
O délce věty
Ludmila Uhlířová
[Articles]
О длине предложения / Sur la longueur de la phrase
I. Uživatel jazyka má k dispozici mnoho možností užívat různou měrou vět rozličné délky ve svých jazykových projevech, od vět velmi krátkých až po věty neobvykle dlouhé, a to jak se zřením k funkci jazykového projevu, tak i v závislosti na individuálních slohových činitelích. Délka věty je potenciální stylovou charakteristikou. Pomocí statistických dat o délce věty lze určitým způsobem stylově charakterizovat jak text, tak i autora, popř. funkční styl. Je to veličina snadno vymezitelná (J. Mistrík nazývá délku věty její „fyzickou“ vlastností[1]) a dobře měřitelná, zejm. pokud měřenou jednotkou je větný celek „od tečky k tečce“ a jednotkou, v níž se délka měří, slovo jakožto jednotka grafická. Navíc při automatické analýze textů lze údaje o větné délce mnohdy získat snadno jako vedlejší produkt analýzy. Délka věty je též nejjednodušším prostředkem kvantitativní charakteristiky vyšších rovin jazyka (roviny věty).
To vše vysvětluje, proč se délkou věty zabývají lingvisté i filologové již téměř po celé století. Např. anotovaná bibliografie[2] z roku 1968 uvádí práce Shermanovy, Gerwigovy, Poundovy, Hildrethovy a Moritzovy, které byly publikovány již koncem 19. a v prvním desetiletí 20. stol. Na některé z těchto prací se navazuje podnes, a to jak na myšlenky v nich obsažené, tak i na jazykový materiál v nich analyzovaný (včetně číselných dat). Tak např. Sherman v práci o vývoji délky věty v angličtině od Chaucera po Bartola[3] (na materiále z děl 15 autorů z různých období) shledal, že vývoj směřuje od jednodušších větných konstrukcí ve prospěch konstrukcí sevřenějších („more syncopated“). Tato základní vývojová tendence k větší strukturní složitosti a tím i větší délce věty (pojímané jako jednotka s jedním predikátem) a opačná tendence ke snižování počtu vět ve větném celku (souvětí) je statisticky prokázána také pro další jazyky, např. pro češtinu období baroka, pro polštinu období renesance a pro němčinu.[4]. Shermanovu tabulku s údaji o tzv. rozsahu predikace („extent of predication“), tj. o průměrném počtu vedlejších vět v souvětí ve starších a novějších anglických textech přetiskuje G. Herdan.[5] Probíráme-li dnes už poměrně bohatou literaturu o délce věty, shledáváme, že stylová povaha, resp. relevance tohoto parametru je různými autory rozličně pojímána i vykládána. Žádný z autorů sice nepopírá, že data o délce věty mohou poskytnout lingvisticky užitečnou informaci o stylu analyzovaného materiálu, avšak rozcházejí se v podrobnějších názorech na povahu a dosah těchto informací. Jde ovšem také o relevanci z hlediska synchronního nebo diachronního. Existují navzájem [233]velmi odlišné, mnohdy protichůdné, ba polemicky laděné způsoby lingvistické interpretace dat o větné délce. Známá je tu např. polemika K. R. Bucha s C. B. Williamsem.[6] Proti Williamsovi, který tvrdí, že rozložení délky věty je distinktivním rysem autora, Buch ukazuje (na rozboru dvou děl dánského spisovatele J. V. Jensena, napsaných v rozpětí dvaceti let), že rozložení délky věty se u autora může měnit s časem. — Na klasickou práci Yulovu,[7] v níž se délky věty užívá jako charakteristiky individuálního stylu a pomocí níž se rozhoduje o sporném autorství dopisů Juniových, reaguje Herdan (o. c. v pozn. 5) tvrzením, že filologická (literární) identita autorství není vždy odrážena statistickou identitou větné délky a naopak, literární různost není vždy odrážena statistickou růzností. — Za úvahu stojí např. také otázka položená Mistríkem (o. c. v pozn. 1), zda věty všech délek (tedy i těch délek, které se vyskytují ve všech jazykových projevech) jsou svou délkou stylisticky příznakové. Mistrík soudí, že stylisticky příznakové jsou pouze věty (predikační jednotky) kratší než čtyři slova a delší než deset slov, zatímco věty v délkovém intervalu 4—10 slov stylisticky příznakové nejsou.
Nejčastěji se využívá zjišťování délky věty k účelům čistě stylovým. Délka věty slouží jako charakteristika textů, autorů, popř. žánrů.[8] Může charakterizovat jednotlivá stylová pásma v beletrii, pásmo autorské řeči, řeči postav a uvozovacích vět,[9] popř. i jednotlivé postavy (např. v románu) nebo obsah určitých úseků textu. Zvláštní místo zaujímá charakteristika větné délky v básnickém jazyce,[10] zejm. se zřetelem k rytmu, rýmu a délce verše.[11] Délka [234]věty dále tvoří součást měr čtivosti.[12] Jakožto údaj týkající se větné struktury doplňuje syntaktickou charakteristiku věty.[13] Jak bylo uvedeno výše, změny v délce věty lze sledovat také při zkoumání diachronickém.[14] A konečně údaje o délce věty mohou sloužit ke zpřesnění některých výsledků konfrontačního popisu jazyků.[15]
Různé aspekty interpretační jsou podmíněny volbou různých postupů při statistické analýze větné délky. Pokusili jsme se je shrnout do tří skupin:
1. Postup globální. Výsledkem analýzy je jedna statistická charakteristika délky, nejčastěji aritmetický průměr, která celkově charakterizuje délkové kvantitativní poměry v daném jazykovém materiále. Průměrná délka věty je prostředkem stylové typologie textů,[16] popř. žánrů a stylů, i měřítkem vnitřní homogennosti žánrů. Průměr může být korigován dalšími statistickými charakteristikami, z nichž nejčastěji se užívá modu, mediánu, variačního koeficientu, popř. váženého průměru.
2. Postup strukturní. Zkoumá se vnitřní statistická struktura větných délek neboli typ rozložení. C. B. Williams (o. c. v pozn. 6) a později též G. Herdan (o. c. v pozn. 5) dokázali, že délka věty, je-li měřena v počtu slov, má logaritmickonormální rozložení sešikmené doleva (neplatí však Williamsovo tvrzení, že jeden autor má své charakteristické parametry rozložení). Je-li však délka vyjádřena v počtu slabik, má podle Woronczaka (o. c. v pozn. 11) rozložení gama.
3. Postup lineární (sukcesívní). Poměrně zřídka se zkoumají délky vět tak, jak po sobě věty následují v souvislém textu. Tak např. L. Delatte (o. c. v pozn. 8) zjistil, že po větě výjimečně dlouhé se rovnováha délky vyrovnává jednou nebo více větami krátkými a že v některých kapitolách je v porovnání s jinými vysoký počet vět dlouhých. Tyto výsledky uvádí bez další lingvistické interpretace. A. Bartkowiakowa[17] zkoumala též délky větných úseků, tzv. określeń (określeniem se rozumí skupina slov rozvíjejících podmět nebo přísudek), a zjišťovala statistické závislosti mezi sousedními úseky (shledala, že po úsecích krátkých se často vyskytují úseky dlouhé).
Jednou ze zásadních otázek při kvantitativní analýze délky věty je přesné vymezení měřené jednotky (věty) a přesné vymezení jednotky, v níž [235]délku měříme. Volba jednotky podstatným způsobem ovlivňuje jak výsledky samy, tak možnosti jejich interpretace a porovnatelnost výsledků různých analýz. Nejčastěji se pracuje s větou jakožto jednotkou vymezenou graficky („od tečky k tečce“). Analýza délky takto vymezené věty je nejvhodnější především pro účely čistě stylistické. Naproti tomu chceme-li uplatnit jakýkoli zřetel k větné struktuře, např. chceme-li zkoumat, kterými prvky narůstá délka věty, je nutno brát větu jako jednotku predikační neboli „klauzi“.[18] Někdy se počet vět-klauzí aproximuje počtem finitních tvarů slovesných v textu.[19] Rovněž poměr počtu určitých sloves k počtu výskytů ostatních slovních druhů je někdy považován za charakteristiku stylu (W. Mańczak, o. c. v pozn. 8). Lze očekávat, že délka grafické věty bude lépe odrážet stylové charakteristiky textu než délka věty jakožto jednotky s jednou predikací. Pro utvoření věty-klauze má uživatel jazyka k dispozici menší počet strukturních schémat než k utvoření jednotky vyšší, souvětí. Proto ve stavbě i délce souvětí je také větší možnost individuálního zacházení s jazykovými prostředky, a tím tedy i větší rozdíly mezi texty. Bylo např. zjištěno (rkp. autorčiny práce), že několik textů stejné délky z téže stylové oblasti se neliší rozložením délky vět-klauzí (predikačních jednotek), liší se však významně rozložením délky souvětí a frekvencí vět vedlejších. — V žádném případě délka není jediným parametrem stylové funkce věty (výpovědi). Těchto parametrů je více a týkají se v prvé řadě strukturních vlastností věty (srov. např. kontrast větných typů enumerativních lineárních a vztahových plošných, založený na rozdílném využití konstrukcí koordinačních a subordinačních, o kterém mluví J. Mistrík, o. c. v pozn. 1, s. 287). Nemůžeme tedy čekat, že statistická charakteristika větné délky nám řekne o stylu věty vše; vyjádří pouze jeden její aspekt.
Délka věty se počítá zpravidla v počtu slov (grafických jednotek). Mnohem méně obvyklé jsou délkové jednotky jiné, a to jednak větný člen, jednak slabika. Počtem větných členů se délka věty vyjadřuje tam, kde jde o vztah mezi délkou a syntaktickou strukturou věty.[20] Někdy bývá zjišťován také počet vět v souvětí. — Délku věty v počtu slabik zjišťoval např. J. Woronczak (o. c. v pozn. 11), aby mohl porovnat rozložení četností větných délek s rozložením četností veršových délek v polských a českých básních 15. a 16. stol. Za jednu z možných charakteristik věty považuje její délku vyjádřenou v počtu slabik také G. A. Miller.[21]
II. Předvedeme nyní jeden z mnoha možných způsobů, jak přistupovat k analýze větné délky. Otázka, kterou hodláme zodpovědět, zní: Jak se mění počet vět s rostoucí délkou textu? Náš přístup náleží k přístupu, který jsme výše označili jako globální. Základní statistickou charakteristikou, na které je [236]založen, je aritmetický průměr. Šetření je provedeno na českém materiále[22] ze stylu beletristického a odborného. Porovnávají se jednak výběry z téhož textu, jednak výběry z různých textů. Délka věty (predikační jednotky) se udává v počtu slov.
Analyzovaný materiál tvoří výběry z románů K. Čapka Život a dílo skladatele Foltýna a Vl. Vančury Konec starých časů a z odborných knih technických, z knihy K. Chocholy Spalovací motory a z knihy E. Severina—V. Kasiky Průmyslová televize. Z každé z těchto knih byly pořízeny dva výběry, a to takto: první výběr tvoří dvakrát 5000 slov po sobě vzatých, resp. tedy 10 000 slov souvislého textu (s vyloučením nadpisů) vzatých od počátku díla, druhý výběr posledních 5000 slov souvislého textu z konce knihy. Naše statistické šetření je tedy založeno celkem na osmi výběrech, z nichž vždy čtyři jsou téže délky.
Tab. č. 1. Data o délce věty ve výběrech z knihy V. Vančury Konec starých časů.
| xi | y̅i | yj | frekvence | frekvence | |||||
| J | H | V | a | p | u | ||||
|
| 1 000 | 188 | 5,32 | 17,6 | 50,5 | 31,9 | 97,3 | 2,1 | 0,5 |
|
| 2 000 | 352 | 6,10 | 18,3 | 47,0 | 34,7 | 93,2 | 4,9 | 1,8 |
|
| 3 000 | 539 | 5,35 | 18,2 | 44,9 | 36,9 | 97,8 | 1,6 | 0,5 |
|
| 4 000 | 723 | 5,43 | 19,6 | 50,0 | 30,4 | 86,4 | 9,8 | 3,8 |
| začátek | 5 000 | 919 | 5,10 | 13,8 | 53,5 | 32,7 | 90,3 | 8,2 | 1,5 |
| knihy | 6 000 | 1 128 | 4,78 | 21,1 | 56,0 | 22,9 | 82,2 | 14,9 | 2,9 |
|
| 7 000 | 1 321 | 5,18 | 24,3 | 51,3 | 24,4 | 71,5 | 23,8 | 4,7 |
|
| 8 000 | 1 506 | 5,41 | 19,5 | 51,9 | 28,6 | 93,5 | 4,3 | 2,2 |
|
| 9 000 | 1 697 | 5,24 | 19,4 | 53,4 | 27,2 | 95,2 | 4,2 | 0,5 |
|
| 10 000 | 1 932 | 4,26 | 17,0 | 50,0 | 32,9 | 69,7 | 22,6 | 7,7 |
|
| 1 000 | 244 | 4,10 | 26,6 | 43,0 | 30,3 | 56,9 | 36,9 | 6,1 |
|
| 2 000 | 497 | 3,95 | 26,5 | 45,8 | 27,7 | 21,3 | 64,0 | 14,6 |
| konec | 3 000 | 740 | 4,12 | 32,9 | 47,7 | 19,3 | 44,4 | 47,7 | 7,8 |
| knihy | 4 000 | 971 | 4,33 | 23,8 | 51,5 | 24,7 | 59,7 | 28,6 | 11,7 |
|
| 5 000 | 1 185 | 4,67 | 16,8 | 47,6 | 35,5 | 73,3 | 20,6 | 6,0 |
Vysvětlivky:
xi … délka textu v počtu slov; index značí počet podvýběrů
yi … kumulativní četnost vět
y̅j … průměrná délka věty v jednotlivých podvýběrech o 1000 slovech
J, H, V … druhy vět (věta samostatná, věta hlavní v souvětí, věta vedlejší)
a, p, u … autorská řeč, přímá řeč, uvozovací věta
Všechny výběry jsme rozdělili na stejně dlouhé úseky (podvýběry), každý o 1000 slovech, a zjišťovali jsme: a) narůstání počtu vět s rostoucí délkou textu (v počtu slov), a to tak, že jsme jakožto základní výchozí údaje vypočítali ku[237]mulativní četnosti vět v podvýběrech po sobě jdoucích; b) změny průměrné délky věty v jednotlivých podvýběrech.
Ad a) Číselné údaje ve všech výběrech ukazují, že vztah mezi délkou textu a kumulativní četností vět je přibližně lineární neboli že s rostoucí délkou textu dochází k rovnoměrnému přírůstku vět.
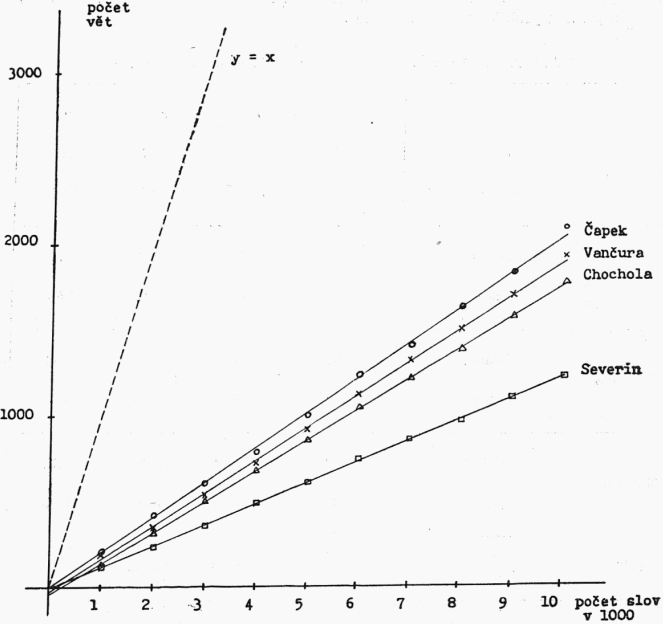
Např. ve výběru z počátku knihy Vančurovy Konec starých časů (srov. tab. č. 1) přibývá s rostoucí délkou textu (vždy o 1000 slov) vět takto: 188 vět, 352 vět, 539 vět, 723 vět, 919 vět atd. Tento vztah lze přibližně popsat rovnicí přímky y = mx + b, kde je
x … délka textu, veličina daná (nezávisle proměnná),
y … počet vět, veličina hledaná (závisle proměnná),
m, b … parametry přímky (m je směrnice přímky, b značí posun vzhledem k počátku).
Grafické znázornění viz na obr. 1. Parametry m a b jsme vypočítali pomocí metody nejmenších čtverců (výsledky viz v tab. č. 2). Přesnost lineární aproximace jsme otestovali korelačním koeficientem; pro všechny výběry je hodnota korelačního [238]koeficientu r = 0,999 (viz třetí sloupec v tab. č. 2), takže aproximaci lze hodnotit jako velmi přesnou.
Teoretické rozpětí směrnic neboli obor existence lineární funkce je dán dvěma mezemi:
1. Délka textu (počet slov) se rovná počtu vět. Potom x = y, m = 1 a b = 0.
2. Celý text obsahuje právě jednu větu, popř. méně než právě jednu větu (jediná věta, jíž je text tvořen, může zůstat nedokončena). Potom y = 1, popř. y = 0 pro každé x a přímka prakticky splyne s osou x.
Tab. č. 2. Parametry přímek a hodnoty korelačního koeficientu.
|
|
| m | b | r | y̅ |
|
| začátek | 0,1911 | —25,2500 | 0,9997 | 5,18 |
| Vančura |
|
|
|
|
|
|
| konec | 0,2424 | 7,0000 | 0,9998 | 4,22 |
|
| začátek | 0,2048 | — 6,1944 | 0,9997 | 4,77 |
| Čapek |
|
|
|
|
|
|
| konec | 0,2367 | —35,0000 | 0,9994 | 4,58 |
|
| začátek | 0,1797 | —36,7500 | 0,9999 | 5,62 |
| Chochola |
|
|
|
|
|
|
| konec | 0,1944 | —11,5000 | 0,9993 | 5,31 |
|
| začátek | 0,1241 | — 9,5833 | 0,9998 | 8,12 |
| Severin |
|
|
|
|
|
|
| konec | 0,1154 | 11,5000 | 0,9993 | 8,35 |
| Wolf |
| 0,1364 | 17,2195 | 0,9998 | 7,28 |
| Pacák |
| 0,1530 | 10,0932 | 0,9995 | 6,52 |
Vysvětlivky:
m … směrnice přímky
b … posun vzhledem k počátku
r … korelační koeficient
y̅ … průměrná délka věty ve výběru
Empirické hodnoty zjištěné pro naše výběry zabírají pásmo, které je přibližně uprostřed mezi oběma teoretickými mezemi. Směrnice přímky je charakteristickým parametrem každého výběru. Lingvistický smysl tohoto parametru lze vyjádřit takto: Směrnice přímky m je přibližně převrácenou hodnotou průměrné délky věty y̅ (při zanedbání parametru b). Posun vzhledem k počátku je [239]nepatrný; parametr b se nepodařilo rozumně lingvisticky interpretovat. Lze tedy uzavřít takto: Vztah mezi délkou textu a počtem vět je pro rozsahy výběrů do 10 000 slov přibližně lineární, tj. lze ho popsat rovnicí přímky, jejíž parametry jsou charakteristikou konkrétního výběru a od výběru k výběru se mohou lišit.
Tento vztah platí i tehdy, měříme-li délku věty nikoli v počtu slov, nýbrž v počtu větných členů. Toto tvrzení jsme ověřili na dvou výběrech přibližně stejného rozsahu, jaký měly výběry předešlé (přesněji: o rozsahu 7278 a 6521 větných členů). Parametry přímek a hodnoty korelačního koeficientu jsou uvedeny v tab. č. 2.[23]
Ad b) Pro každý výběr jsme vypočítali průměrnou délku věty y̅ (hodnoty viz v tab. 1 a 2), a to jak v celém výběru, tak pro jednotlivé podvýběry (y̅j). Hodnoty o průměrné délce jsme porovnávali jak mezi oběma výběry z téhož díla, tak i uvnitř téhož výběru mezi podvýběry.
ba) Porovnání mezi dvěma výběry z téhož díla na materiále z Vl. Vančury. Podrobněji jsme prozkoumali, jak některé faktory stylisticko-kompoziční a stylisticko-syntaktické ovlivňují průměrnou délku věty, a shledali jsme:
(1) S poklesem průměrné délky věty ve výběru výrazně stoupá podíl přímé řeči (a též vět uvozovacích). Převažuje dialog nad souvislým vyprávěním autora. Relativní četnosti vět náležejících do autorské řeči, přímé řeči postav a uvozovacích vět srov. v tab. č. 1.
(2) S poklesem průměrné délky věty ve výběru stoupá počet vět s neslovesným predikátem, vokativních, citoslovečných, částicových (v průměru tvoří tyto věty přibližně necelých 5 % všech vět). Jsou typické pro přímou řeč a krátké.
(3) Při rozlišení vět hlavních (H) v souvětí, vedlejších (V) v souvětí a vět samostatných (J) je podíl H zhruba konstantní (uvnitř výběrů i mezi výběry navzájem). Naproti tomu podíl J stoupá tam, kde klesá průměrná délka věty a kde stoupá podíl přímé řeči. Komunikativní cíle stylizovaného dialogu vedou k nepřetěžování věty ani v rámci struktury souvětí, ani v rámci struktury jednoduché věty. Proto se dává přednost většímu počtu vět krátkých a řazených vedle sebe (J, H) před celky s podřazenými větami. Relativní četnosti J, H a V jsou uvedeny v tab. č. 1.
bb) Porovnání průměrné délky věty bylo provedeno v jednotlivých podvýběrech uvnitř téhož výběru. Čísla ukazují, že průměrná délka věty není v jednotlivých podvýběrech zcela stejná (text není tedy co do délky věty absolutně homogenní), nemění se však natolik významně, aby se změny mohly projevit např. jako nelineární zkreslení regresní čáry (jak jsme výše ukázali, je aproximace přímkou velmi přesná). Důvod lze spatřovat ve způsobu volby jednotky zkoumání, věty. Pro větu definovanou jedním aktem predikačním je její délka především odrazem syntaktických vztahů mezi slovy v ní, a teprve v druhé řadě je také parametrem stylovým.
K zajímavým výsledkům vede také porovnání délky druhů vět (J, H a V) v textech různých stylů. Ve stylizovaném dialogu (viz výše) jsou samostatné věty (J) nejkratší. V odborném stylu naproti tomu mají tyto věty nejvyšší [240]průměrnou délku (nejmenší průměrnou délku mají věty vedlejší V). Souvisí to s povahou odborného vyjadřování i s rozdílným postavením těchto vět v komunikativní struktuře textu. Zatímco jednoduché samostatné věty (J) jsou jednotky sdělně uzavřené, věty vedlejší jsou jednotky komunikativně nižšího řádu,[24] závislé na jednotkách vyšších, jejichž téma nebo réma, popř. jejich součást tvoří.
R É S U M É
On Sentence-Length
The author presents a critical survey of literature and problems concerning sentence-length (I). The relationship between the length of text (given in number of words) and number of clauses (given in number of words or in number of syntactic elements) is investigated. This relationship can be described by a linear approximation, the parameters of which are characteristic of each sample and may differ from sample to sample (II).
[1] J. Mistrík, Štylistika slovenského jazyka, Bratislava 1970.
[2] An annotated bibliography of statistical stylistics, Ann Arbor 1968, 97 s.
[3] L. A. Sherman, Analytics of literature, Boston 1893; týž, Some observations upon the sentence-length in English prose, University of Nebraska studies I, 1888, 119—130.
[4] L. Klimeš, Kvantitativní vývoj věty a souvětí v české historické próze z let 1685—1757 (v tisku). — A. Wierzbicka, System składniowo stylistyczny prozy polskiego renesansu, Varšava 1966, 278 s. — V. G. Admoni, Razmer predloženija slovosočetanija kak javlenija sintaksičeskogo stroja, VJaz 15, 1966, č. 4, s. 111—118.
[5] G. Herdan, Type-token mathematics, The Hague 1960, s. 55—68.
[6] C. B. Williams, A note on the statistical analysis of sentence-length as a criterion of literary style, Biometrika 31, 1939, 356—361. — K. R. Buch, A note on sentence-length as random variable, Den 11te Skandinaviske Matematikerkongress, Oslo 1952, 272—275. Oba články jsou přetištěny ve sb. Statistics and style, New York 1968.
[7] G. U. Yule, On sentence-length as a statistical characteristics of style in prose: with application to two cases of disputed authorship, Biometrica 30, 1939, č. 3—4, 363—390.
[8] Srov. I. Anghel - E. Comsulea - E. Kis - I. I. Stan, Topica propozitiilor principale in proza beletristica romana contemporana, Studii şi cercetari lingvistice 17, 1966, 661—681. — K. R. Buch, o. c. v pozn. 6. — L. Delatte - Évrard et al., Senéque, Index verborum, Liège 1962, 1963 a 1964, viz SaS 26, 1965, 37. — J. Horecký, Štylisticko-štatistické hodnoty jednej básnickej zbierky, Jazykovedné štúdie 8, 1965, 71—84. — J. Kraus, Kvantitativní rozbor stylu pracovních návodů, NŘ 49, 1966, 193—199. — M. L. Marckworth - L. M. Bell, Sentence-length distribution in the corpus, v kn. H. Kučera - W. N. Francis, Computational analysis of present-day American English, Providence, Rhode Island 1967, 368—405, srov. rec. v SaS 30, 1969, 187—191. — W. Mańczak, La longueur de la proposition comme facteur stylistique, ve sb. Langue et littérature, Paris 1961, 401—403. — V. S. Perebijnis et al., Statistični parametri stiliv, Kijev 1967. — W. Taylor, The prose style of Johnson, University of Wisconsin studies in language and literature II, 1918, 22—56. — C. B. Williams, o. c. v pozn. 6. — W. Winter, Relative Häufigkeit syntaktischer Erscheinungen als Mittel zur Abgrenzung von Stilarten, Phonetica 7, 1961. — A. H. Wolfington, A ratio for sentence-length variety, English Journal 52, 452—452, s. 740.
[9] Srov. R. Mutafčiev, Statističesko razpredelenije na glagolni formi, Ezik i literatura 20, 1965, 11—25. — J. Mistrík, Dĺžka vety pri štylistickej charakteristike, Slreč 32, 1967, 19—25. — J. Mistrík, Stredné hodnoty dĺžky vety pri štylistickej typológii, tamtéž, s. 78—82. — G. A. Lesskis, O zavisimosti meždu razmerom predloženija i jego strukturoj v raznych vidach teksta, VJaz 13, 1964, č. 3, s. 99—123; týž, O zavisimosti meždu razmerom predloženija i charakterom teksta, tamtéž 1963, č. 3, s. 92—112; týž, O razmerach predloženij v russkoj naučnoj i chudožestvennoj proze 60-ch godov XIX v., tamtéž 1962, č. 2, s. 78—95.
[10] Srov. PSML 2, Praha 1967, 97—104.
[11] Srov. L. Pszczołowska, Z zagadnień składni w utworze wierszowanym, PamLit 1963, 479—490; táž, Długošč wierszu a budowa zdania, ve sb. Poetyka i matematyka, Varšava 1965, 79—96. — J. Woronczak, Statistické metody v nauce o verši, čes. překlad ve sb. Teorie informace a jazykověda, Praha 1964, 282—296.
[12] Srov. W. S. Gray - B. E. Leary, What makes a book readable, Chicago 1935, 358 s. — I. Lorge, The Lorge formula for estimating the difficulty of reading materials, New York 1959, 20 s.
[13] Srov. H. Eggers, Zur Syntax der deutschen Sprache der Gegenwart, Studium generale, Berlin - Heidelberg - Göttingen 1962. — M. Königová, On statistical dependence in syntax, PSML 3, v tisku. — G. A. Lesskis, o. c. v pozn. 9. — J. Weisseborn, Recherche statistiques sur la structure de la phrase allemande, Études de linguistique appliquée 1965, č. 3, s. 75—85.
[14] Srov. V. G. Admoni, o. c. v pozn. 4. — L. A. Sherman, o. c. v pozn. 3.
[15] Srov. O. Parolková, Kvantitativní výzkum věty v ruštině (na materiálu 4000 vět z novin), Otázky slovanské syntaxe II, Brno 1968, 245—252; táž, Determinace substantiva a délka věty, Filologické studie II, Praha 1970, 29—39.
[16] J. Kraus, o. c. v pozn. 8, J. Mistrík, o. c. v pozn. 1 a 9. — H. Meier, Deutsche Sprachstatistik I, Hildesheim 1964.
[17] Srov. A. Bartkowiakowa, O rozkładzie określeń w zdaniach opisowych Żeromskiego i Sienkiewicza, Zastosowania matematyki 1962, 287—302.
[18] Srov. např. výše cit. práce V. G. Admoniho, L. Klimeše, J. Mistríka, L. Pszczołowské, a též práci H. Spang-Hanssena Sentence-length and statistical linguistics, ve sb. Structures and Quanta, Copenhagen a New York, 1963, 58—73.
[19] Srov. práce R. Mutafčieva, L. A. Shermana, W. Wintera cit. výše a dále práci U. Dąmbské-Prokopové, Longueur de la phrase et la proposition dans la prose de Robbe-Grillet, Kwartalnik neofilologiczny 15, 1968, 391—398.
[20] Srov. práci H. Spang-Hanssena cit výše, K. Buttkeho, Gesetzmässigkeiten der Wortfolge im Russischen, Halle 1969, 121 s., a L. Uhlířové, Vztah syntaktické funkce větného členu a jeho místa ve větě, SaS 30, 1969, 358—370.
[21] G. A. Miller, Language and communication, New York 1951.
[22] Bylo použito materiálu shromažďovaného za vedení M. Těšitelové v oddělení matematické lingvistiky ÚJČ pro účely komplexního kvantitativního výzkumu současné češtiny.
[23] Šlo o výběry z těchto knih: J. Wolf, Učebnice histologie a M. Pacák, Vyšší škola radiotechniky.
[24] A. Svoboda, The hierarchy of communicative units and fields as illustrated by English attributive constructions, BSE 7, 1968, 49—101.
Slovo a slovesnost, volume 32 (1971), number 3, pp. 232-240
Previous Libuše Kroupová: K synchronnímu pojetí českých nevlastních předložek při lexikografickém zpracování
Next Pavel Jančák: Čeština v Ivanově Sele v Jugoslávii
© 2011 – HTML 4.01 – CSS 2.1