů, jejichž vztah k spisovnému jazyku je spíše pasívní (viz typologie respondentů sondy II).
Účelem tohoto šetření bylo zjistit postoj uživatelů spisovného jazyka k alternativním návrhům OK na výslovnost některých výslovnostně problematických typů přípon slov přejatých (resp. k jejich odchylkám od spisovné výslovnosti). Šetření se týkalo kolísavé kvantity v slovech přejatých a výslovnostních dublet s, z, přičemž kritériem k posouzení správnosti výslovnosti byl návrh kodifikace výslovnostní normy slov přejatých, který zpracovala OK.
Experimentální data byla získána ze dvou dílčích sond (dále sonda I a sonda II). Při jejich vyhodnocování bylo přikročeno k selektivnímu využití postupů a technik uváděných v pracích V. Lamsera, Č. Adamce a v sociolingvistické monografii W. Labova.[3]
Při hodnocení materiálu bylo nutno počítat se skutečností, že zejména v kolísání kvantity jde o odchylky od spisovné výslovnosti, které si veřejnost mnohem méně uvědomuje. Rovněž bylo nutno vzít v úvahu i zkreslení, které je dáno jazykovým povědomím posuzovatele, resp. posuzovatelů materiálu.
Sonda I
Sonda I byla zaměřena na zjišťování korelace mezi ideační výslovností respondent I (představa respondenta o vlastní výslovnosti — sebehodnocení), jeho proklamovanou výslovností P (názor na to, jaká výslovnost je kodifikačně správná) a reálnou výslovností R (objektivní vyhodnocení respondentovy výslovnosti posuzovatelem).
Šetřený materiál tvořily záznamy přednášek proslovených v Čs. rozhlase. Vzhledem k různému zaměření přednášek byl získaný materiál nejednotný a nemohl být tudíž vnitřně příliš diferencován. Proto byl učiněn pokus navázat s přednášejícími kontakt ve formě ústního ověřování. Z celkového počtu 35 osob přednášejících v rozhlasových relací Věda a technika mládeži a Meteor se podařilo získat ke spolupráci 12 osob. Skupinu respondentů v sondě I představoval tedy malý soubor 6 vědeckých pracovníků lékařů (dále soubor A) a 6 specializovaných inženýrů (dále soubor B). Respondenti náleželi z hlediska vzdělání do 4. kategorie (ukončené vysokoškolské vzdělání) a podle věku do 3. kategorie, tj. nad 45 let (viz typologie výběrového souboru respondentů sondy II).
Šetření se týkalo korelativního protikladu [o o:], [e e:], [i i:]; (příklad hygiena, tyfus, telefon, anoda).[4]
Šetření probíhalo podle následujícího schématu: (1) volba typů slov a okruhu [47]respondentů; (2) sebehodnocení a proklamované hodnocení respondenta (systém otázek a odpovědí); (3) verifikace sebehodnocení magnetofonovou nahrávkou respondenta; (4) vyhodnocení nahrávky posuzovatelem.[5]
| Symbol | Soubor | Otázka | Odpověď |
| I0 | A, B | Snažíte se vyslovovat přejatá slova pečlivěji než slova domácí? | ano ne nevím |
|
I1 |
A |
Jak vyslovujete slovo hygiena?
| krátce dlouze nevím |
| I2 | A | Jak vyslovujete slovo tyfus? | |
| I3 | B | Jak vyslovujete slovo telefon? | |
| I4 | B | Jak vyslovujete slovo anoda? | |
| P1 | A | Jaká je podle vašeho názoru správná výslovnost slova hygiena? | |
| P2 | A | Jaká je podle vašeho názoru správná výslovnost slova tyfus? | |
| P3 | B | Jaká je podle vašeho názoru správná výslovnost slova telefon? | |
| P4 | B | Jaká je podle vašeho názoru správná výslovnost slova anoda? |
Tab. 1. Ideační a proklamovaná výslovnost respondenta
Při šetření bylo použito techniky zavřených otázek, položených na tříbodové stupnici s neutrální variantou — krátce, dlouze, nevím — a vzhledem k malému souboru získaných dat nebylo možno jeho výsledky hodnotit jinak než tabelárně. Výsledkem [48]byla míra neshody mezi třemi sledovanými faktory (I, P, R); šlo tedy o zjištění jazykové jistoty respondenta. Po úvodní všeobecné otázce (I0) se další otázky (I1—I4, P1—P4) vztahovaly na výslovnost jednotlivých typů slov podle odborného zaměření respondentů.
Sledovány byly následující typy slov: hygiena, tyfus (u souboru A), telefon, anoda (u souboru B). Získaná experimentální data byla vyhodnocována jediným posuzovatelem, kterým byla autorka tohoto příspěvku. Výsledkem bylo hodnocení reálné výslovnosti respondenta (R1—R4).
Systematiku otázek a odpovědí (ideační výslovnost, proklamovaná výslovnost a hodnocení reálné výslovnosti ověřovaných typů slov) podávají tab. 1 a 2.
Tab. 1 (s. 47) znázorňuje v zjednodušené přehledné formě techniku dotazů a možnosti odpovědí. Způsob kladení otázek dává podklad pro vyhodnocení ideační a proklamované výslovnosti respondenta.
V tab. 2 je přehledně znázorněna možná výslovnost 4 vybraných typů slov, totožných s typy v tab. 1. Tab. 2 slouží ke korelaci dat získaných technikou otázek a odpovědí podle systematiky tab. 1. Výsledky, které jsou reálnou výslovností respondenta, představují verifikaci jeho ideační a proklamované výslovnosti magnetofonovou nahrávkou na typech slov identických s tab. 1.
| Symbol | Soubor | Verifikovaný typ slova | Hodnocení |
| R1 | A | hygiena |
krátce dlouze obojí |
| R2 | A | tyfus | |
| R3 | B | telefon | |
| R4 | B | anoda |
Tab. 2. Reálná výslovnost respondenta
Vhodnost systematiky hodnocení ideační, proklamované a reálné výslovnosti, jak je navržena v tab. 1 a 2, byla ověřena na uvedeném dvanáctičlenném souboru respondentů. V následujících tab. 3—7 se vedle symbolů uvedených v tab. 1 a 2 užívá následujících symbolů a indexů: A respondent lékař; B respondent technik-inženýr; + ano; — ne; 0 nevím; / dlouze; ⋃ krátce; ⋃ / obojí.
| Respondent | A1 | A2 | A3 | A4 | A5 | A6 | B1 | B2 | B3 | B4 | B5 | B6 |
| Odpověď na otázku I0 |
+ |
— |
— |
— |
+ |
0 |
— |
— |
— |
0 |
— |
— |
Tab. 3. Ideační výslovnost slov přejatých respondentů souboru A i B
[49]V tab. 3 (s. 48) je zachycena ideační výslovnost slov přejatých ve srovnání se slovy domácími u respondentů souboru A i B.
Tab. 4—7 jsou příkladem korelace ideační, proklamované a reálné výslovnosti čtyř vybraných typů slov u jednotlivých respondentů. Ideační a proklamovaná výslovnost každého z vybraných typů slov je verifikována jeho reálnou výslovností a výsledek je přehledně shrnut v samostatné tabulce.
| Respondent | A1 | A2 | A3 | A4 | A5 | A6 |
| Odpověď na otázku I1 | ⋃ | ⋃ | ⋃ | / | ⋃ | ⋃ |
| Odpověď na otázku P1 | ⋃ | ⋃ | ⋃ | ⋃ | / | 0 |
| Verifikovaný typ slova R1 | / | / | ⋃ / | ⋃ | / | ⋃ |
Tab. 4. Korelace ideační, proklamované a reálné výslovnosti slova hygiena
| Respondent | A1 | A2 | A3 | A4 | A5 | A6 |
| Odpověď na otázku I2 | ⋃ | ⋃ | ⋃ | ⋃ / | ⋃ | ⋃ |
| Odpověď na otázku P2 | ⋃ | / | ⋃ | ⋃ | ⋃ | ⋃ |
| Verifikovaný typ slova R2 | / | ⋃ | ⋃ / | / | ⋃ | ⋃ |
Tab. 5. Korelace ideační, proklamované a reálné výslovnosti slova tyfus
| Respondent | B1 | B2 | B3 | B4 | B5 | B6 |
| Odpověď na otázku I3 | ⋃ | ⋃ | ⋃ | ⋃ | ⋃ | ⋃ |
| Odpověď na otázku P3 | ⋃ | ⋃ | ⋃ | ⋃ | / | ⋃ |
| Verifikovaný typ slova R3 | ⋃ | ⋃ | ⋃ / | ⋃ / | ⋃ | ⋃ |
Tab. 6. Korelace ideační, proklamované a reálné výslovnosti slova telefon
| [50]Respondent | B1 | B2 | B3 | B4 | B5 | B6 |
| Odpověď na otázku I4 | ⋃ | ⋃ | ⋃ | ⋃ | 0 | ⋃ |
| Odpověď na otázku P4 | ⋃ | ⋃ | ⋃ | ⋃ | 0 | ⋃ |
| Verifikovaný typ slova R4 | ⋃ | ⋃ | ⋃ | ⋃ | ⋃ / | ⋃ / |
Tab. 7. Korelace ideační, proklamované a reálné výslovnosti slova anoda
Z tab. 4 a 5 vyplývá, že u většiny respondentů souboru A se projevuje rozpor mezi sebehodnocením (ideační výslovností) a její verifikací posuzovatelem (reálnou výslovností). U souboru B (tab. 6 a 7) je soulad mezi sebehodnocením a reálnou výslovností výrazně častější, přesto však existuje určité rozpětí mezi předpokládanou realizací výslovnostního typu a jeho realizací opravdovou. Proti těmto zřejmým větším nebo menším rozporům mezi výslovností ideační a reálnou lze z tab. 4—7 usoudit na poměrně dobrý soulad mezi proklamovanou a ideační výslovností respondentů souboru A i B.
Z tabelovaných experimentálních dat nejsou vzhledem k nereprezentativnosti sledovaného souboru respondentů, který je dán metodickým charakterem práce, vyvozovány definitivní závěry. Lze pouze předpokládat, že u respondentů s technickým vzděláním se vyskytuje větší sklon k normativní výslovnosti slov přejatých než u respondentů se vzděláním humanitním. Přes malou četnost souboru se ukazuje, že zvolený systém může dát v korelaci sebehodnocení a hodnocení respondenta jeden z podkladů pro návrh výslovnostní normy slov přejatých.
Sonda II
Sonda II byla zaměřena na zjišťování schopnosti aktivního užívání slov přejatých u jednotlivých respondentů. Cílem šetření bylo zjistit, za jakých okolností dochází u respondentů k odchylkám od spisovné výslovnosti u slov přejatých. Na rozdíl od sondy I šlo v tomto případě pouze o zjištění výslovnosti reálné. Šetření měla být opět podrobena výslovnost některých typů přípon (resp. zakončení) slov přejatých. Vedle typů zakončení -fon, -ena, -oda, která byla sledována v obou sondách, aby byla dána možnost pro korelaci obou experimentů, byla dále podrobena šetření zakončení -log, -logie, -on, -omie, -iéra (reprezentovaná typy slov filolog, archeolog, balkón, ekonomie, galantérie, garsoniéra apod.). Z těchto slov byl sestaven zkušební text tak, aby zakončení zvláště výslovnostně problematická byla zastoupena několika případy, popř. i ve svých derivacích. Dále byly podrobeny šetření výslovnostní dublety s, z (reprezentované typy slov renesance, režisér).
Ukázka zkušebního textu:
Na Ostravsku se vyskytl tyfus. Původcem střevní epidemie a tyfu je nedostatečná hygiena v některých provozovnách hromadného stravování.
Vyměním 2 + 1 v novostavbě s balkónem za 1 + 1 a garsoniéru.
V poslední době u nás stále klesá spotřeba mléka, zvláště mezi školní mládeží.
Nedělní pořad S mikrofonem za sportem začíná ve 14 hod. na Praze 1.
7. mezinárodního kongresu archeologů se zúčastnilo na 2000 odborníků z celého světa.
Poplatky za telefon budou vybírány tuto sobotu v době od 14 do 16 hod.
[51]V rámci této sondy byly požádány o spolupráci katedry českého jazyka na filosofických fakultách a pedagogických institutech v českých zemích. Šetření bylo zorganizováno tak, že na každou katedru českého jazyka byl zaslán zkušební text spolu s rámcovými pokyny a s prosbou, aby text byl dán k přečtení bez přípravy skupině 10—15 studentů a vědeckých pracovníků různého věku, pohlaví a vědního zaměření. Projevy měly být zachycovány na magnetofonový pásek. U každého respondenta měla být vedle jeho osobních údajů (data narození, bydliště, vzdělání, i neukončené) připojena i osobní data rodičů. Celkem se podařilo získat materiál od 81 respondentů. Experimentální data byla hodnocena skupinou 5 posuzovatelů (4 posluchači FFUK, 1 matematik). Hodnocení větším počtem posuzovatelů vedlo nutně k určitému rozptylu hodnot, který však vzhledem k metodickému charakteru práce nebyl brán v úvahu. Při stanovení „skutečného stavu výslovnosti“ bylo použito prostého většinového principu, tzn. pro každý jednotlivý případ byl určující názor většiny ze skupiny posuzovatelů.[6]
Typologie respondentů
Z typologického hlediska byli respondenti diferencováni podle následujících objektivních diferenciačních faktorů: (1) pohlaví, (2) věk, (3) vzdělání.
Podle věku byli respondenti v zájmu zjednodušení a malé početnosti souboru diferencováni pouze do tří kategorií: skupina (1) od 20—29 let, (2) od 30—45 let, (3) nad 45 let.
Dále byli respondenti diferencováni do 4 kategorií podle vzdělání, přičemž se rozlišovalo: (1) základní vzdělání (předpokládá se občasný pasívní styk se spis. jazykem); (2) středoškolské vzdělání (pravidelný pasívní styk se spis. jazykem); (3) neukončené vysokoškolské vzdělání (aktivní styk se spis. jazykem); (4) ukončené vysokoškolské vzdělání (aktivní styk se spis. jazykem).
Z hlediska sociálního zařazení tvořili respondenti malé typově ucelené soubory (administrativní a techničtí pracovníci, studenti, vysokoškolští asistenti, vědečtí pracovníci v různých oborech). Výjimku představovala malá skupina respondentů se základním vzděláním.
Hodnocení materiálu
| Respondent | Odchylky od spisovné výslovnosti | |||
| Pohlaví | n | % | n̄ | průměrné % |
| Muži | 30 | 37,03 | 6,80 | 12,36 |
| Ženy | 51 | 62,97 | 6,61 | 12,02 |
| Σ | 81 | 100,00 |
|
|
Tab. 8. Závislost výslovnosti slov přejatých na pohlaví respondentů
[52]Experimentální data získaná ze sondy II byla vyhodnocována vzhledem k návrhu kodifikace výslovnostní normy slov přejatých, jak jej zpracovala OK. Odchylky od spisovné výslovnosti byly posuzovány v souvislosti s pohlavím, věkem a vzděláním.
Vzhledem k nestejnému počtu respondentů v jednotlivých kategoriích, což do jisté míry ovlivnilo výsledky hodnocení, nebylo možno podrobněji se zabývat tím, které jevy (resp. odchylky) se realizují jednotně ve všech kategoriích. Bude nutno zabývat
| Respondent | Odchylky od spisovné výslovnosti | |||
| Věk | n | % | n̅ | průměrné % |
| 20—30 | 56 | 69,13 | 6,51 | 17,59 |
| 30—45 | 19 | 23,46 | 6,20 | 16,76 |
| nad 45 | 6 | 7,41 | 9,43 | 25,49 |
| Σ | 81 | 100,00 |
|
|
Tab. 9. Závislost výslovnosti slov přejatých na věkové struktuře respondentů
se touto problematikou při dalším šetření s reprezentativnějším počtem respondentů.
Rozvrstvení respondentů sondy II podle pohlaví ilustruje tab. 8. Výsledky naznačují, že vliv pohlaví na počet odchylek od spisovné výslovnosti je zanedbatelný.
| Respondent | Odchylky od spisovné výslovnosti | ||||
| Vzdělání | stupeň | n | % | n̄ | průměrné % |
| typ | |||||
| základní | 1 | 3 | 3,71 | 14,67 | 39,65 |
| střední | 2 | 14 | 17,28 | 7,14 | 19,30 |
| neukončené vysokoškolské | 3 | 51 | 62,96 | 6,43 | 17,38 |
| ukončené vysokoškolské | 4 | 13 | 16,05 | 5,31 | 14,35 |
| Σ | 81 | 100,00 |
|
| |
Tab. 10. Závislost výslovnosti slov přejatých na stupni vzdělání respondentů
[53]Závislost výslovnosti slov přejatých na věkové struktuře respondentů (viz tab. 9) ukazuje prudký vzestup počtu odchylek v nejvyšší věkové skupině nad 45 let. Obě skupiny 20—29 let a 30—45 let vykazují vcelku shodné výsledky. Nestejný počet respondentů v jednotlivých kategoriích však snižuje hodnotu výsledků.
Výsledky šetření počtu odchylek od spisovné výslovnosti v závislosti na stupni vzdělání uvádí tab. 10. Je z ní patrna tendence, že se snižuje počet odchylek ve vztahu k vzdělání u stupňů 2, 3 a 4. Mezi respondenty se základním vzděláním (stupeň 1) a ostatními respondenty (stupně 2, 3 a 4) se projevuje výrazný zlom. Nízký počet respondentů se základním vzděláním však snižuje význam těchto výsledků.
Výsledky uvedené v tab. 8, 9 a 10 shrnuje graf uvádějící detailní distribuci odchylek od spisovné výslovnosti podle stupně vzdělání, věku a pohlaví. Graf zachycuje zvláštním symbolem pozici každého respondenta v hodnotovém poli, vytvářeném třemi diferenciačními faktory. Koncentrace respondentů kolem určitých hodnot po-
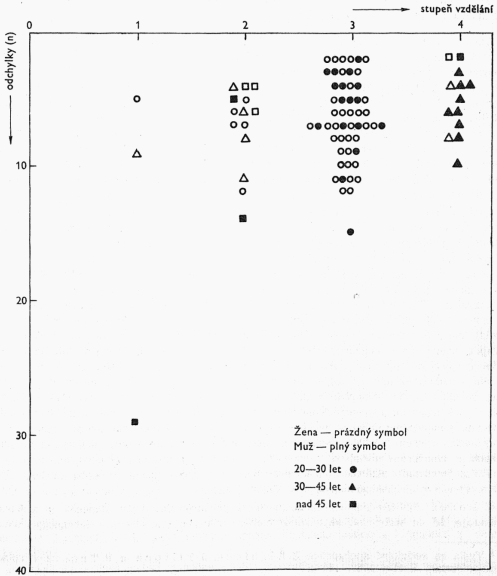
[54]dává názornou syntetizující informaci. Skutečně reprezentativní je však z hlediska vzdělání pouze kategorie 3, která vzhledem ke své početnosti umožňuje z hlediska statistiky oprávněnou eliminaci okrajových hodnot (jevů). Naproti tomu v kategorii 1 i při velkém rozptylu je jakákoli eliminace nemožná. — Vzhledem k celkově malému počtu respondentů má graf pouze orientační charakter.
Závěr: Obě sondy představují nereprezentativní vzorek, který byl předem vědomě limitován relativně nízkou četností souboru a tím i nízkými četnostmi v sledovaných diferenciačních kategoriích. Tomu odpovídá i přístup k dosaženým výsledkům, který není meritorní, ale metodologický.
[1] Viz zprávu R. Buchtelové K činnosti subkomise pro slova přejatá při Ortoepické komisi ÚJČ, Jazykovědné aktuality II, 1966, s. 41—44.
[2] Na skutečnost, že svědectví odborných pracovníků týkající se jejich vlastní terminologie není vždy rozhodující, upozorňuje M. Romportl, Práce na pravidlech výslovnosti spisovné češtiny, NŘ 47, 1964, 163—167. — Do této stati byly pojaty některé terminologické připomínky J. Krause, obsažené v jeho posudku mého výzkumu.
[3] V. Lamser, Základy sociologického výzkumu, Praha 1966; Č. Adamec, Výběrové průzkumy zdravotního uvědomění I, II, Ústav zdravotního výzkumu, Praha 1967; W. Labov, The Social Stratification of English in New York City, Washington 1966; srov. rec. v SaS 29, 1968, 197—203.
[4] Volba příkladů byla dána požadavkem OK podrobit šetření nejvíce rozkolísané typy zakončení (zejm. -ena, -fon, -oda). Ty pak reprezentují uvedené příklady, které jsou dále nazývány typy slov. Jejich výběr byl dán zřetelem frekvenčním (jde o slova v určitém okruhu uživatelů běžně používaná) a zřetelem pozičním (kolísající hláska byla v první, druhé, předposlední a poslední slabice).
[5] V celkovém schématu šetření je evidentně největší slabinou vyhodnocení nahrávky posuzovatelem (4). V další etapě práce se předpokládá exaktní elektroakustické hodnocení, čímž stoupne i platnost závěrů, což je významné především pro výzkum kvantity v slovech přejatých.
[6] U širšího reprezentativního souboru respondentů bude nutno zavést místo prostého většinového systému pomocný pravděpodobnostní koeficient jako kritérium jednotnosti názoru ve skupině posuzovatelů.
Slovo a slovesnost, ročník 32 (1971), číslo 1, s. 45-54
Předchozí Jiřina Novotná: Akustická analýza a syntéza řeči v Polsku
Následující Ivan Lutterer: O německo-českých vztazích v oblasti jazyka a kultury ve dvou německých sbornících
© 2011 – HTML 4.01 – CSS 2.1