
Některé vlastnosti entropie českého slovníku
Květa Korvasová, Bohumil Palek
[Discussion]
Некоторые свойства энтропии чешского словаря / Quelques particularités de l’entropie du vocabulaire tchèque
Veškeré údaje ukládané do samočinného počítače, např. při strojovém překladu, musí být co nejoptimálněji zakódovány, tj. musí zaujímat co nejmenší část paměti stroje. To platí nejen o údajích gramatických, ale i o jednotlivých slovech jak ve slovníku, tak v textu. Volba optimálního kódování vyžaduje zjištění základních vlastností struktury slovníku, které vyplývají z kvantitativních charakteristik kódovaných symbolů (tj. písmen nebo kombinací písmen). Dílčím problémem je tu zjištění vztahu mezi délkou „kmenů“ a entropií[1] jejich písmen, jehož výsledky v našem článku přinášíme.
[59]Optimální kódování je běžně spjato s problematikou identifikace textových slovních tvarů se slovy slovníku, uloženém v paměti počítače (vyhledání ze slovníku) při strojovém překladu. Dosud se nejběžněji slovník v stroji řadil abecedně, podle frekvence apod. Přes snahy o toto ekonomické uspořádání slovníku se ukázalo, že čas, který potřebuje stroj, aby vyhledal slovo ze slovníku (strojový čas), v průměru podstatně převyšuje strojový čas ostatních fází překladu (např. zpracování morfologických a syntaktických údajů). Proto jsme přistoupili k racionálnějšímu postupu, k tzv. „přímé metodě“ vyhledávání ze slovníku.[2] Tato metoda spočívá v tom, že z části slova v kódu počítače je vytvořena adresa (tj. písmena v kódu počítače jsou vyjádřena numericky), na níž jsou ve stroji uloženy gramatické údaje o daném slově.
Např.
| slovo | kód počítače EPOS I | adresa | gram. údaje |
| kombinac(e) dodáv(at) | 2936331326341014 1636161156 | 2936 1636 | subst., fem. apod. verb. |
(Adresou zde jsou zvoleny prvé čtyři dekadické číslice.)
Použití přímé metody je výhodnější než ostatní metody, ačkoli i ona je spojena s některými potížemi, jako je např. slovníková homonymie, ekonomické obsazení paměti stroje apod. Výhody přímé metody spočívají především v tom, že umožňuje větší rychlost překladu strojem a že klade menší nároky na kapacitu paměti stroje.
Formulace postupu pro vytváření adresy vyžaduje zhuštění kódu slova na číslo odpovídající adrese paměti (adresy paměti mohou být např. v rozmezí 0001—4096), a to takové, aby slovník byl uložen na souvislé části paměti počítače. Tento postup je vhodný proto, že nečiní potíže při programování.
Výzkum optimálního kódování češtiny jsme prováděli na základě statistiky písmen a kombinací písmen v elektrotechnickém slovníku češtiny.[3] Slovník, který byl za tím účelem sestaven, je slovník „kmenů“. Za „kmen“ považujeme neměnnou část slova, kmeny s hláskovými alternacemi pokládáme za kmeny různé. Tak byly do slovníku pojaty „kmeny“ např. v této podobě: zhodnocení, kyvadl, kyvadel, instruktor, instruktoř, poločlánek, poločlánk atd.
K sestavení slovníku bylo použito existujících technických slovníků (především Česko-ruského technického slovníku, Praha 1960, Československé státní normy), z nichž byla vybrána slova, resp. kmeny užívané v elektrotechnice. Kromě toho byl slovník doplněn kmeny běžného slovníku dvojjazyčného (B. Vydra, Česko-polský slovník, Praha 1953, jeho českou částí) a excerpováním elektrotechnických textů (z děl časopiseckých a knižních). Slovník přestal být doplňován tehdy, když přírůstek nových kmenů byl nepatrný. Tak byl získán slovník, který vedle speciálních základních elektrotechnických termínů tvoří i termíny obecně technické a odborné a konečně slova („kmeny“) běžného slovníku. Slovník obsahuje celkem 12 229 kmenů.
Při statistickém zpracovávání takto získaného materiálu se zjišťoval výskyt písmen v jednotlivých pozicích jednak vzhledem k délce kmene, jednak vzhledem k prvnímu písmenu. Dále byl [60]zjišťován výskyt kombinací dvou písmen v jednotlivých pozicích i vzhledem k délce kmene. Celkem bylo zpracováno 88 658 písmen, takže průměrná délka kmene je 7,25 písmene.
Postup při zpracovávání statistického materiálu. Při výpočtu entropie jsme vycházeli ze statistického zpracování výskytu písmen v jednotlivých pozicích vzhledem k délce kmene. Počítali jsme entropii písmene (symbolu) v jednotlivých pozicích:[4]
I. a) pro všechna písmena [tj. písmena b) c) d)],
II. b) pro samohlásky,
c) pro sonanty (j, l, m, n, ň, r, ř),
d) pro ostatní souhlásky [tj. všechny souhlásky kromě souhlásek typu c)].
Každá skupina kmenů délky d (pro d = 3, 4, 5, … 16 písmen) zahrnuje m(d) písmen. Počet písmen abecedy je n = 41.
Každému písmenu je přiřazen index k takto:
| písmeno k | a 1 | á 2 | e 3 | é 4 | ě 5 | i 6 | í 7 | o 8 | ó 9 | u 10 | ú 11 | ů 12 | y 13 | ý 14 |
| písmeno k | b 15 | c 16 | č 17 | d 18 | ď 19 | f 20 | g 21 | h 22 | k 23 | p 24 | q 25 | s 26 | š 27 | t 28 |
| písmeno k | ť 29 | v 30 | w 31 | x 32 | z 33 | ž 34 | j 35 | l 36 | m 37 | n 38 | ň 39 | r 40 | ř 41 |
|
Entropie symbolu, která je v podstatě průměrným množstvím informace, byla počítána podle vzorce
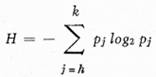
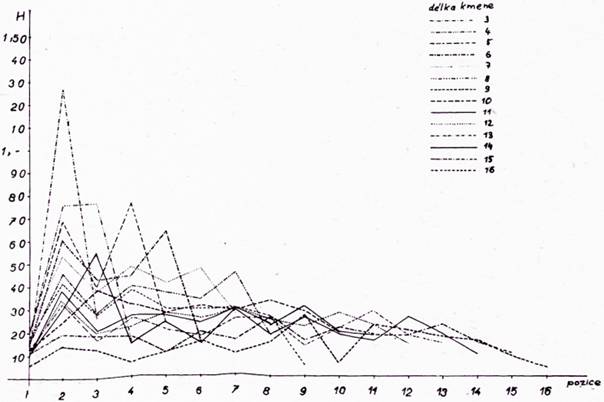
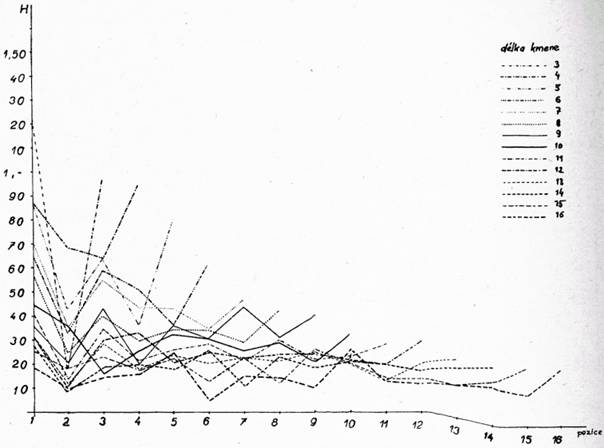
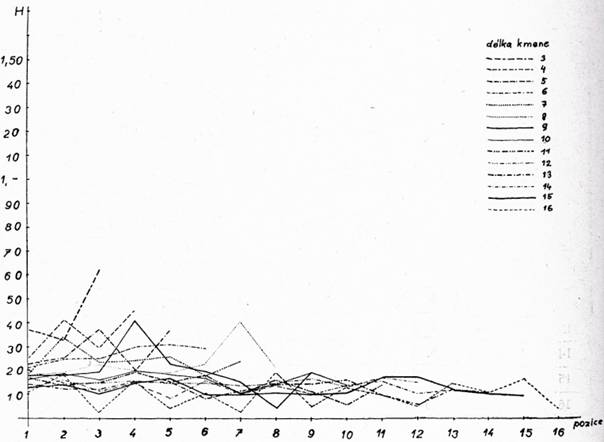
kde pj je relativní četnost písmen. Pro skupinu a) h = 1 a k = 41, pro b) h = 1, k = 14, pro c) h = 35, k = 41, pro d) h = 15, k = 34. Entropie v jednotlivých pozicích skupin d = 3, 4, 5 … 16 jsou zachyceny v grafech, viz obr. 1, 2, 3, 4 pro skupiny a), b), c), d).
Těsnost vztahu mezi délkou kmene d a entropií H určuje korelační koeficient. Korelační koeficienty a koeficienty regrese byly vypočteny pro skupiny a) b) c) a d) z korelačních tabulek (tab. 1, 2, 3, 4).
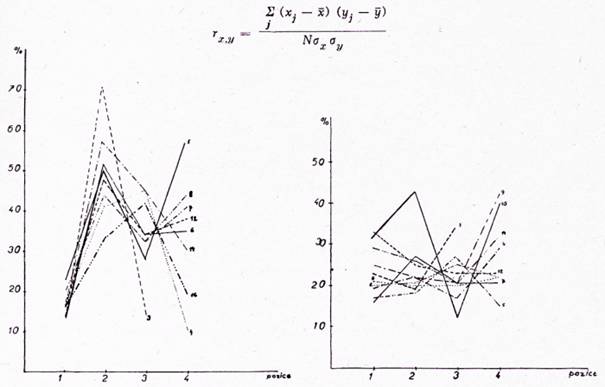
Entropie jednotlivých skupin (tj. b, c, d) jsou částmi entropie celkové (skupina a), tj. Ha = Hb + Hc + Hd. V grafech b, c, d, kde jsou vyneseny Hb, Hc, Hd v jednotlivých pozicích, jsou jasně patrny rozdíly v částech entropie Ha a v jednotlivých pozicích. Poměr částí entropie Hb, Hc, Hd k celkové entropii Ha, vyjádřený v procentech, je na obr. 5.
Entropie pro jednotlivou skupinu písmen [tj. b) c) d)] jsou definovány
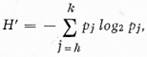
kde 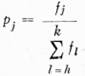 , kde fj jsou četnosti písmen příslušné skupiny. Tyto entropie vyšetřovány nebyly.
, kde fj jsou četnosti písmen příslušné skupiny. Tyto entropie vyšetřovány nebyly.
[61]
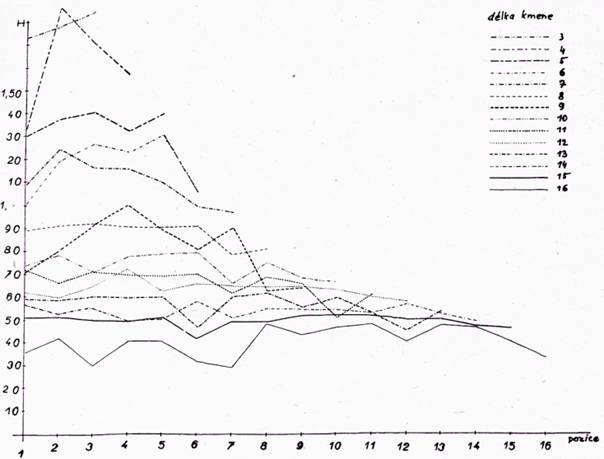 Obr. č. 1
Obr. č. 1
 Obr. č. 2
Obr. č. 2
[62]
 Obr. č. 3
Obr. č. 3
 Obr. č. 4
Obr. č. 4
| [63]H d | 0,4 | 0,6 | 0,8 | 1,0 | 1,2 | 1,4 | 1,6 | 1,8 | 2,0 |
| 3 |
|
|
|
|
|
|
| 2 | 1 |
| 4 |
|
|
|
|
| 1 | 1 | 1 | 1 |
| 5 |
|
|
|
|
| 4 | 1 |
|
|
| 6 |
|
|
|
| 3 | 3 |
|
|
|
| 7 |
|
|
| 2 | 4 | 1 |
|
|
|
| 8 |
|
| 1 | 7 |
|
|
|
|
|
| 9 |
| 3 | 6 |
|
|
|
|
|
|
| 10 |
|
| 10 |
|
|
|
|
|
|
| 11 |
| 2 | 9 |
|
|
|
|
|
|
| 12 |
| 3 | 9 |
|
|
|
|
|
|
| 13 |
| 11 | 2 |
|
|
|
|
|
|
| 14 |
| 14 |
|
|
|
|
|
|
|
| 15 |
| 15 |
|
|
|
|
|
|
|
| 16 | 6 | 10 |
|
|
|
|
|
|
|
Tab. 1 Písmena a)
| H d | 0,1 | 0,2 | 0,3 | 0,4 | 0,5 | 0,6 | 0,7 | 0,8 | 0,9 | 1,0 | 1,1 | 1,2 | 1,3 |
| 3 |
| 1 |
|
|
|
|
|
|
| 1 |
|
| 1 |
| 4 |
|
|
|
|
|
| 2 |
| 1 | 1 |
|
|
|
| 5 |
|
|
| 1 | 1 |
| 1 | 1 | 1 |
|
|
|
|
| 6 |
|
|
| 2 |
| 2 | 2 |
|
|
|
|
|
|
| 7 |
|
|
| 2 | 3 | 1 |
| 1 |
|
|
|
|
|
| 8 |
|
| 2 | 3 | 2 | 1 |
|
|
|
|
|
|
|
| 9 |
| 1 | 1 | 4 | 3 |
|
|
|
|
|
|
|
|
| 10 |
| 1 | 4 | 4 | 1 |
|
|
|
|
|
|
|
|
| 11 |
| 1 | 7 | 2 | 1 |
|
|
|
|
|
|
|
|
| 12 |
| 2 | 8 | 2 |
|
|
|
|
|
|
|
|
|
| 13 |
| 4 | 8 | 1 |
|
|
|
|
|
|
|
|
|
| 14 | 1 | 5 | 8 |
|
|
|
|
|
|
|
|
|
|
| 15 |
| 9 | 6 |
|
|
|
|
|
|
|
|
|
|
| 16 | 1 | 12 | 3 |
|
|
|
|
|
|
|
|
|
|
Tab. 2 Písmena b)
| [64]H d | 0,1 | 0,2 | 0,3 | 0,4 | 0,5 | 0,6 | 0,7 | 0,8 | 0,9 | 1,0 | 1,1 | 1,2 | 1,3 |
| 3 |
|
|
| 2 |
|
| 1 |
|
|
|
|
|
|
| 4 |
|
| 2 |
| 2 |
|
|
|
|
|
|
|
|
| 5 |
| 1 | 2 | 2 |
|
|
|
|
|
|
|
|
|
| 6 |
|
| 5 | 1 |
|
|
|
|
|
|
|
|
|
| 7 |
| 2 | 4 | 1 |
|
|
|
|
|
|
|
|
|
| 8 |
| 4 | 3 |
| 1 |
|
|
|
|
|
|
|
|
| 9 | 1 | 5 | 2 | 1 |
|
|
|
|
|
|
|
|
|
| 10 |
| 10 |
|
|
|
|
|
|
|
|
|
|
|
| 11 | 1 | 10 |
|
|
|
|
|
|
|
|
|
|
|
| 12 |
| 11 | 1 |
|
|
|
|
|
|
|
|
|
|
| 13 | 1 | 12 |
|
|
|
|
|
|
|
|
|
|
|
| 14 | 1 | 13 |
|
|
|
|
|
|
|
|
|
|
|
| 15 | 2 | 13 |
|
|
|
|
|
|
|
|
|
|
|
| 16 | 6 | 10 |
|
|
|
|
|
|
|
|
|
|
|
Tab. 3 Písmena c)
| H d | 0,1 | 0,2 | 0,3 | 0,4 | 0,5 | 0,6 | 0,7 | 0,8 | 0,9 | 1,0 | 1,1 | 1,2 | 1,3 |
| 3 |
| 1 | 1 |
|
|
|
|
|
|
|
|
| 1 |
| 4 |
| 1 | 1 |
|
|
|
| 2 |
|
|
|
|
|
| 5 |
|
| 2 | 1 |
|
| 1 | 1 |
|
|
|
|
|
| 6 |
| 2 |
|
| 2 |
| 2 |
|
|
|
|
|
|
| 7 |
|
| 2 | 1 | 3 | 1 |
| 1 |
|
|
|
|
|
| 8 |
| 2 | 1 | 3 | 2 |
|
|
|
|
|
|
|
|
| 9 | 1 | 1 | 4 | 2 | 1 |
|
|
|
|
|
|
|
|
| 10 |
| 2 | 4 | 4 |
|
|
|
|
|
|
|
|
|
| 11 |
| 2 | 6 | 3 |
|
|
|
|
|
|
|
|
|
| 12 |
| 2 | 9 | 1 |
|
|
|
|
|
|
|
|
|
| 13 |
| 6 | 9 | 1 |
|
|
|
|
|
|
|
|
|
| 14 |
| 9 | 4 | 1 |
|
|
|
|
|
|
|
|
|
| 15 |
| 12 | 3 |
|
|
|
|
|
|
|
|
|
|
| 16 | 5 | 7 | 3 |
|
|
|
|
|
|
|
|
|
|
Tab. 4 Písmena d)
[65]Korelační analýza se zabývá určením těsnosti vztahu mezi proměnnými a určením nejpravděpodobnějšího vztahu mezi nimi. Pro dvě proměnné x a y je korelační koeficient definován výrazem
 Entropie Hb Hc
Entropie Hb Hc
Obr. č. 5
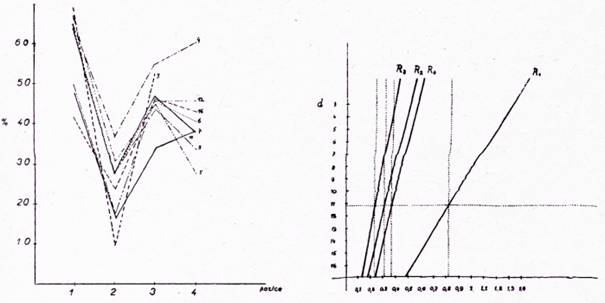 Hd H
Hd H
Obr. č. 5 Obr. č. 6
[66]kde ![]() a σx, σy jsou směrodatné odchylky, které jsou kladnými odmocninami rozptylu, kde rozptyl je průměr čtverců odchylek od průměru
a σx, σy jsou směrodatné odchylky, které jsou kladnými odmocninami rozptylu, kde rozptyl je průměr čtverců odchylek od průměru
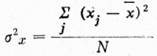
K odhadu, o jaký stupeň těsnosti vztahu jde, zpravidla lze užít této stupnice koeficientu korelace, který je v mezích od 0 do ±1.
Pro[5]
|
0,3 ≥ 0,5 ≥ 0,7 ≥
| rx,y rx,y rx,y rx,y rx,y | < 0,3 je nízký stupeň těsnosti vztahu, < 0,5 je mírný stupeň těsnosti vztahu, < 0,7 je význačný stupeň těsnosti vztahu, < 0,9 je vysoký stupeň těsnosti vztahu, ≥ 0,9 je velmi vysoký stupeň těsnosti vztahu. |
Druhá část korelační analýzy se zabývá měřením nejpravděpodobnějšího typu vztahu. Jde-li o lineární vztah mezi proměnnými, je rovnice přímky
![]()
kde ![]() je směrnicí přímky a nazývá se koeficient regrese.
je směrnicí přímky a nazývá se koeficient regrese.
Pro skupinu a), tj. všechna písmena, lze z koeficientu korelace rd,H = — 0,86 usuzovat, že mezi délkou kmene a entropií je těsnost vztahu vysoká, a z regresního koeficientu bH,d plyne, že změně délky kmene o 1 písmeno odpovídá změna průměrné entropie o 0,075. Příslušná regresní přímka R1 ≡ H — 0,82 = — 0,075 (d — 11,2) — je na obr. 6.
Pro skupinu b), tj. samohlásky, lze usuzovat, že mezi d a H je těsnost vztahu význačná (rd,H = — 0,69). Změně délky kmene o jedno písmeno odpovídá změna průměrné entropie o 0,031. Příslušná regresní přímka R2 ≡ H — 0,31 = — 0,031 (d — 11,2) — je na obr. 6.
Pro skupinu c), tj. sonanty, je těsnost vztahu mezi d a H vysoká (rd,H = — 0,89) a změně délky kmene o jedno písmeno odpovídá změna průměrné entropie o 0,018. Příslušná regresní přímka R3 ≡ H — 0,23 = — 0,018 (d — 11,2) — je na obr. 6.
Pro skupinu d), tj. souhlásky, je těsnost vztahu vysoká (rd,H = — 0,74). Změně délky kmene o jedno písmeno odpovídá změna entropie o 0,036.
Příslušná regresní přímka R4 ≡ H — 0,36 = — 0,038 (d — 11,2) — je na obr. 6.
Závěr. Existující vztah mezi entropií písmen a délkou kmenů ukazuje, že při optimálním kódování je třeba zvolit jiný postup pro slova kratší (písmena v těchto kmenech a v jednotlivých pozicích mají větší množství informace) než pro slova delší.
Entropie ve vyšších pozicích se vyrovnávají; v grafech nejsou výrazná maxima ani minima a tyto entropie jsou nízké. Naopak v nižších pozicích jsou entropie vyšší a významně se od sebe liší. Z těchto důvodů není vhodné při optimálním kódování slov úplně vynechávat začátek slova, ani ho příliš zkracovat.
Vedle těchto poznatků bylo zjištěno a je také patrno z grafů, že entropie závisí na pozici a na skupině (b, c, d). Např. písmena skupiny b) mají většinou maxima v pozicích sudých a písmena skupiny d) naopak v pozicích lichých. Z této skutečnosti vyplývá, že jde o těsný vztah dvojic písmen, který bude nutno podrobit zkoumání.
[1] Entropie je definována podle Shannona vzorcem
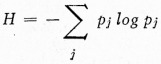
Je to průměrná míra informace, jejíž veličina je mírou neurčitosti a závisí na rozložení pravděpodobností. H = Ø tehdy a jen tehdy, když všechny pravděpodobnosti, vyjma jednu, jsou rovny nule a tato jedna pravděpodobnost je rovna jedné. V takovém případě není žádná volnost výběru. Ve všech ostatních případech je entropie kladná. (Srov. S. Goldman, Teorija informacii [překlad z angl.], Moskva 1957, 55.).
[2] Termín přímá metoda je překlad angl. direct method. Srov. Michael Levison, The Application of the Ferranti Mercury Computer to Linguistic Problems, Information and Control 3, 1960, 231—247; P. Meile, On Problems of Adress in an Automatic Dictionary of French, Preprints of the First International Conference on Machine Translation of Languages and Applied Language Analysis, National Physical Laboratory, Teddington, 5th—8th September 1961.
[3] Dosavadní práce týkající se češtiny: B. Trnka, Pokus o vědeckou teorii a praktickou reformu těsnopisu, Praha 1937; J. Vachek, Poznámky k fonologii českého lexika, LF 67, 1940, 395n.; F. Kroutl, Teorie informace ve spojích, Praha 1960, zejm. 101n., zabývají se především otázkami fonologickými a rozborem souvislých textů. Pro optimální kódování češtiny jich bezprostředně využito být nemohlo, protože uplatnění přímé metody při vyhledávání ze slovníku předpokládá statistický výzkum (na základě písmen a kombinací písmen) systému slovníku.
[4] Názvem samohláska, souhláska, sonant označujeme zde pouze písmena, nikoli hlásky nebo fonémy. — Naše zkoumání se týkalo zjišťování rozdílů mezi uvedenými třemi skupinami písmen. Rozklady na jiné skupiny jsme zatím neprováděli. Rozklad na skupiny b), c), d) byl zvolen jednak z důvodů lingvistických, jednak proto, že při výpočtu množství informace se ukázaly nápadné shody skupiny c) se skupinou b), které spočívaly v tom, že množství informace v těchto skupinách bylo menší než ve skupině d).
[5] Srov. J. Janko, Matematická statistika I, Praha 1949, 89.
Slovo a slovesnost, volume 23 (1962), number 1, pp. 58-66
Previous František Kopečný: Česká mluvnice
Next Jitka Štindlová: Uplatňování metod mechanizace a automatizace v lexikologické práci v zahraničí
© 2011 – HTML 4.01 – CSS 2.1