
Ukázka použití statistického zkoumání při přípravě strojové syntézy českého jednoduchého slovesného tvaru indikativního
Dana Konečná
[Discussion]
Sur l’application de la statistique dans les travaux préparatoires à la synthèse automatique de la forme verbale simple à l’indicatif tchèque
Statistika zkoumá kvantitativní stránku hromadných jevů v nerozlučné spojitosti s jejich stránkou kvalitativní. Statistiku, resp. její metody je možno aplikovat v různých vědních oborech, tedy i v lingvistice. Na lingvistickou statistiku je třeba pohlížet jako na spojení metod statistických a lingvistických, v němž lingvistické zřetele musí mít postavení určující. Při vytváření statistického souboru můžeme sledovat dva cíle: (1) popis velkého nepřehledného celku prostřednictvím číselných charakteristik vhodně vytvořeného souboru; (2) zkoumání jevu uvnitř dostatečně velkého souboru prvků, vedoucí k rozpoznání zákonitostí, které se projevují teprve v početných souborech. Tyto dva cíle statistického šetření se velmi často od sebe nerozlišují, ačkoli jsou kvalitativně různé. V tomto článku uvádíme ukázku prvního, tj. použití popisu omezeného souboru českých slovesných tvarů při přípravě strojového překladu.
V lingvistice se v poslední době statistické zkoumání na jedné straně značně zdůrazňuje, na druhé straně je však k němu značná nedůvěra. Řada současných úkolů lingvistických se ovšem bez použití statistického zkoumání řešit nedá. Statistické zkoumání je zpravidla dost pracné, a i když v současné době máme možnost použít např. strojů na děrné štítky, zůstává namáhavá příprava úkolu a materiálu.
V našem článku vycházíme ze statistických údajů o souboru, který tvoří 4995 českých slovesných tvarů z matematických textů, majících převážně charakter učebnic pro vysoké školy (autoři Čech, Jarník, Kořínek, Ryšavý). Z textu byly vyexcerpovány všechny slovesné tvary s výjimkou tvarů slovesa být („nepravidelnost“ tvarů tohoto slovesa nás nutí pracovat s nimi v jiném úseku strojové syntézy). U každého slovesného tvaru (ať jednoduchého, či složeného) byla určena osoba, číslo, čas, způsob, slovesný rod, vid a třída (podle kmene prézentního). Strojem na děrné štítky byla potom zjištěna frekvence tvarů pro každou osobu (i nulovou), pro každé číslo (i nulové), stejně pro čas, způsob atd. — a pro některé kombinace, např. frekvence pro každou osobu, číslo, čas, způsob, rod a vid v závislosti na slovesné třídě atd.
Uvedený statistický výzkum provedlo oddělení pro teorii strojového překladu na filosofické fakultě Karlovy university v rámci přípravy nezávislé syntézy a analýzy češtiny, neboť jak při zkoumání problematiky převodního jazyka a jazyků informačních, tak při výzkumu kódování i při dalších úkolech musí se nutně věnovat pozornost i statistickým údajům. Pomocí strojů na děrné [269]štítky (i ruční třídičky) se zatím kromě již uvedeného zkoumání českých slovesných tvarů sestavují malé odborné frekvenční slovníky a připravují se nová šetření zaměřená na gramatiku. Začíná se také s použitím samočinných počítačů.
Při třídění zkoumaného souboru slovesných tvarů postupujeme takto: Slovesný tvar V je (v mezích zadání) úplně popsán obecnými indexy R, T, M, G, A, C; symbolicky vyjádřeno: V = V (R, T, M, G, A, C). Význam a označení obecných indexů, jejich zvláštní hodnoty a celkový počet jsou uvedeny v tab. 1.
|
| Index i | Počet možných indexů | |
| obecný | zvláštní | ||
| „osoba“ | R | 0, 1, 2, 3, 4, 5, 6 | 7 |
| čas | T | 0, 1, 2, 3 | 4 |
| způsob | M | 0, 1, 2, 3 | 4 |
| rod | G | 1, 2 | 2 |
| vid | A | 1, 2 | 2 |
| třída | C | 1, 2, 3, 4, 5 | 5 |
Tab. 1
Pozn.: V tomto článku užíváme termínu „osoba“ pro označení kombinací osoby a čísla; mluvíme tedy o nulté až šesté „osobě“ — srov. níže.
Jednotlivým obecným indexům připojujeme tyto hodnoty:
| R: | 0 — neurčité tvary 1 — 1. os. sg. 2 — 2. os. sg. 3 — 3. os. sg. 4 — 1. os. pl. 5 — 2. os. pl. 6 — 3. os. pl. |
| T: | 0 — nevyjadřuje čas 1 — prézens 2 — futurum 3 — préteritum |
| M: | 0 — nevyjadřuje způsob 1 — indikativ 2 — imperativ 3 — kondicionál |
| G: | 1 — aktivum 2 — pasívum |
| A: | 1 — nedokonavý vid 2 — dokonavý vid |
| C: | číslování v souhlase se značením slovesných tříd |
V souboru S slovesných tvaru (S = 4995) byly nejprve zjišťovány frekvence slovesných tvarů vzhledem k hodnotám obecných indexů R a C (tj. byly zjišťovány frekvence fR, C jednotlivých kombinací indexů R, C) nezávisle na hodnotách ostatních indexů.
Pozn.: Počet možných kombinací složených indexů R, C je 35. Všechny tyto kombinace v jazyce reálně existují.
Zjištěné frekvence fRC uvádíme v tab. 2. Jako mezisoučty jsou uvedeny frekvence slovesných tvarů fR (v závislosti na osobě) a fC (v závislosti na třídě).
Dále uvedená zjištění naznačují charakteristické rysy stylu matematických textů. I když to není naším úkolem, upozorňujeme aspoň na některé. Vedle 1. pl., kde jsme častý výskyt mohli očekávat, je tu značně frekventovaná 3. sg. proti 3. pl. Při popisu stylu matematických textů by bylo možno také využít srovnání údajů o souboru S s údaji o souboru S1 — viz dále.
| [270] | 1 | 2 | 3 | 4 | 5 | fR |
| 0 | 168 | 22 | 97 | 302 | 80 | 669 |
| 1 | 33 | 20 | 6 | 22 | 11 | 92 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 136 | 224 | 323 | 730 | 373 | 1786 |
| 4 | 465 | 362 | 136 | 668 | 389 | 2020 |
| 5 | 1 | 12 | 0 | 3 | 0 | 16 |
| 6 | 11 | 20 | 113 | 167 | 101 | 412 |
| fT | 814 | 660 | 675 | 1892 | 954 | 4995 |
Tab. 2
Zhodnocení tab. 2:
max {fR, C} = 730 pro R, C = 3,4
min {fR, C} = 0 pro R, C = 5,3; 5,5 a ve všech případech, kdy R = 2
Nejfrekventovanější je tu tedy tvar 3. sg. 4. třídy, vůbec se nevyskytly tvary 2. pl. ve 3. a 5. třídě a tvary 2. sg. všech tříd.
max {fR} = 2020 pro R = 4
min {fR} = 0 pro R = 2
Nejfrekventovanější jsou tu tedy tvary 1. pl., nevyskytly se tvary 2. sg.
max {fC} = 1892 pro C = 4
min {fC} = 660 pro C = 2
Nejfrekventovanější jsou tu tedy tvary 4. třídy, nejméně frekventované tvary 2. třídy.
Abychom získali podklady pro sestavení algoritmu syntézy jednoduchých slovesných tvarů indikativních, musíme ze souboru S vydělit soubor S1, v němž jsou shrnuty slovní tvary typu V1 = V (R, 1, 1, 1, 1, C) a V2 = V (R, 2, 1, 1, 2, C) pro všechna R ≠ O.
Tyto slovesné tvary (indikativ prés. akt. nedokonavého slovesa a indikativ fut. akt. dokonavého slovesa) mají stejnou flexi. Vydělený soubor S1 obsahuje celkem 1853 sloves typu V1 (tj. ind. prés. akt.) a 1503 sloves typu V2 (tj. nesloženého ind. fut. akt.). S1 = 2906, tj. 58,2 % ze souboru S.
| C R | 1
| 2
| 3
| 4
| 5
| fR
|
| 1 |
|
| 1 | 3 | 5 | 9 |
| 2 |
|
|
|
|
|
|
| 3 | 27 | 151 | 262 | 572 | 197 | 1209 |
| 4 | 49 | 1 | 57 | 93 | 167 | 367 |
| 5 |
|
|
|
|
|
|
| 6 | 4 | 7 | 90 | 120 | 47 | 268 |
| fT | 80 | 159 | 410 | 788 | 416 | 1853 |
Tab. 3
[271]Zjišťovali jsme frekvence slovesných tvarů typu V1 a V2 vzhledem k hodnotám indexů R a C (tj. frekvence fR, C jednotlivých kombinací indexů R, C jak pro slovesné tvary typu V1 a V2 zvlášť, tak i sumární frekvence pro oba typy zároveň).
Frekvence slovesných tvarů typu V1 jsou uvedeny v tab. 3, frekvence tvarů typu V2 v tab. 4, sumární frekvence v tab. 5. Význam mezisoučtů fR a fC je stejný jako v tab. 2.
| C R | 1 | 2 | 3 | 4 | 5 | fR |
| 1 | 32 | 20 |
| 9 | 2 | 63 |
| 2 |
|
|
|
|
|
|
| 3 | 34 | 60 |
| 19 | 3 | 116 |
| 4 | 235 | 323 | 13 | 261 | 28 | 860 |
| 5 |
|
|
|
|
|
|
| 6 | 1 | 11 |
| 1 | 1 | 14 |
| fC | 302 | 414 | 13 | 290 | 34 | 1053 |
Tab. 4
| C R | 1 | 2 | 3 | 4 | 5 | fR |
| 1 | 32 | 20 | 1 | 12 | 7 | 72 |
| 2 |
|
|
|
|
|
|
| 3 | 61 | 211 | 262 | 591 | 200 | 1325 |
| 4 | 284 | 324 | 70 | 354 | 195 | 1227 |
| 5 |
|
|
|
|
|
|
| 6 | 5 | 18 | 90 | 121 | 48 | 282 |
| fC | 382 | 573 | 423 | 1078 | 450 | 2906 |
Tab. 5
Údajů z tab. 5 je již možno využít při sestavování celkového algoritmu pro syntézu jednoduchých tvarů indikativních. Pomocí tohoto algoritmu budeme k „základu“ připojovat „téma“ a „koncovku“ (resp. jen „koncovku“). Za „základ“ budeme považovat tu část slovesného tvaru, která vznikne odtržením -e, resp. -í nebo -á od tvaru 3. sg. Za „koncovku“ budeme pokládat -š, -ø, -me, -te v 2. sg., 3. sg., 1. pl. a 2. pl. a dále tu část slovesného tvaru, která vznikne odtržením od „základu“ u tvaru 1. sg. a 3. pl. „Tématem“ je pak v 1.—3. třídě -e-, v 4. třídě -i-, v 5. -á-.
„Témata“ a „koncovky“ pro všechny „osoby“ všech tříd uvádíme v tabulce č. 6.
| [272]Třída C Osoba R | 1 | 2 | 3 | 4 | 5 |
| 1 | (*) -u -i | -u | -i | -ím | -ám |
| 2 | -e -š | -í -š | -á -š | ||
| 3 | -e -ø | -í -ø | -á -ø | ||
| 4 | e -me | -í -me | -á -me | ||
| 5 | -e -te | -í -te | -á -te | ||
| 6 | -ou -í * -ějí |
ou
|
-í
| -í -ějí -ejí -ědí |
-ají
|
Tab. 6
Pozn.: (*) — v některých případech dochází ke změně „základu“;
* — je nutná změna „základu“.
Porovnáním tab. 5 a tab. 6 dojdeme k závěru, že především bude účelné sestavit algoritmus pro tvoření slovesných tvarů 1. až 5. třídy ve 2. až 5. „osobě“ (resp. 3. a 4. „osobě“), a to z těchto důvodů: a) v této oblasti je největší počet sloves ze souboru S1 (srov. tab. 5), b) tvoření slovesných tvarů je tu bez komplikací, snadno lze stanovit jednoduchá pravidla (srov. tab. 6). Ad a) V tab. 7 uvádíme procentuální zastoupení tvarů 3. a 4. „osoby“; je to výtah z tab. 5.
| C R | 1 | 2 | 3 | 4 | 5 | fR |
|
| 3 | 61 | 211 | 262 | 591 | 200 | 1325 | 45,6 |
| 4 | 284 | 324 | 70 | 354 | 195 | 1227 | 42,2 |
| f'C | 345 | 535 | 332 | 945 | 395 | 2552 |
|
|
| 41,7 | 32,5 | 13,6 |
| 87,8 | ||
Tab. 7
f'C — frekvence slovesných tvarů třídy C pro 3. a 4. „osobu“
Pro R = 1 f1 = 72, tj. 2,5 % ze souboru S1;
pro R = 6 f6 = 282, tj. 9,7 % ze souboru S1.
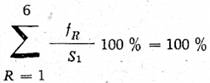
Při sestavování dílčího algoritmu zase přihlížíme k frekvenci f'C (srov. tab. 7 : 345 + 535 + 332 = 1212 pro 1.—3. třídu, 945 pro 4. třídu, 395 pro 5. třídu) a dále k frekvenci fR (tab. 5) tvarů pro 2.—5. „osobu“. Pro úplnost v algoritmu l dodáváme koncovky pro 2. a 5. „osobu“, které se v materiálu nevyskytly.
[273]Algoritmus 1
| Číslo instrukce | Instrukce | Číslo následující instrukce při kladné odpovědi || při záporné odpovědi | |
| 1 2 3 4 5 6 7 8 9 10 11 12 | Je to 1., 2. nebo 3 třída? Připoj k „základu“ -e-! Je to 4. třída? Připoj k „základu“ -í-! Připoj k „základu“ -á-! Je to 3. sg.? Tvar je utvořen! Je to 1. pl.? Připoj „koncovku“ -me! Je to plurál? Připoj „koncovku“ -te! Připoj „koncovku“ -š! | 2 6 4 6 6 7
9 7 11 7 7 | 3 6 5 6 6 8
10 7 12 7 7 |
Kdybychom měli vytvořit dané slovesné tvary zcela ekvivalentního matematického textu, bude v 87,8 % případů řešení úlohy probíhat podle algoritmu 1, ve většině případů bude řešení úlohy probíhat podle algoritmu 1 při syntéze jakéhokoli českého matematického textu. Pro celkový algoritmus syntézy jednoduchých indikativních tvarů je výhodné před algoritmus 1 zařadit takové instrukce, které nás co nejrychleji přivedou k řešení nejčastějších případů, tedy instrukce vedoucí k oddělení postupu (1) při tvoření 3. pl., (2) při tvoření 1. sg.
Dílčí algoritmy pro 3. pl. a 1. sg. zde neuvádíme, je v nich třeba počítat mimo jiné ještě s dotazy na číslo vzoru (jiná čísla vzoru mají slovesa vzoru prosí, jiná slovesa vzoru sází atd.).
Vztahy mezi pravděpodobností výskytu a uspořádáním v systému (tj. vztahy mezi kvantitativní a kvalitativní stránkou jevů) bývají velmi složité. U většiny jazykových jevů bude třeba tyto vztahy teprve zkoumat. V našem případě přihlížení k frekvenci jednoduchých indikativních tvarů pro 2. a 3. sg., 1. a 2. pl. v jazyce matematických textů i k formám těchto tvarů nás vede jen k jedinému vhodnému řešení dílčího algoritmu. Tato situace není při sestavování algoritmů pro strojový překlad nijak obvyklá.
Slovo a slovesnost, volume 22 (1961), number 4, pp. 268-273
Previous Blanka Borovičková: K otázce spektrální analýzy mluvené řeči
Next Eduard Beneš, Bohuslav Havránek: Terminologická poznámka k pojmům „norma“ a „kodifikace“ (Příspěvek k diskusi)
© 2011 – HTML 4.01 – CSS 2.1