
Zastoupení sémantických tříd v jednom románovém textu
Martin Friš
[Články]
The distribution of semantic classes in the text of a novel
1. Úvod
V tomto pojednání navážeme na zkoumání sémantických tříd, jak bylo provedeno v mém článku (Friš, 1992). Tam je sémantická třída vytvořena tak, že jsou do ní zařazena slova blízká svým významem. Zvláštním případem jsou slova synonymní, neboť ta jsou svým významem shodná. Jedná se o známý princip sémantických polí či též slovníku věcného a synonymického, jak ho máme v češtině (1969–1977), který vychází ze slovníku Halligova, Wartburgova (1963). V angličtině je na tomto principu založen populární klasický Roget Thesaurus (1968, poprvé publikováno 1852). Seznam zavedených sémantických tříd je uveden v tabulce č. 1. V našem rozdělení
Tab. č. 1. Sémantické třídy
| 01 | bytí, událost |
| 02 | vztah, seskupení |
| 03 | množství, číslo |
| 04 | řád, zákonitost |
| 05 | změna, příčina |
| 06 | čas, období |
| 07 | průběh času |
| 08 | prostor |
| 09 | tvar |
| 10 | pohyb |
| 11 | přenos, změna polohy |
| 12 | krajina, hmota |
| 13 | vlastnosti hmoty, smysly |
| 14 | živočich, biologická činnost |
| 15 | části organismu |
| 16 | práce, činnost |
| 17 | zemědělství, průmysl, doprava |
| 18 | obchod, majetek, dát |
| 19 | úřad, řízení, výchova |
| 20 | společnost, stát, skupina |
| 21 | boj, politika, armáda |
| 22 | vztahy mezi lidmi, morálka |
| 23 | rodina, láska, přátelství |
| 24 | město, obydlí, domácnost |
| 25 | oděv, jídlo, nemoc |
| 26 | zpráva, řeč, psaní |
| 27 | hledání, vyučování, pravda |
| 28 | myšlení, vědomost |
| 29 | věda, umění, náboženství |
| 30 | charakter, zážitek, zábava |
| 31 | nálada, dojmy, city |
| 32 | lidská situace |
| 100 | předložky |
| 101 | spojky |
| 102 | zájmena |
| 103–105 | neplnovýznamová příslovce |
| 106 | modální a pomocná slovesa |
| 107 | interpunkční znaky |
[106]slov do sémantických tříd jsme se ještě opřeli o další princip – frekvenční, a to tak, že slova jsme vybrali ze seznamu slov nejfrekventovanějších. Toto naše pojetí je blízké přístupu knihy V. A. Moskoviče (1969). V této knize je také kombinován princip sémantických polí s principem frekvenčním. Jako sémantické pole jsou tam vybrána slova označující barvy. Pozdější práce R. M. Frumkinové (1978) je kritickou analýzou gnoseologických a psychologických aspektů sémantického pole.
V mém článku z r. 1992 šlo o objektivizaci pojmu sémantická třída, i zde nám jde o další objektivizaci tohoto pojmu.
Za cenné připomínky děkuji profesorovi P. Sgallovi, dr. M. Těšitelové a dr. J. Nečasovi.
2. Sémantické třídy v textu beletrie
Budeme zjišťovat, jak jsou sémantické třídy zastoupeny v jednom textu z beletrie. Pokusíme se odpovědět na otázku, jakou část textu pokrývají slova nejfrekventovanější, a to první dva tisíce slov ze slovníku Jelínek – Bečka – Těšitelová (1961). Na základě tohoto zjištění budeme sledovat, jak jsou tato slova nejfrekventovanější rozložena do uvedených sémantických tříd.
Je zřejmé, že nejfrekventovanější slova (první dva tisíce) pokryjí jistou větší část textu. Ale nedá se předem stanovit ani odhadnout, kolik procent textu to bude činit, bude-li to například 30 či 70 procent textu.
Pro výpočet frekvence musíme stanovit jednotku populace, pojímáme-li text knihy jako statistický soubor. O různých přístupech k této otázce píše ve své monografii M. Těšitelová (1992). Tradiční je stanovit jednotku populace jako slovo (ohraničené dvěma mezerami). Zvolili jsme takový přístup, že kromě slova zahrnujeme jako jednotku populace i interpunkční znaky.
Vybrali jsme proto konkrétní text a ten jsme zpracovali tak, že jsme všechna slova převedli do základní podoby (lemmatizace): podstatná jména do 1. pádu jednotného čísla atp. Takto upravený text jsme pak zpracovali souborem programů, jehož jádro tvoří program, který k zadanému seznamu slov (slovníku) spočítá frekvence slov.
Z knihy V. Řezáče Rozhraní (1986, poprvé publikováno 1944) jsme zpracovali stránky 5 až 89. Tato část knihy obsahuje 30 000 slov či interpunkčních znaků (jednotek populace). Teprve výpočtem pro tento konkrétní text beletrie jsme zjistili, že zde pokrytí textu slovy nejfrekventovanějšími činí 77 procent.
Sémantické třídy jsme vytvořili na základě seznamu prvních dvou tisíc nejfrekventovanějších slov. Shrnuji tedy, že slova z našeho seznamu slov v sémantických třídách pokrývají celkem 77 procent textu. Dále jsme zjišťovali, kolik procent (či promile) budou pokrývat slova jednotlivých sémantických tříd.
Sémantické třídy lze rozdělit do dvou kategorií. Do první kategorie zahrneme sémantické třídy slov plnovýznamových, označujeme je čísly 1 až 32. Do druhé kategorie zařadíme třídy slov gramatických, neplnovýznamových, jako jsou předložky (třída 100), spojky (třída 101), zájmena (třída 102), neplnovýznamová příslovce (třída 103–105), modální slovesa (třída 106), interpunkce (třída 107).
Slova v těchto třídách gramatických (třídy 100–107) jsou velice frekventovaná a zaujímají 57 procent slov textu. Na sémantické třídy 1–32 obsahující jen plnovýznamová slova připadá tedy celkově 20 procent textu, tj. 200 promile. V průměru připadá na jednu plnovýznamovou sémantickou třídu 6 promile (200:32).
[107]Konkrétně bylo zjištěno, že v našem textu je nejméně zastoupena sémantická třída 21, která pokrývá 1.1 promile, a nejvíce třída 7, která pokrývá 12.5 promile. V tomto rozmezí 1.1 až 12.5 se pohybuje pokrytí všech sémantických tříd 1–32. To zachycuje tabulka č. 2 (s. 108).
Pro větší názornost zde uvedeme z několika sémantických tříd vždy první čtyři nejfrekventovanější slova a dvě nejméně frekventovaná slova, tj. s frekvencí 1, tak jak se vyskytují ve vybraném textu.
V třídě 10: pohyb je to: jít 26, přijít 19, rychle 17, krok 16; frekvenci 1 mají např. odchod, odjet.
V třídě 11: přenos, změna polohy: vrátit 21, obrátit 13, nést 8, vracet 7; frekvenci 1 mají např. klesat, nosit.
V třídě 12: krajina, hmota: papír 9, hvězda 9, řeka 8, obloha 8; frekvenci 1 mají např. břeh, hmota.
V třídě 13: vlastnosti hmoty, smysly: vidět 35, hlas 24, pohled 21, těžký 14; frekvenci 1 mají např. hledět, hořet.
V třídě 14: živočich, biologická činnost: život 42, člověk 36, lidé 27, smrt 7; frekvenci 1 mají např. spát, tělesný.
V třídě 15: část organismu: tvář 28, hlava 28, oko 27, ruka 26; frekvenci 1 mají např. bok, brada.
Frekvenční seznam slov pro danou sémantickou třídu je zajímavý i tím, že umožňuje vidět, která slova se v daném textu nevyskytují – mají nulovou frekvenci. Například ze sémantické třídy 13, jejíž seznam obsahuje 76 slov, má nulovou frekvenci 13 slov. Mezi nimi například: bledý, temný, měkký, paprsek, patrný, sladký.
3. Problém stability sémantických tříd
Tato globální čísla pro sémantické třídy nám ještě nedávají odpověď na důležitou otázku, jak jsou tato čísla stabilní, resp. jak jsou stabilní zavedené sémantické třídy.
Jsou dvě možnosti. Čísla o zastoupení pro jednotlivou sémantickou třídu se na kratších úsecích od sebe buď značně liší, anebo odchylky od průměru nejsou příliš velké. Druhou možnost můžeme parafrázovat jako tvrzení, že počet slov v úsecích je konstantní, až na drobné odchylky. Na vyhodnocení této hypotézy použijeme statistický test χ2.
Pro naše zkoumání jsme rozdělili celkový počet slov daného textu o 30 000 slovech na deset pravidelných intervalů po 3000 slov, pro každý jsme zjistili počet slov v jednotlivých sémantických třídách a vypočetli jsme průměr a směrodatnou odchylku. Výsledky jsou uvedeny v tabulce č. 3 (s. 109).
Výklad a vzorec pro směrodatnou odchylku je uveden podle knihy Cyhelský – Kaňoková – Novák (1986, s. 75) nebo též Těšitelová (1992, s. 38), srov.
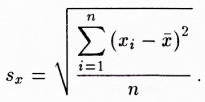
Směrodatná odchylka měří variabilitu ve smyslu odlišnosti jednotlivých hodnot od aritmetického průměru x̄.
Dále jsme spočítali poměr směrodatné odchylky k aritmetickému průměru, vyjádřený v procentech, tj. (sx/x̄) × 100, tj. variační koeficient Vx. Toto číslo pak považujeme za celkovou míru odlišnosti od průměru. Je přirozené říci, že je-li tato
[108]Tab. č. 2. Počet zjištěných slov
| A | B | C | D |
| 1 | 26 | 101 | 3,4 |
| 2 | 49 | 194 | 6,5 |
| 3 | 52 | 314 | 10,5 |
| 4 | 50 | 134 | 4,5 |
| 5 | 70 | 229 | 7,6 |
| 6 | 32 | 237 | 7,9 |
| 7 | 52 | 375 | 12,5 |
| 8 | 50 | 149 | 5,0 |
| 9 | 37 | 75 | 2,5 |
| 10 | 62 | 263 | 8,8 |
| 11 | 43 | 169 | 5,6 |
| 12 | 45 | 102 | 3,4 |
| 13 | 76 | 362 | 12,1 |
| 14 | 42 | 199 | 6,6 |
| 15 | 42 | 291 | 9,7 |
| 16 | 41 | 168 | 5,6 |
| 17 | 49 | 66 | 2,2 |
| 18 | 59 | 212 | 7,1 |
| 19 | 61 | 153 | 5,1 |
| 20 | 62 | 111 | 3,7 |
| 21 | 40 | 33 | 1,1 |
| 22 | 62 | 172 | 5,7 |
| 23 | 68 | 220 | 7,3 |
| 24 | 47 | 263 | 8,8 |
| 25 | 30 | 49 | 1,6 |
| 26 | 52 | 220 | 7,3 |
| 27 | 71 | 256 | 8,5 |
| 28 | 69 | 322 | 10,7 |
| 29 | 47 | 66 | 2,2 |
| 30 | 45 | 261 | 8,7 |
| 31 | 49 | 201 | 6,7 |
| 32 | 38 | 58 | 1,9 |
| 100 | 27 | 2291 | 76,4 |
| 101 | 50 | 3129 | 104,3 |
| 102 | 26 | 4084 | 136,1 |
| 103 | 33 | 426 | 14,2 |
| 104 | 32 | 439 | 14,6 |
| 105 | 70 | 788 | 26,3 |
| 106 | 6 | 1737 | 57,9 |
| 107 | 9 | 4303 | 143,4 |
Legenda:
sloupec A: číslo sémantické třídy
sloupec B: počet různých slov v dané sémantické třídě, počet slov v seznamu
sloupec C: počet slov nalezených ve zvoleném textu patřících do dané sémantické třídy
sloupec D: počet nalezených slov přepočítaný na délku textu o 1000 jednotek populace (slova či interpunkce)
[109]Tab. č. 3. Přehled aritmetických průměrů a směrodatných odchylek, χ2
| A | B | C | D | E | F |
| 1 | 10.1 | 2.4 | 24 % | 5.63 | + |
| 2 | 19.4 | 4.2 | 22 % | 8.99 | + |
| 3 | 31.4 | 6.9 | 22 % | 15.17 | + |
| 4 | 13.4 | 6.0 | 45 % | 27.04 | – |
| 5 | 22.9 | 7.3 | 32 % | 23.53 | – |
| 6 | 23.7 | 6.5 | 27 % | 17.56 | – |
| 7 | 37.5 | 9.2 | 25 % | 22.79 | – |
| 8 | 14.9 | 4.7 | 32 % | 14.56 | + |
| 9 | 7.5 | 3.5 | 47 % | 16.33 | + |
| 10 | 26.3 | 7.2 | 27 % | 19.93 | – |
| 11 | 16.9 | 4.5 | 27 % | 11.77 | + |
| 12 | 10.2 | 6.5 | 64 % | 41.73 | – |
| 13 | 36.2 | 7.4 | 20 % | 15.13 | + |
| 14 | 19.9 | 6.9 | 35 % | 24.07 | – |
| 15 | 29.1 | 8.2 | 28 % | 23.33 | – |
| 16 | 16.8 | 5.3 | 32 % | 16.64 | + |
| 17 | 6.6 | 4.9 | 74 % | 36.42 | – |
| 18 | 21.2 | 6.8 | 32 % | 21.87 | – |
| 19 | 15.3 | 7.3 | 48 % | 35.04 | – |
| 20 | 11.1 | 2.6 | 23 % | 6.03 | + |
| 21 | 3.3 | 2.1 | 64 % | 12.76 | + |
| 22 | 17.2 | 6.2 | 36 % | 22.42 | – |
| 23 | 22.0 | 9.3 | 42 % | 39.73 | – |
| 24 | 26.3 | 8.4 | 32 % | 26.70 | – |
| 25 | 4.9 | 2.3 | 47 % | 10.80 | + |
| 26 | 22.0 | 5.3 | 24 % | 12.91 | + |
| 27 | 25.6 | 5.6 | 22 % | 12.05 | + |
| 28 | 32.2 | 6.8 | 21 % | 14.52 | + |
| 29 | 6.6 | 3.6 | 55 % | 19.76 | – |
| 30 | 26.1 | 5.8 | 22 % | 12.98 | + |
| 31 | 20.1 | 4.0 | 20 % | 7.91 | + |
| 32 | 5.8 | 1.8 | 31 % | 5.79 | + |
| 100 | 229.1 | 12.4 | 8 % | 6.76 | + |
| 101 | 312.9 | 34.6 | 11 % | 38.35 | – |
| 102 | 408.4 | 25.5 | 6 % | 15.95 | + |
| 103 | 42.6 | 4.8 | 11 % | 5.31 | + |
| 104 | 43.9 | 8.0 | 18 % | 14.46 | + |
| 105 | 78.8 | 7.9 | 10 % | 7.89 | + |
| 106 | 173.7 | 16.4 | 9 % | 15.56 | + |
| 107 | 430.3 | 21.4 | 3 % | 3.59 | + |
Legenda:
sloupec A: číslo sémantické třídy
sloupec B: aritmetický průměr
sloupec C: směrodatná odchylka
sloupec D: poměr směrodatné odchylky k průměru (vyjádřený v procentech)
sloupec E: výsledek vzorce pro χ2
sloupec F: splnění testu χ2, + znamená splněno, – znamená nesplněno
[110]hodnota větší než 50 procent, je odlišnost vysoká, nadměrná. Zjistili jsme, že ve čtyřech případech tato nadměrná odlišnost nastává. Jedná se o sémantické třídy 12, 17, 21, 29. Ve všech ostatních případech je míra odlišnosti nižší než 50 procent.
Provedli jsme výpočet pro ověření výše uvedené hypotézy testem χ2. Výklad a vzorec pro χ2 nalezneme u Těšitelové (1992, s. 60). Hodnota χ2 pro 9 stupňů volnosti na hladině významnosti 0.05 je 16.919. Výpočtem jsme zjistili, že z celkového počtu 40 sémantických tříd je hypotéza splněna na pětiprocentní hladině významnosti celkem v 24 případech a nesplněna je ve zbývajících 16 případech. Nižší hladina významnosti již nemá praktický význam. Pro dokreslení situace uvádíme, že při stanovení hladiny významnosti na 0.1 procenta bude naši hypotézu splňovat ještě dalších dvanáct tříd. Ale přesto zůstanou sémantické třídy (konkrétně 12, 17, 19, 24, 101), které ani takto oslabenou hypotézu nesplňují. Shrnujeme tedy, že situace není jednoznačná. Pro některé třídy jsou odchylky od konstantní hodnoty malé, pro zbývající velké. (Získané výsledky obsahuje tabulka č. 3 ve sloupcích E a F.) Pro třídy, u nichž test χ2 nepotvrdil zvolenou hypotézu, se nabízí otázka, zda odchylky od průměru nejsou spolu korelovány. Pro výklad korelace viz např. již výše uvedenou knihu Cyhelský – Kaňoková – Novák (1986, s. 108–115). Koeficient determinace (tj. druhá mocnina korelačního koeficientu) v absolutní hodnotě je větší než 0.5 jen pro tyto dvojice tříd: 5–10, 18–19, 10–23, 4–34, 15–34. Korelovanost tříd je tedy celkově velmi malá, což nasvědčuje tomu, že sémantické třídy jsou navzájem nezávislé.
Abychom viděli, jaká konkrétní čísla vycházejí v 10 použitých intervalech, zvolili jsme jako ukázku výsledky pro dvě třídy: 3 a 24. Třídu 3 jsme vybrali proto, že zde míra odchylek od průměru není velká, naproti tomu u třídy 24 jsou odchylky velké. Oba vybrané příklady jsou uvedeny v tabulce č. 4.
Tab. č. 4. Odchylky od průměru
| 1. | 2. | 3. | 4. | 5. | 6. | 7. | 8. | 9. | 10. | interval | |
| třída 3 |
|
|
|
|
|
|
|
|
| ||
| 23 | 20 | 31 | 32 | 34 | 38 | 42 | 39 | 31 | 24 | průměr = 31.4 | |
| – 8.4 | –11.4 | –0.4 | 0.6 | 2.6 | 6.6 | 10.6 | 7.6 | –0.4 | –7.4 | odchylky od | |
|
|
|
|
|
|
|
|
|
|
| průměru | |
|
|
|
|
|
|
|
|
|
|
|
| |
| třída 24 |
|
|
|
|
|
|
|
|
| ||
| 16 | 29 | 33 | 21 | 45 | 32 | 18 | 23 | 19 | 27 | průměr = 26.3 | |
| –10.3 | 2.7 | 6.7 | –5.3 | 18.7 | 5.7 | –8.3 | –3.3 | –7.3 | 0.7 | odchylky od | |
|
|
|
|
|
|
|
|
|
|
| průměru | |
Opustíme-li při interpretaci výsledků rovinu statistiky a přihlédneme k obsahu textu, pak vysvětlíme nalezené výrazné odchylky od průměru směrem nahoru jako ta místa textu, která jsou podmíněna tématem, které používá slova z dané sémantické třídy ve zvýšené míře.
4. Závěr
Je známo, že text přináší nějaké sdělení. Základní jednotkou, atomem sdělení jsou věty. Nemůžeme připsat tuto funkci slovům. Naše zkoumání pak potvrzuje, že nejčastější slova pokrývají většinu textu a že sama o sobě nepřinášejí nic nového. Nová informace vzniká až zkombinováním frekventovaných i méně často se vyskytujících slov do vět.
[111]Pro vyjasnění dalších otázek je potřebný další výzkum. V našem zpracování jsme nerozlišovali případy, kdy jedno slovo má více významů, a zařadili jsme slovo jen do jedné sémantické třídy. Další výzkum by provedl jemnější rozlišení významů a potřebnou dezambiguaci. Tak například jsme pracovali jen s jedním zařazením slovesa být jako pomocného slovesa a nevydělovali jeho použití jako slovesa sponového. Také je třeba prozkoumat další texty beletristické, abychom zjistili, jaké hodnoty získáme pro více textů, srovnat je a zjistit, jak se budou lišit od dosavadních výsledků. Je tedy třeba rozšířit prozkoumaný materiál. Dále prozkoumat texty jiného žánru, např. vědecké, a výsledky srovnat. Konečně je třeba prozkoumat zařazení slov méně frekventovaných a nejméně frekventovaných do sémantických tříd.
Ale již na tomto nerozsáhlém materiálu můžeme vidět, že sémantické třídy se vyznačují rysem, který přispívá k jejich objektivizaci: každá sémantická třída je v textu zastoupena a míru tohoto zastoupení můžeme charakterizovat jistou průměrnou hodnotou.
LITERATURA
CYHELSKÝ, L. – KAŇOKOVÁ, J. – NOVÁK, I.: Teorie statistiky. Praha 1986.
Český slovník věcný a synonymický. Ed. J. Haller et al. 1.–3. díl. Praha 1969–1977.
FRIŠ, M.: Příspěvek k objektivizaci sémantických tříd. SaS, 53, 1992, s. 23–32.
FRUMKINA, R. M.: O metode izučenija semantiki cvetooboznačenij. Semiotika i informatika, 10, 1978, s. 142–161.
HALLIG, R. – WARTBURG, W.: Begriffsystem als Grundlage für die Lexikographie. Berlin 1963.
JELÍNEK, J. – BEČKA, J. V. – TĚŠITELOVÁ, M.: Frekvence slov, slovních druhů a tvarů v českém jazyce. Praha 1961.
MOSKOVIČ, V. A.: Statistika i semantika. Moskva 1969.
Roget Thesaurus. Penguin Books. Hardmodsworth 1968.
ŘEZÁČ, V.: Rozhraní. Praha 1986.
TĚŠITELOVÁ, M.: Quantitative linguistics. Praha 1992.
R É S U M É
The distribution of semantic classes in the text of a novel
This paper uses a classification of the two thousend most frequent words of Czech language into 40 semantic classes. A semantic class consists of words with mutually close meaning. A specific book of fiction has been used for this research. It was found that the most frequent words (including punctuation signs) cover 77 % of the text.
Thirty two classes consisting of meaningfull words (non-grammatical) make up 20 % of the text, i.e., 0.6 % of text per class on average. The least represented is class 21 which covers 0.11 % of the text, and the most represented is class 7 which covers 1.25 % of the text.
For further investigation 30 000 words of text were divided into ten intervals of 3000 words each. A hypothesis was proposed that the deviations of the number of words belonging to individual semantic classes from the arithmetic average are small. Using the chi-square test this hypothesis was confirmed with 5 % significance level for 24 semantic classes out of 40. It can be said that in this sense our semantic classes are stable for this text.
Slovo a slovesnost, ročník 58 (1997), číslo 2, s. 105-111
Předchozí Milada Homolková: Slovotvorný morfém proti- z pohledu diachronního
Následující Jana Hoffmannová: Pražské dialogy
© 2011 – HTML 4.01 – CSS 2.1