
Některé otázky syntaktické analýzy (z hlediska strojového překladu)
Pavel Novák
[Articles]
Некоторые вопросы синтаксического анализа (с точки зрения машинного перевода) / Quelques aspects de l’analyse syntactique (du point de vue de la traduction automatique)
Obsah. V tomto článku[1] zjišťujeme, že většina dosud známých schémat syntaktické analýzy pro účely strojového překladu (dále SP) je založena na dvou známých syntaktických koncepcích, nazývaných zde prostě koncepcí A (viz bod 3) a koncepcí B (viz bod 4). V souvislosti s tím klademe otázku, zda byla navržena již všechna schémata, která lze na těchto koncepcích založit (3.31). Tento problém zobecňujeme (5). Z jednoho hlediska je článek vlastně návrhem jisté klasifikace schémat syntaktické analýzy pro účely SP, založených na obou koncepcích. Z druhého hlediska je hlavní část článku (3.1—3.4) obsahovou přípravou k obdobnému formálnímu prozkoumání vztahů mezi jednotlivými variantami syntaktické analýzy vycházejícími z koncepce A, jakému již byly podrobeny některé varianty koncepce B (srov. 4.3). V článku se otázky prozatím spíše kladou, než řeší. Přesnější jich kladení i další řešení je bez těsné spolupráce s moderní logikou nemožné. V úvodě uvádíme některé pojmové distinkce (1) a naznačujeme vztah obou koncepcí (2). — Původní jsou hlavní myšlenky těchto částí: 2 (srov. však pozn. 16), 3.2—3.4, 3.53 (úprava kategoriální gramatiky).
1. Úvod. Vzhledem k tomu, že se při přípravě strojového překladu pracuje prozatím výhradně s texty tištěnými — toto omezení není ostatně zvláštností jen v této oblasti jazykovědy — lze říci, že má stroj přeměnit sled symbolů jisté grafiky (tj. vstupní text) v jiný sled symbolů stejné, popř. jiné grafiky (tj. výstupní text). Přeměna musí vyhovovat dvěma požadavkům: jednak musí být její postup formální, tj. založený jen na pořadí a druhu symbolů,[2] jednak smysl obou textů (vstupního i výstupního) musí být stejný.[3] Obecně řečeno, děje se přeměna tak, že se každá věta vstupního textu analyzuje a na podkladě výsledků analýzy a tzv. korespondenčních pravidel provede se syntéza textu výstupního. Korespondenčními pravidly rozumíme zachycení vztahu souznačnosti mezi lexikálními i gramatickými jednotkami dvou nebo více jazyků. Příkladem korespon[10]denčních pravidel, ovšem jiného stupně přesnosti a úplnosti, než vyžaduje SP, jsou dvojjazyčné nebo vícejazyčné slovníky a porovnávací gramatiky.
1.1. Součástí analýzy je i analýza syntaktická. Ta není obdobou školního větného rozboru v mateřském jazyce. Zatímco žák rozebírá větu, které již porozuměl, stroj „rozumí“ větě teprve po provedení analýzy.[4]
Při syntaktické analýze jde především (a) o zjištění syntaktických vztahů (ve velmi obecném pojetí neimplikujícím žádnou určitou syntaktickou koncepci) ve větách vstupního textu.[5] S tím souvisí (b) rozčlenění vstupního textu na úseky vhodné pro takové zjišťování — rozčlenění textu na věty a souvětí, souvětí na věty jednoduché — a dále (c) odstranění gramatické homonymie odstranitelné s pomocí kontextu v rámci věty. Pozornost věnujeme problematice (a), avšak vynecháme otázky spojené s analýzou koordinace.
1.2. Od syntaktické analýzy pro účely SP (dále budeme psát již jen synt. analýza) — úkol (I) — je nutno odlišovat jiné úkoly analytického rázu. Tak např. je dána posloupnost slovních tvarů[6] daného jazyka; úkolem je zjistit (II), je-li tato posloupnost (gramaticky správně tvořenou) větou daného jazyka.[7] Dále, je dán dostatečně rozsáhlý text v jistém jazyce; úkolem (III) je odhalit jeho syntax.[8] Od takových úkolů, které kladou různě přísné a někdy i různě zaměřené požadavky na naše poznání jazyka, odlišujme předně sám popis, který musí těmto požadavkům vyhovovat, dále jisté obecné představy o stavbě jazyka, buď celku, nebo některé její části — např. syntaktické koncepce, které se při popisu uplatňují, a nakonec nějaký jazykový nebo vůbec symbolický výtvor plnící jistý takový úkol (učebnice, algoritmus apod.) a opírající se o adekvátní popis, v němž se koncepce uplatňuje.
2. Dvě syntaktické koncepce. Proti pořadu „lineárnímu“ staví se [11]někdy tzv. pořad „strukturní“.[9] Chce se tím naznačit, že vedle „vnější“, lineární organizace složek textu existuje ještě jiná jejich organizace, skrytější, avšak závažnější. Podobně jako v pojmu lineárního pořadu jsou zahrnuty dva logicky nezávislé principy (antepozice — postpozice; postavení kontaktní — distantní),[10] lze aspoň dva takové principy rozeznat i v pojmu pořadu strukturního.
Vezměme např. českou větu Otec dočetl dlouhý dopis. Může tu jít jednak o to, že jsou některé dvojice sl. tvarů spjaty vztahem synt. závislosti, jednak o to, že k sobě sl. tvary různě patří v tom smyslu, že se sdružují do jistých celků, tyto celky do vyšších celků atd.
2.1. Přistoupí-li v prvním případě omezení, že každý sl. tv.,[11] popř. s výjimkou jednoho, nezávislého,[12] musí záviset právě na jediném sl. tvaru jiném, budeme hovořit o koncepci A. Z hlediska této koncepce si můžeme syntaktickou stavbu naší věty znázornit graficky takto:[13]

Je jasné, že koncepce A zahrnuje zhruba společné rysy tradiční již u nás koncepce syntaktických (tzv. větných) dvojic a koncepce slovních spojení (rus. slovosočetanije).[14]
2.2. V druhém případě budeme mluvit o koncepci B. Ta odpovídá zhruba tzv. analýze podle bezprostředních složek (N. A. Sljusareva, l. c.). Nejčastější je ta podoba koncepce B, v níž se uplatňuje princip kontaktního postavení uvnitř zmíněných celků a princip dvojčlennosti těchto celků. Dále budeme koncepcí B rozumět především tuto její podobu. Poznamenejme, že zatímco princip dvojčlennosti je tedy v koncepci B samostatnou složkou, je v koncepci A princip dvojčlennosti vztahu synt. závislosti logicky spjat se základní myšlenkou této koncepce. Z hlediska koncepce B si můžeme syntaktickou stavbu naší věty znázornit graficky např. způsobem u nás dost obvyklým:
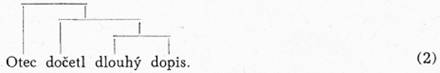
[12]Jde tu např. o to, že dlouhý a dopis vytvářejí celek dlouhý dopis a ten spolu s dočetl celek dočetl dlouhý dopis. Koncepce B je matematicky prostudována mnohem více než koncepce A (viz pozn. 32 a 33).
2.3 Uvedme ještě graf slučující reprezentace (rus. predstavlenije, angl. representation) této věty podle obou koncepcí.[15] Je na něm vidět, jak se obě koncepce doplňují.[16]

3. Koncepce A. Z hlediska této koncepce jde při zjišťování syntaktických vztahů přirozeně o to, zjistit pro každý závislý sl. tv. příslušný sl. tv. řídící, tedy jinými slovy, sestrojit graf stejného typu jako je graf (1), srov. L. Tesnière, op. cit. v pozn. 9.
Úkony, které vedou k takovému výsledku, musí být, jak jsme se již zmínili, formální. Není ovšem možno sestrojit formální postup synt. analýzy pro všechny jednotlivé sl. tvary, nýbrž jen pro jisté jejich množiny, pro jisté synt. charakteristiky. Konkrétním sl. tvarům musí být tedy jednoznačně přiřazeny jisté takové synt. charakteristiky. Synt. analýza se pak provádí na posloupnosti symbolů synt. charakteristik vzniklé z analyzované věty (posloupnosti sl. tvarů) záměnou každého sl. tvaru symbolem příslušné synt. charakteristiky.[17] Posloupnosti těchto symbolů budeme nazývat S-strukturami.[18]
3.1 Nutným předpokladem pro sestavení algoritmu synt. analýzy, který ze S-struktury věty zjistí synt. závislosti mezi sl. tvary, je a) seznam jistých synt. tříd sl. tvarů,[19] b) seznam elementárních synt. konstrukcí, tzv. konfigurací (vyjádřených v terminologii těchto tříd),[20] c) jisté poznatky slovosledné. Jak uvidíme (srov. 3.5.), lze a) a b) jistým způsobem upravovat (touto formulací nechceme ovšem nic tvrdit o konkrétním postupu prací při sestavování dále uvedených schémat synt. analýzy, jde tu jen o vztahy těchto schémat).
[13]3.2. Mějme nyní seznam synt. tříd sl. tvarů pro jistý jazyk. Nechť jsou X, Z (popř. s indexy) proměnné, oborem jejichž hodnot jsou symboly těchto tříd. Každý řádek v seznamu konfigurací může mít tento tvar
k XiXj : Z (4)
kde k — symbol (pořadové číslo apod.) konfigurace, Z — synt. třída, která má — z hlediska daného úkolu formální synt. analýzy — stejné synt. (kombinační) vlastnosti jako dvojice Xi Xj, a buď Z = Xi (to znamená, že Xi je řídícím a Xj závislým členem konfigurace), nebo Z = Xj (to znamená situaci opačnou).[21] Symbolům před dvojtečkou budeme říkat levá strana řádky, symbolům za dvojtečkou pravá strana. Tento způsob zápisu konfigurací se může zdát neúsporný, avšak má tu výhodu, že je patrná souvislost s tvarem (5), jehož je tvar (4) jen speciálním případem. Obecně totiž nemusí být Z = Xi nebo Z = Xj; k tomu, aby se zaznamenalo, že je řídícím členem Xi nebo Xj, stačí označit jeden z členů konfigurace (dále vždy člen řídící) nějakým indexem, např. apostrofem:
k Xi X'j : Z (5)
Přitom předpokládáme, že anteponované nebo postponované postavení členů konfigurace je udáno pořadím symbolů v řádku na levé straně řádku tvaru (4), (5) nebo (6). Závaznost postavení začátkového, středového nebo koncového některého z členů konfigurace je někdy účelné vyznačit zvlášť (srov. pozn. 31). Pak ovšem dostaneme situaci poněkud složitější, než jaká je dále zachycena. Tvar (5) je nejobecnější způsob zápisu.[22]
Jak jsme již uvedli v 2.2, je dvojčlennost vztahu synt. závislosti podstatnou složkou koncepce A. Je to vidět i na tom, že z tohoto hlediska nezáleží na počtu členů konfigurace. Teoreticky pro jakékoli přirozené číslo n zápis tvaru
k Xi1, Xi2 … Xin : Z (6)
kde je právě jen jedno X označeno apostrofem, znamená, že všechna ostatní X jsou na tomto X' jednotlivě závislá. Kvůli jednoduchosti však budeme dále většinou pracovat jen s dvoučlennými konfiguracemi. Pro další účely budeme skutečnost, že X je nebo není označeno apostrofem (tj. funkci členu X v konfiguraci), označovat symbolem f.
3.3 Máme tedy pět prvků (k, Xi, Xj, Z, f), z nichž můžeme vytvářet různé kombinace.[23] Některé z těchto kombinací představují typ synt. charakteristiky, jaký lze v jistém schématu synt. analýzy přiřadit konkrétnímu sl. tvaru. Např. v jednom takovém schématu je synt. charakteristika typu kf, což znamená, že sl. tvar má v konfiguraci k jistou synt. funkci (že je např. řídícím členem). To je však jen jedna ze dvou možných interpretací, a to interpretace „přímá“. Všech 23 kombinací můžeme však interpretovat také jinak, „nepřímo“, s pomocí druhé[14]ho členu konfigurace. V našem případě (kf) by tedy šlo o to, že se sl. tvar vyskytuje v kombinaci k, jejíž druhý člen je členem řídícím.
3.31. Některé z těchto 46 (tj. 23 × 2) kombinací se v úloze synt. charakteristik v literatuře již vyskytly, totiž X; kf; Xi fXj (všechny tři v „přímé“ interpretaci), většina nikoli. Je nyní otázka, zdali bylo použito již všech možných kombinací. Ukážeme si dále na jednom případě (XfZ v nepřímé interpretaci), že nikoli.
Bylo by ovšem třeba nejprve prozkoumat všechny zbývající kombinace, dále pak zjistit pravidla vymezující kombinace možné proti kombinacím nemožným. Součástí těchto pravidel bude jistě zjištění, které kombinace a za jakých podmínek určují jistou synt. třídu a dále — vzhledem k tomu, že výběr kombinace má vliv na tvar řádku v seznamu konfigurací — i zjištění souvislosti s různými typy redukce tohoto seznamu. Nabízejí se ovšem i otázky další, např. zda je možné, že výběr některých kombinací a z toho vyplývající úpravy seznamu konfigurací spolu s jistým typem postupu při synt. analýze budou pro některé jazyky vhodnější než kombinace jiné nebo pro jiné jazyky. Seznamy konfigurací se od sebe mohou lišit vedle rozsahu (počtu řádků) a tvaru řádku i tím, že mohou být uspořádané nebo neuspořádané.
3.4 Klasifikace, jakou jsme vlastně navrhli v 3.3 pro synt. charakteristiky, je ovšem jen součástí budoucí celkové klasifikace schémat synt. analýzy.
O postupu synt. analýzy lze říci zatím tolik; je omezen dvěma momenty: jednak musí zabezpečit zjišťování synt. závislostí nejen mezi sousedními sl. tvary, jednak je jasné, že se tak nemůže dít prostě přezkoumáním všech kombinací 2. třídy ze symbolů vyskytujících se v dané S-struktuře, že se tedy musí počítat s jistými slovoslednými pravidly. Obvykle se začíná se zjišťováním syntaktických závislostí mezi sousedními sl. tvary. Uvádějí se různá pravidla omezující hledání závislostí mezi sl. tvary. Jedno z nich se dá formulovat takto:[24] v zápisu větné struktury s pomocí závorek — všechny sl. tvary závislé na jistém sl. tvaru jsou i se sl. tvary závislými na nich ve společných závorkách (včetně sl. tvaru řídícího), přičemž členy závislé mají po jedněch závorkách navíc, např. ((Otec) dočetl ((dlouhý) dopis)) — nemůže dojít k případu:
(k (l )k )l (7)
kde k a l označují závorky, které „k sobě patří“.
Jak uvidíme, je možný postup „od textu k systému“, a to buď „zleva doprava“ (viz 3.512), nebo „zprava doleva“ (viz 3.521), i postup „od systému k textu“ (viz 3.511).[24a] Často se uplatňuje postupná redukce S-struktury (viz 3.511, 3.521, 3.53), vedle ní však i postupy jiné (viz 3.512, 3.522).
Dále bude třeba zkoumat další otázky, především vztah možných synt. charakteristik, možných úprav seznamu konfigurací a možných typů postupu. Např. postup od „systému k textu“ není možný u synt. charakteristiky tvaru XfZ a Xi f Xj.
3.5. Provedeme nyní ukázkový rozbor jednoduché anglické věty Dunn chooses electrical analogs. Větu anglickou jsme zvolili s ohledem na to, že většina schémat byla předvedena právě na anglickém materiálu.
3.51. Syntaktická charakteristika tvaru X. Jako synt. charakteristika funguje přímo symbol synt. třídy. Mohli bychom tu mluvit o symbolice „značkové“ (v Mathesiově smyslu). Nejde o to, [15]že by symboly pro jednotlivé synt. třídy nemohly být jistým způsobem popisné — a bývá to i dokonce výhodné (srov. pozn. 22) — nýbrž o to, že je tu z obecného hlediska jakákoli popisnost symbolů nepodstatná. Tato symbolika předpokládá úplný soupis konfigurací. Pro analýzu S-struktury je možno postupovat dvojím způsobem: buď vycházet při analýze z uspořádaného souboru konfigurací (ze „systému“), nebo z „textu“ (pak je množina konfigurací neuspořádaná).
3.511. „Systém-text“.[25]Stroj přiřadí jednotlivým sl. tvarům analyzované věty symboly synt. tříd.[26] V našem příkladě (vpravo dole je u každého symbolu pořadové číslo sl. tvaru).
| Dunn 11 | chooses 2+2 | electrical 33 | analogs 14 | (8) (9) |
Ve stroji je uložen v jistém pořadí seznam konfigurací.[27]
V seznamu jsou i tyto řádky (tečky označují jistý počet řádek, na nichž nám právě nezáleží):
.........................................................
3 1 → 1
.........................................................
2+ 1 → 2—
.........................................................
Operace na S-struktuře se provádějí takto: Zjistí se, vyskytuje-li se v ní posloupnost totožná s posloupností symbolů levé strany v 1. řádce seznamu konfigurací. V kladném případě se do S-struktury dosadí za všechny případy takové posloupnosti symboly z pravé strany 1. řádky. V záporném případě nebo po vykonání popsané operace se přistoupí k obdobné konfrontaci 2. řádky s posloupností symbolu již upravenou atd. V našem případě bude první úprava mít tvar 1122+ 14, čímž se zjistí, že sl. tvary electrical a analogs tvoří konfiguraci s analogs jako řídícím členem (podle zápisu, kterého budeme dále užívat, electrical ← analogs — šipka směřuje k závislému členu) a druhá (a konečná) úprava bude mít tvar 11 2—2, čímž se zjistí, že jednak chooses → analogs, jednak Dunn ← chooses („predikační“ konfigurace).
3.512. „Text-systém“ (viz K. E. Harper — D. G. Hays, op. cit., 191). V Harperově systému jsou symbolika a soupis konfigurací podobné jako u Mološné, s tím rozdílem, jak již bylo poznamenáno, že na pořadí řádků v seznamu konfigurací nezáleží. Postup je tento. Mezi symboly synt. tříd se vsune symbol p, v našem případě tedy 11p 2+2p 33p 14. Postupuje se dále zleva doprava. První levá dvojice 11p 2+2 se srovná se seznamem konfigurací a podle výsledku hledání se na zvláštní místo zapíše buď 11 d 2+2 (závisí-li 11 na 2+2), nebo 2+2 d 11 (závisí-li 2+2 na 11),[28] v našem případě tedy 11 d 2+2. Další postup se řídí ve shodě s těmito zása[16]dami: a) XpY se zavádí, je-li pořadové číslo symbolu X v S-struktuře menší než pořadové číslo symbolu Y, jestliže každý symbol, jehož pořadové číslo je větší než X a menší než Y, je odvozen buď z X, nebo z Y, jestliže ani X, ani Y nejsou od sebe vzájemně odvozeny a jestliže X, Y nebo obě jsou nezávislé; b) XdY se zavádí, jestliže X a Y jsou uvedeny v seznamu konfigurací, jestliže XpY nebo YpX a jestliže nebyla předtím zjištěna závislost X na jiném symbolu.
Další dvojice, tj. 2+2 p 33 se v seznamu konfigurací nenajde, avšak dvojice 33 p 14 ano, proto 33 d 14. Zjistili jsme tedy zatím, že Dunn ← chooses a electrical ← analogs. Podle zásady a) je však třeba ještě zavést 2+2 p 14, načež hledání v seznamu konfigurací dá 14 d 2+2 (tj. chooses → analogs). Tím je synt. analýza věty u konce.[29]
3.52. Při dalších tvarech synt. charakteristiky můžeme mluvit o symbolice „popisné.
3.521. Synt. charakteristika tvaru kf. V systému cambridžské skupiny[30] se každému sl. tvaru přiřazuje symbol konfigurace (symboly konfigurací), v níž (v nichž) se může vyskytnout, jakož i symbol možné synt. funkce (člen řídící, závislý, obojí). Do paměti stroje již proto není nutno ukládat seznam konfigurací celý, nýbrž jen seznam symbolů konfigurací, jimž jsou opět přiřazeny symboly téhož druhu jako sl. tvarům [viz zde (11)].
Pro náš případ:[31]
|
|
| (7) |
| (12) |
|
|
| (7) |
| (12) |
|
| Dunn | . | 2 | . | 1 |
| 12 | . | 0 | . | 0 | (11) |
| chooses | . | 0 | . | 2 | (10) | 7 | . | 3 | . | 1 |
|
| electrical | . | 1 | . | 0 |
|
|
|
|
|
|
|
| analogs | . | 2 | . | 1 |
|
|
|
|
|
|
|
Postupuje se takto (opět zjednodušujeme): Zjistí se, zda mohou být poslední 2 nebo 3 sl. tvary členy 1. konfigurace, 2. konfigurace atd. V případě druhém se symboly přiřazené oběma (všem třem) sl. tvarům nahradí symboly přiřazenými příslušné konfiguraci a postup se opakuje. V případě záporném se obdobně vyšetřují dva (tři) sl. tvary od konce.
V našem případě se tak nejdříve zjistí, že electrical a analogs mohou být závislým, resp. řídícím členem 7. konfigurace. Jejich řádky se proto nahradí řádkem přiřazeným 7. konfiguraci [v (11)], tedy
|
| (7) |
| (12) |
| . | 2 | . | 1 |
| . | 0 | . | 2 |
| . | 3 | . | 1 |
a v dalším se zjistí, že Dunn ← chooses a chooses → analogs, čímž je synt. analýza u konce — všechny tři řádky nahrazeny řádkou přiřazenou 12. konfiguraci.
3.522. Synt. charakteristika tvaru XifXj. Notační variantou tohoto tvaru je synt. charakteristika tvaru Y'/Y, kde Y' je symbolem pasívní valentnosti (schopnosti dané synt. třídy být závislá na jisté jiné synt. třídě, třídách), Y symbolem aktivní valentnosti (schopnosti dané synt. třídy být [17]řídícím členem v jisté konfiguraci), z níž vychází postup G. S. Cejtina a L. N. Zasorinové (op. cit., 9—12).[31a] Máme-li řádky tvaru (4), získáme z nich symboliku Cejtina a Zasorinové takto: Předpokládejme, že máme (pro jednoduchost pouze) dvě řádky, kde X2 je jednou členem řídícím a jednou členem závislým:
X1 X2 : X2 (12)
X2 X3 : X3 (13)
Vypisujeme nyní postupně symboly synt. tříd (klaďme je přitom do závorek) a vlevo nebo vpravo (podle slovosledu) vypisujeme jejich valentnosti, a to nahoru valentnosti pasívní, dolů aktivní. Budeme mít tedy
|
|
| X3 |
|
| X2 |
|
|
|
|
|
| (X2) |
| (14); | (X1) |
| (15); |
| (X3) | (16) |
| X1 |
|
|
|
|
|
| X2 |
|
|
Nyní každou skutečnost, že v tomto soupisu jistý symbol je vpravo, vlevo, nahoře, dole u jistého symbolu označíme zvláštním, od ostatních symbolů různým symbolem, avšak tak, aby byl jistý konstantní vztah mezi tvary symbolu pro skutečnost, jako např. (15) a její „protějšek“
(X2) (17)
X1
Pak symbol pro skutečnost (17) bude symbolem aktivní valentnosti synt. třídy X2 a symbol pro skutečnost (15) symbolem pasívní valentnosti synt. třídy X1. Atd.
Seznam konfigurací — jako součást algoritmu — při tomto postupu není. Pro nedostatek místa nemůžeme jím provést analýzu ani naší jednoduché věty. Zjišťování konfigurací probíhá od začátku věty.
3.53. Synt. charakteristika tvaru XfZ (v nepřímé interpretaci). Tato symbolika vznikne malou úpravou Bar-Hillelovy kategoriální gramatiky,[32] která však jednak patří ke koncepci B, jednak má funkci (II) z 1.2. I když se dopouštíme jisté nesoustavnosti, budeme nejprve charakterizovat kategoriální gramatiku (přesnou definici viz Bar-Hillel aj., op. cit., 7—8).
Podstatou je to, že synt. charakteristiku sl. tvarů tvoří symbol třídy (tříd), s níž (s nimiž) může být synt. třída sl. tvaru v konfiguraci, a symbol synt. třídy, do níž patří celá konfigurace (v naší symbolice — Z). Bar-Hillel psal původně symboly v tvaru zlomku, a to tak, že symbol synt. třídy celé konfigurace je v čitateli, symbol synt. třídy druhého členu (druhých členů) konfigurace ve jmenovateli, přičemž jmenovatel je v závorce kulaté, stojí-li druhý člen konfigurace vlevo, a v závorce hranaté, stojí-li druhý člen konfigurace vpravo, tedy
. Lambek zavedl pohodlnější psaní zlomku, kde oba případy jsou odlišeny polohou zlomkové čáry, totiž [18]α\γ, resp. γ/α. Staršího způsobu Bar-Hillelova se přidržuje Revzin, který zavedl pro případy neustáleného slovosledu psaní čitatele bez závorek.[33]
Takto nepřímo nemohou být přirozeně charakterizovány všechny synt. třídy, aspoň jedna musí být charakterizována přímo. Seznam konfigurací není zapotřebí. Při postupu se uplatňují tzv. redukční pravidla, např.
(γ/α)α → γ (18)
γ(γ\α) → α (19)
(tj. posloupnost symbolů tvaru γ/α a α nahraď symbolem γ apod.). Analyzovaná S-struktura je uznána za gramaticky správně utvořenou větu, podaří-li se redukční pravidla uplatnit tak, aby konečným výsledkem postupné redukce S-struktury byl řádek jistého přesně vymezeného tvaru (srov. dále symbol s).
Naší úpravou přejde celý systém do koncepce A. Indexem označíme tu synt. charakteristiku, která označuje synt. třídu řídícího členu konfigurace. Přiřadíme tedy sl. tvarům v našem případě tyto symboly:
Dunn chooses electrical analogs
n1 [(n\s)'/nx]'2 (n/nx)3 nx4 (20)
(n — subst. sg., s — věta, nx — subst. pl.). Příslušným způsobem se musí upravit i redukční pravidla. Tak pravidlu (18) budou odpovídat
(γ/α)' k α(')l → γk (18')
(γ/α) k α(')l → γl (18''),
kdežto pravidlu (19) budou odpovídat
γ(')k (γ\α)'l → αl (19')
γ(')k (γ\α)l → αk (19''),
kde k a l jsou pořadová čísla synt. charakteristik v S-struktuře, (') znamená, že na indexu ' nezáleží. Analýza se provádí jako u Bar-Hillela s tím rozdílem, že po každé redukci v závislosti na přítomnosti nebo nepřítomnosti indexu ' přiřazujeme pořadovým (ve větě) číslům jednotlivých sl. tvarů pořadová čísla jejich sl. tvarů řídících.
Po prvním kroku (pravidlo 18'') zbude posloupnost n1 [(n\s)' nx]'2 n4x, čímž se zjišťuje electrical ← analogs [symbol (n/nx) je bez indexu], po druhém kroku (pravidlo 18') n1 (n\s)'2, čímž se zjišťuje chooses → analogs, po třetím [a posledním kroku — operace (19')] s, čímž se se zjišťuje Dunn ← chooses.
4. Koncepce B. Vzhledem k tomu, že je tato koncepce formálními metodami mnohem lépe prozkoumána, můžeme být velmi struční.
4.1. Z jejího hlediska jde při zjišťování synt. vztahů o to, zjistit zařazení jednotlivých sl. tvarů do hierarchie celků různých řádů (viz 2).
Vzhledem ke koncepci A je hlavním znakem koncepce B to, že analoga konfigurací (v A) mají v B tvar (4), avšak není nutné, aby buď Z = Xi, nebo Z = Xj, to znamená, že nelze tu říci, že např. Xi závisí na Xj, nýbrž, že posloupnost Xi Xj „je“ Z. Podle počtu X půjde o dvojčlennost, trojčlennost celků apod.[34] (srov. naproti tomu 2.2 o dvojčlennosti syntaktických vztahů v koncepci A).
[19]4.2. Ke klasifikaci obdobné té, kterou jsme uvedli v 3.3 a problematice s ní spojené, přistupuje tu klasifikace, jejímž dělícím principem je interpretace symbolu Z. Podle toho jsou možné dvě varianty koncepce B:
B1 — v každém řádku tvaru (4) je Z symbolem syntaktické třídy, která se vyskytuje aspoň v jedné S-struktuře; B2 — Z takovým symbolem být nemusí. Příklady na jednotlivé varianty: B1 — množinová koncepce O. S. Kulaginové,[35] B2 — větně strukturní gramatika (phrase structure grammar) N. Chomského[36] a soustava Y. Yngveho.[37]
4.3. Z nich ovšem jen poslední dvě jsou zaměřeny k synt. analýze pro účely SP (Bar-Hillel má však náročnější cíl, srov. 3.53), kdežto koncepce Kulaginové má nealgoritmický charakter[38] a větně strukturní gramatika je v pojetí Chomského jedním z typů tzv. generativní gramatiky, jejíž úkol je syntetickým protějškem úkolu (II) z 1.2, totiž produkce jen gramaticky správně utvořených vět daného jazyka (a žádných jiných posloupností sl. tvarů).[39]
Matematicky byla již dokázána ekvivalentnost kategoriální a větně strukturní gramatiky (Bar-Hillel, op. cit., 8n.) a přesvědčivě zjištěna i ekvivalentnost kategoriální gramatiky a množinového modelu Kulaginové (I. I. Revzin, op. cit. v pozn. 33).
5. Závěr. V 3.31 jsme vlastně naznačili problém, jak zjistit možné postupy (algoritmy) založené na koncepci A. Týž problém je ovšem i pro koncepci B a bylo by užitečné stavět jej pro jakoukoli takovou koncepci. Dále by bylo třeba obdobně probrat odstraňování homonymie a členění textu (srov. 1.1) a jejich vztahy.[40]
Pro podobná zkoumání je ovšem třeba — jak jsme se zde o to pokusili — nalézt hledisko dostatečně obecné, z něhož by bylo možno jednotně přehlédnout různé práce, jejichž skutečné vztahy — názorové shody a rozdíly — jsou zastřeny terminologickou a pojmovou nejednotností.
[20]R é s u m é
НЕКОТОРЫЕ ПРОБЛЕМЫ СИНТАКСИЧЕСКОГО АНАЛИЗА С ТОЧКИ ЗРЕНИЯ МАШИННОГО ПЕРЕВОДА
Синтаксический анализ в целях машинного перевода является одной из задач аналитического характера. От таких (и иных) задач, ставящих требования неодинаковой строгости, а иногда и неодинаковой целенаправленности к нашему познанию языка, следует отличать с одной стороны само описание, которое должно удовлетворять этим требованиям, с другой стороны определенные общие представления о структуре языка (или языка как целого, пли же какой — нибудь его части), находящие свое применение при описании и, наконец, определенное языковое или вообще символическое образование, выполняющее определенную задачу и опирающееся на адэкватное описание, в котором проявляется определенная концепция. Из синтаксического анализа в целях машинного перевода в данной статье расматривается только установление синтаксических отношений. Схемы алгоритмов установления этих отношений в общем основаны на двух известных концепциях, здесь называемых просто концепцией А — включающей в основном общие черты традиционной концепции о членах предложения и концепции о словосочетаниях — и концепцией Б — соответствующей, в основном, т. наз. анализу по непосредственно составляющим.
В статье рассматривается более подробно концепция А. Исходя из нее нужно при установлении синтаксических отношений установить для каждой зависимой словоформы соответствующую управляющую словоформу. Для того чтобы создать алгоритм, выполняющий эту задачу, необходимо а) обладать перечнем определенных синтаксических классов словоформ, б) перечнем элементарных синтаксических конструкций, т. наз. конфигураций (в терминологии синтаксических классов), в) известными познаниями о порядке слов.
Синтаксический анализ проводится не непосредственно на предложении, а на последовательности индексов, представляющих собой определенные синтаксические данные об отдельных словоформах. В статье ставится вопрос, чем могут быть представлены синтаксические данные о словоформах, если исходить из концепции А. Строчки в (б) могут иметь форму (5), где k — символ конфигурации, X, Z — символы синтаксических классов, ’ — обозначение управляющего члена конфигурации; (5) следовательно обозначает: в конфигурации к — Xi является зависимым, a Xj управляющим членом, вся конфигурация относится к синтаксическому классу Z. Функцию члена X, обозначенную присутствием/отсуствием зн. ’ будем обозначать символом f. Следовательно у нас имеется 5 элементов (к, Xi, Xj, Z, f), из которых мы можем составить всего 31 комбинацию от 1 до 5 классов. Некоторые из этих комбинаций представляют собой форму синтаксических данных, которые можно отнести к отдельным словоформам. Некоторые комбинации были уже использованы, некоторые нет, а некоторые невозможны в качестве синтаксических данных. Часть 3. 1—3. 4 является, в сущности, проектом частичной классификации схем алгоритмов синтаксического анализа для целей машинного перевода (классификация будет полной, когда и остальные части синтаксического анализа будут подобным образом рассмотрены).
Подобная проблематика возникает и для концепции Б и вообще для любой другой синтаксической концепции: необходимо установить все возможные схемы приемов, выполняющих определенную задачу и исходящих из определенной концепции.
[1] Článek vznikl z popudu akad. B. Havránka, který mě asi před dvěma léty vyzval, abych sestavil přehled aktuální syntaktické problematiky, zejména z hlediska strojového překladu. Časem však v čas. VJaz vyšly dvě výborné konzultace (N. A. Sljusarevové Lingvističeskij analiz po nepostredstvenno-sostavljajuščim, roč. 9, 1960, č. 6, 100—107 a T. M. Nikolajevové Čto takoje transformacionnyj analiz, roč. 9, 1960, č. 1, 116—120), které mi umožnily původní koncept značně zkrátit a soustředit se na věci méně osvětlené.
Při citacích se dále užívá těchto zkratek: Dokl. 61 — Doklady na konferencii po obrabotke informacii, mašinnomu perevodu i avtomatičeskomu čteniju teksta, Moskva 1961; Inf. Process. — Information Processing. Proceedings of the Intern. Conf. on Information Processing, UNESCO, Paris 15—20 June 1959, Paříž—Mnichov—Londýn 1960; ML — publikace cambridžské skupiny (The Cambridge Language Research Unit); MP — sb. Mašinnyj perevod, Moskva 1957; MPPL — sb. Mašinnyj perevod i prikladnaja lingvistika, Moskva; PK — sb. Problemy kibernetiki, Moskva; Tez. 58 — Tezisy konferencii po mašinnomu perevodu (15—21 maja 1958 goda), Moskva 1958.
V práci se počítá s literaturou uveřejněnou v publikacích přístupných v našich knihovnách do konce září 1961. Výjimku činí Tedd. — materiály The First Intern. Conf. on Machine Translation of Languages and Applied Language Analysis, Teddington (Middlesex), 5th — 8th Sept. 1961, k nimž jsme mohli přihlédnout jen v poznámkách.
[2] Srov. R. Carnap, Logische Syntax der Sprache, Vídeň 1934, 1.
[3] Existenci posledního požadavku bude patrně ještě po nějakou dobu třeba dosti zdůrazňovat. Strojový překlad vede nikoli k ignorování studia významu, nýbrž k přesnějšímu, objektivnějšímu jeho studiu. Viz V. A. Uspenskij, MPPL 1(8), 1959, 49.
[4] Viz např. V. Yngve, Sintaksis i problema mnogoznačnosti (překlad z angl.), MP, 287. Někteří sovětští lingvisté, navazujíce na myšlenky akad. Ščerby, snaží se využít „strojového“ přístupu pro metodiku vyučování cizím jazykům, viz I. I. Revzin, „Aktivnaja“ i „pasivnaja“ grammatika L. V. Ščerby i problemy mašinnogo perevoda, Tez. 58, 23—25; V. Ju. Rozencvejg, Mašinnyj perevod i nekotoryje voprosy metodiki prepodavanija inostrannych jazykov, Pytannja prykladnoji linhvistyky. Tezy dopovidej mižvuzivs’koji naukovoji konferenciji 22—28 veresnja 1960 roku, Černovice 1950, 13—14.
[Ostatně již při klasické metodě filologického rozboru textu v starých jazycích syntaktická analýza celku předcházela „porozumění“. BHk.]
[5] V některých překladových algoritmech, jako např. ve francouzsko-ruském algoritmu sestaveném v Steklovově matematickém ústavu AN SSSR v Moskvě (viz O. S. Kulagina a G. V. Vakulovskaja, Opytnyje perevody s francuzskogo jazyka na russkij na mašině „Strela“, PK 2, 1959, 283—288; O. S. Kulagina, O mašinnom perevode s francuzskogo jazyka na russkij I, PK 3, 1960, 181—208, II, PK 4, 1960, 207—257, III, PK 5, 1961, 245—262) není (a) nutné. Závisí to na vztazích mezi gramatickou stavbou příslušných jazyků, viz I. A. Meľčuk, K otázkám strojového překladu v Moskvě, SaS 20, 1959, 286.
[6] „Slovní tvar“, zkracujeme dále sl. tv. nebo sl. tvar, odpovídá rus. slovoforma (některé lexémy, např. adverbia mají tedy ovšem jen jeden sl. tvar).
[7] O častém zanedbávání rozdílu mezi oběma úkoly viz H. Hiż, Steps toward Grammatical Recognition, Preprint of paper to be presented before an Intern. Conf. for Standards on a Common Language for Machine Searching and Translation, Cleveland, Ohio, Sept. 6—12 1959, 1.
[8] Srov. např. R. B. Lees, rec. knihy N. Chomského Syntactic Structures, ’s-Gravenhague 1957, Language 33, 1957, 404. Jako přípravný stupeň k tomuto úkolu navrhl R. J. Solomonoff metodu takové analýzy — pro větně strukturní gramatiku (viz 4) — s účastí „učitele“ (v práci A New Method for Discovering the Grammars of Phrase Structure Languages, Inf. Process., 285—290). — Viz dále N. D. Andrejev, Strojový překlad, kap. 7 (překlad z rušt.); P. Garvin, Automatic Linguistic Analysis-A Heuristic Problem, Tedd., Paper 1.
[9] Viz např. L. Bloomfield, Language, London 1955, 210; L. Tesnière, Eléments de syntaxe structurale, Paris 1950, 19—20.
[10] S pomocí těchto pojmů se dají definovat pojmy: postavení začátkové, koncové a středové.
[11] Srov. I. I. Revzin, Formaľnyj i semantičeskij analiz sintaksičeskich svjazej v jazyke, sb. Primenenije logiki v nauke i technike, Moskva, 1960, 130—131 (srov. i rec. K. Berky O některých aplikacích moderní formální logiky v jazykovědě, SaS 22, 1961, 199).
[12] Srov. L. Tesnière, op. cit., 14.
[13] Níže položený sl. tv. ze dvou tvarů spojených úsečkou je závislým členem dvojice, výše položený jejím členem řídícím. (Z grafu lze rekonstruovat slovosled analyzované věty). Viz u nás V. Šmilauer, Novočeská skladba, Praha 1947, 415n.
[14] Obě tyto poslední koncepce se od sebe liší především terminologií a jejich použití je mnohdy spojeno s jistými uzancemi při postupu výkladu. Pro koncepci syntaktických (větných) dvojic je příznačné rozlišování různých typů synt. závislosti, srov. J. Bauer, Několik poznámek o pojmech slovní spojení, větná dvojice a syntagma, Sb. prací filos. fak. brn. univ. r. 1, č. 1—2, ř. jaz. (A), č. 1, zejm. 41—43. — Podle výše uvedeného omezení není v koncepci A např. protějšek větných členů s dvojí závislostí, srov. S. Ja. Fitialov, O modelirovanii sintaksisa dlja mašinnogo perevoda, Dokl. 61. vyp. 10, s. 10.
[15] Srov. O. S. Kulagina, O teoretiko-informacionnom podchode k izučeniju teoretiko-množestvennych modelej jazyka, MPPL 3, 1959, 95.
[16] Vedle grafické reprezentace větné stavby existuje ovšem mnoho jiných způsobů její reprezentace; tak s pomocí matic, různé způsoby lineárního zápisu s pomocí různých pomocných symbolů (závorek, svorek i běžných interpunkčních znamének apod.). Je důležité zjišťovat vztahy těchto různých reprezentací, protože mohou být nestejně vhodné pro jisté účely. — Z hlediska jisté algebraické reprezentace i reprezentace grafické vystihuje obecně vztah obou koncepcí Y. Lecerf, Une représentation algébrique de la structure des phrases dans diverses langues naturelles, Comptes rendus hebd. des séances de l’Acad. des sciences (Francie) 252, 1961, č. 2, 232—234. Výše uvedené pojetí vztahu obou koncepcí, k němuž jsme dospěli s B. Palkem při přípravě sdělení Uplatnění teorie grafů v syntaxi přirozených jazyků (pro seminář o teorii grafů pořádaný v Liblicích v květnu 1961 Matematickým ústavem ČSAV), je zhruba v souladu s Lecerfovou prací. Srov. dále zejména S. Ja. Fitialov, op. cit. — K různým reprezentacím srov. W. Plath, Automatic Sentence Diagramming, Tedd., Paper 2.
[17] Odhlížíme tu tedy od otázky, nakolik mohou při synt. analýze pomoci právě lexikální a frazeologické údaje.
[18] K termínu S-struktura srov. A. Jaurisová — M. Jauris, Užití teorie množin v jazykovědě, SaS 21, 1960, 35.
[19] Synt. třídy mohou, ale nemusí fungovat jako synt. charakteristiky, viz 3. 3.
[20] Viz K. E. Harper — D. G. Hays, The Use of Machines in the Construction of a Grammar and Computer Program for Structural Analysis, Inf. Process., 191.
[21] K symbolice srov. S. M. Lamb, On the Mechanization of Syntactic Analysis, Tedd., Paper 21, s. 5.
[22] Jsou však možné i jiné způsoby, srov. např. symboliku T. N. Mološné Algoritm perevoda s anglijskogo jazyka na russkij, PK 3, 209—272, zvl. 253n., kde je řídícím členem konfigurace ten, jehož tvar symbolu má jistý vztah k tvaru symbolu Z. Např. konfigurace 2+Pm : 2- (2+ — přechodné osobní sloveso, Pm — osobní zájmeno v předmětovém pádu, 2- — nepřechodné osobní sloveso), kde řídícím členem je 2+.
[23] Celkem 31 kombinací 1. až 5. třídy. Z takto vytvořených kombinací můžeme pak pro naše účely ztotožnit ty, které se od sebe navzájem liší jen tím, že je v jedné Xi a v druhé Xj, tedy např. kXi = kXj. Jak se lze snadno přesvědčit, zbude celkem 23 kombinací, totiž 4 kombinace 1. třídy, 7 kombinací 2. třídy, 7 kombinací 3. třídy, 4 kombinace 4. třídy a 1 kombinace 5. třídy.
[24] K. E. Harper — D. G. Hays, l. c.; S. Ja. Fitialov, op. cit., 5; srov. i jiné pravidlo u G. S. Cejtina a L. N. Zasorinové O vydelenii konfiguracij v russkom predloženii, Dokl. 61, vyp. 2., s. 9. — Viz dále W. Plath, Automatic Sentence Diagramming, Tedd., Paper 2, s. 7n.
[24a] I tu jsou možné různé modifikace.
[25] Budeme postupovat podle systému T. N. Mološné Nekotoryje voprosy sintaksisa v svjazi s mašinnym perevodom s anglijskogo jazyka na russkij, VJaz 1957, č. 4, 92—97, Algoritm perevoda s anglijskogo jazyka na russkij, PK 3, 1960, 209—272. — K tomuto typu v zásadě patří velký počet publikovaných přístupů: tak I. K. Belskaja, Machine Translation Methods and Their Application to an Anglo-Russian Scheme, Inf. Process., 199—217; G. H. Mathews — S. Rogovin, German Sentence Recognition, Mechanical Translation 5, 1958, č. 3, 114—120; N. D. Andrejev, op. cit., kap. 5; T. M. Nikolajeva, Struktura algoritma grammatičeskogo analiza (pri MP s russkogo jazyka), MPPL 5, 1961, 27—44. V některých se začíná od členů závislých, v jiných od členů řídících.
[26] Zvolili jsme příklad tak jednoduchý, že je možno se synt. homonymií, tj. v podstatě s přiřazením jednomu sl. tvaru více než jedné synt. charakteristiky, a s jejím odstraňováním, tj. se zjišťováním, která charakteristika je jedině vhodná pro danou konkrétní větu, téměř nepočítat. — V 3.521 jsme toho dosáhli tím, že udáváme jen konfigurace č. 7 a 12, avšak v S-struktuře (20) jsme musili pro jednoduchost např. sl. tvaru electrical přiřadit arbitrárně charakteristiku (n/nx), ačkoli bychom mu měli přiřadit i charakteristiku (n/n) a ještě některé další.
[27] Srov. pozn. 22. Apostrof u řídícího členu je tu suplován příbuzností tvaru symbolu řídícího členu k symbolu z pravé strany řádky.
[28] Harper-Hays, op. cit., 191: „… jsou-li X, Y symboly ve větě, XpY znamená, že X předchází Y, a XdY znamená, že X závisí na Y“. A dále: „Jestliže WdXd … dY dZ, říkáme, že je W „odvozeno z“, X, …Y a Z; žádný symbol X nezávisí na sobě samém, ale každé konkrétní X je ze sebe odvozeno.“ (Překlad není zcela věrný, v originálu jde při X,Y apod. o konkrétní sl. tvary (occurences), zde již o symboly synt. tříd.)
[29] Jiným typem postupu „text-systém“, a to „zleva doprava“, je patrně tzv. prediktivní synt. analýza, viz např. M. E. Sherry, The Identification of Nested Structures in Predictive Syntactic Analysis, Tedd., Paper 18.
[30] Viz A. F. Parker-Rhodes, R. Mc Kinnon Wood, M. Kay, P. Bratley, The Cambridge Language Research Unit Computer Program for Syntactic Analysis, ML 136, 1—86.
[31] Symbol 0 v řádku u jistého sl. tvaru a v sloupci n znamená, že sl. tvar se v konfiguraci n vyskytnout nemůže, 1 — že se v ní může vyskytnout jen jako člen závislý, 2 — jako člen řídící, 3 — jako obojí. Pro náš jednoduchý případ stačí údaje o 7. (nominální) a 12. („free clauses“) konfiguraci. Jinak silně zjednodušujeme. Systém cambridžské skupiny má ve skutečnosti 12 konfigurací, k synt. charakteristice sl. tvaru patří dále symbol možné jeho pozice v dané konfiguraci a údaje o shodě.
[31a] Srov. dále L. N. Zasorina, V. P. Berkov, Ponjatije valentnosti v jazyke, Vestnik len. univ. 1961, č. 8, ser. ist., jaz. i lit. 2, 137n.
[32] Y. Bar-Hillel, C. Gaifman, E. Shamir, On Categorial and Phrase-Structure Grammar, Bull. of the Research Council of Israel 9F, No. 1, June 1960, 1—16. Základní myšlenky pocházejí od K. Ajdukiewicze O spojności syntaktycznej, sb. Język i poznanie I, 1960, 222—246, původně Die syntaktische Konnexität, Studia philosophica 1, 1935, 1—27. Na syntax je poprvé aplikoval Y. Bar-Hillel, A Quasi-Arithmetical Notation for Syntactic Description, Language 29, 1953, 47—58, srov. i L. a A. Wundheilerové Nekotoryje ponjatija logiki v primenenii k sintaksisu (překlad z angl.), MP, 261—266. Z matematického hlediska studuje kategoriální gramatiku také J. Lambek v stati The Mathematics of Sentence Structure, Amer. Mathem. Monthly 65, 1958, 154—170. Viz dále R. P. Mitchell, A Note on Categorial Grammars, Tedd., Paper 24. — Výklad Ajdukiewiczových myšlenek je podán i v stati V. Illenčíka O logickej stavbe jazyka, Slovenský filoz. čas. 13, 1958, č. 4, 320—345, avšak kupodivu bez náležitého poznámkového aparátu.
[33] Ustanovlenije sintaksičeskich svjazej v MP metodom Ajdukeviča-Bar-Chillela i v terminach konfiguracionnogo analiza, Dokl. 61, vyp. 2, s. 4. — Celý způsob tohoto zápisu se dá pojmout jako interpretace tzv. funkcionality v kombinatorické logice, viz H. B. Curry - R. Feys - W. Craig, Combinatory logic 1, Amsterodam 1958, 274—275.
[34] Srov. však N. Chomsky, On Certain Formal Properties of Grammars, Information and Control 2, 1959, 149 (teorém 5).
[35] Ob odnom sposobe opredelenija grammatičeskich ponjatij na baze teorii množestv. PK 1, 1958, 203—214, u nás dobře známá z výkladů A. a M. Jaurisových, op. cit. v pozn. 18. Viz i poněkud odlišné výklady I. I. Revzina O nekotorych ponjatijach tak nazyvajemoj teoretiko-množestvennoj koncepcii jazyka, VJaz 9, 1960, č. 6, 88—94 a další rozvití I. I. Revzin, op. cit. v pozn. 11.
[36] Např. Syntactic Structures, kap. 4; op. cit. v pozn. 34; Y. Bar-Hillel, op. cit. v pozn. 32, S. Scheinberg, Note on the Boolean Properties of Context Free Languages, Information and Control 3, 1960, 372—5.
[37] Op. cit. v pozn. 4, s. 297—304.
[38] Srov. A. A. Zinov’jev - I. I. Revzin, Logičeskaja model’ kak sredstvo naučnogo issledovanija, Vopr. filosofii 14, 1960, č. 1, 87.
[39] Zjednodušenou variantou synt. analýzy podle koncepce B je i systém A. D. Stathacopoulose A Possible Application of Electronic Computers to the Block Analysis of Greek Sentences, Linguistic and Engineering Studies in Automatic Language Translation of Scientific Russian into English, Part II, Seattle 1960, 449—474.
[40] Přestože byly o použitelnosti obou koncepcí pro účely SP vysloveny značně skeptické názory, viz zejména Y. Bar-Hillel, Some Linguistic Obstacles to Machine Translation, 2e congrès intern. de cybern. Namure, 3—10 Sept. 1958, Namure 1960, M. Corbe — R. Tabory, Introduction to an Automatic English Syntax (by Fragmentation), Tedd., Paper 35, je založena většina známých algoritmů právě na nich. — Problematiku tzv. transformační analýzy probereme při jiné příležitosti.
Slovo a slovesnost, volume 23 (1962), number 1, pp. 9-20
Previous Jiří Levý: Izochronie taktů a izosylabismus jako činitelé básnického rytmu
Next Roman Mrázek: K otázce českých větných schémat a typů, zvláště neslovesných
© 2011 – HTML 4.01 – CSS 2.1