
Syntax v Českém národním korpusu
Jan Hajič, Eva Hajičová, Jarmila Panevová, Petr Sgall
[Articles]
Syntax in the Czech National Corpus
[*]Jak by měl být co nejlépe vybaven počítačový korpus českých psaných (a jednou i mluvených) promluv, aby mohl co nejlépe sloužit svým účelům? Jaké účely to jsou, zejména co může česká lingvistika očekávat od takového anotovaného korpusu, a do jaké míry je možné už dnes začít pracovat na jejich splnění, na jaké etapy bude účelné tuto práci rozdělit? Jak dalece bude pro tyto cíle vhodný korpus, který postupně vzniká v Ústavu českého národního korpusu Filozofické fakulty Univerzity Karlovy? Korpus celkově charakterizoval Fr. Čermák (1995), který založení ústavu připravil a navzdory značným překážkám úspěšně uskutečnil.
Nad uvedenými otázkami, probíranými ve spolupráci Čermákova ústavu s dalšími pracovišti Karlovy i Masarykovy univerzity, se tu chceme stručně zamyslet, protože širší diskuse může být jen užitečná. Nejdříve se zastavíme nad účelem a zaměřením přípravy korpusu (odd. 1.), potom stručně probereme technické otázky vzniku korpusu, jeho organizace v podobě báze dat a vytváření gramatických, sémantických a stylistických anotací (odd. 2.), podíváme se na teoretickou problematiku syntaxe a na výběr jejího zpracování pro korpus (odd. 3.), podáme trochu podrobnější charakteristiku syntaktických značek[1] (odd. 4.) a závěrem celkové shrnutí a výhledy (odd. 5.).
1. Účel a zaměření korpusu
Údaje uspořádané v podobě anotovaného počítačového korpusu bude možné využívat pro nejrůznější účely jak v lexikografické práci, tak i při formulaci automatických aplikačních procedur pro vyhledávání informací v textu, strojem podporovaný i strojový překlad atd., a taky ve výzkumu lingvistickém, literárněvědném i dalším.[2] Bude to znamenat docela novou úroveň pro přípravu prací ročníkových, diplomových, disertačních, i pro habilitace a monografie o rozmanitých otázkách, ke kterým bude možné výchozí soubory materiálu získat bez dlouhodobé práce na excerpci a bez pracného pořizování a třídění kartotéčních lístků. Podobně jako materiál dříve získávaný excerpcí, ani výchozí soubor údajů z korpusu jistě k řešení všech problémů nestačí sám, bude třeba ho doplňovat na základě autorova jazykového povědomí, kontrolovatelných testů s dalšími mluvčími, aspoň příležitostnými sondami do dalšího materiálu, ale to všechno už bude probíhat na základě rychle získaného výchozího souboru, jaký bez korpusu k dispozici není.
Poměrně jednoduchá přitom bude situace u otázek týkajících se např. tvaroslovných forem (kolísání mezi jednotlivými vzory aj.), i ve výzkumu funkční platnosti výrazů, pokud půjde o platnost gramatickou. Náročnější bude zjišťování funkcí textových, [169]komunikačních, ať už by šlo o slohovou platnost výrazů (jejich uplatnění v různých typech promluv, jejich povahu knižní, hovorovou aj.), nebo o takové parolové funkce jako např. různotvárný sémanticko-pragmatický vztah k předcházejícímu kontextu (a popř. k podmětu) vyjadřovaný zájmenem to ve větách jako To (já) tam přijdu. Pokud nebude k dispozici velmi rozsáhlý korpus mluvené češtiny (nebo aspoň vyznačení pozice intonačního centra, popř. dalších prozodických jevů), bude i možnost zjistit předcházející výpověď pro takový problém jen dílčí pomůckou. Pro studium způsobů vyjádření určitých funkcí bude zase situace jednodušší v rámci funkcí gramatických; např. ke studiu výrazové stránky adverbiálních doplnění bude třeba vyhledat (v korpusu s anotací na rovině analytické syntaxe, viz odd. 4.1.) mj. předložkové pády i vedlejší věty s označením analytické funkce Adv (popř. AdvAtr, AtrAdv).
I když dostatečný rozsah korpusu a potřebná rozmanitost textů v něm zpracovaných (včetně mluvených) dá na sebe ještě dlouho čekat, je zřejmé, že už možnost uplatnění rozsáhlého korpusu, na jehož anotaci se dnes začíná pracovat, přinese podstatné zlepšení podmínek výzkumu. Důležité přitom je, že při účelném uspořádání práce může takové využívání korpusu podstatně přispívat k postupnému zvýšení jeho úrovně. Tam, kde se nepodaří automatickou procedurou dojít k jednoznačným (nebo k dost spolehlivým) výsledkům, bude právě zřetelné pole pro uplatnění dalšího výzkumu. Zjistí-li se např. v některé disertaci, že k rozlišení různých funkcí výrazu se pomáhají určitá kontextová kritéria (slovesa, jejich tvary a kombinace s jinými výrazy v klauzi atd., nemluvě o fonologickém kontextu relevantním pro identifikaci předložky), bude potom možné takto nalezená kritéria do anotovací procedury začlenit a tak zvýšit její účinnost a spolehlivost. Podobně bude možné zpracovávat různé typy elipsy podle toho, v jaké syntaktické pozici se vyskytuje symbol pro uzel na elidovaném slovu závislý a jaká je syntaktická funkce i slovní druh slova řídícího. Nabízí se i řada dalších témat z oblastí syntaktické závislosti a koordinace, aktuálního členění věty a slovosledu aj., jejichž rozbor umožní jak zlepšení procedury pro anotování na analytické rovině, tak i pro formulaci dalšího stupně analýzy, totiž postupu od této roviny k tektogramatické, významové stavbě věty.
Zcela stručně můžeme význam různých stupňů anotování korpusu vyjádřit takto:
(i) korpus bez anotací nebo jen se základními značkami slovních druhů umožňuje bez pomalé práce s rozsáhlými kartotékami, s rychlostí a rozsahem odpovídajícími dnešní výpočetní technice, důkladně zpracovat otázky týkající se jednotlivých slov, pokud jsou pro ně relevantní jen základní rysy kontextu;
(ii) soustavné morfematické značkování (pro které už existuje automatická procedura) vede k tomu, že např. pro výzkum kolísání mezi jednotlivými tvaroslovnými vzory nemusíme ručně zpracovávat seznamy těchto slov, ale stačí zadat k počítačovému vyhledání tvary, o které jde (např. pády a čísla);
(iii) syntaktická anotace dovolí podobně zadat údaje ze skladby, tzn. zjišťovat nejen funkce a výskyty jednotlivých slovních tvarů v různých kombinacích, ale velmi rychle identifikovat a klasifikovat soubory údajů o kombinacích syntagmat, o slovosledu (i ve smyslu pořadí větných členů) a zjišťovat, co je na těchto úrovních typické pro celý jazyk nebo pro jednotlivé slohové oblasti.
Složitost syntaktických vztahů znamená, že vytvoření poloautomatické anotovací procedury, která je pro zpracování rozsáhlého korpusu nezbytná, si vyžádá řadu předběžných stupňů a dlouholeté postupné zlepšování, ale práce na tom už sama bude pro zvyšování úrovně našich znalostí o češtině mimořádně prospěšná, budeme-li umět její (i dílčí) výsledky využít.
[170]Využití počítačového korpusu není nijak nutně spojeno s matematickou statistikou. Zjistit určité kvantitativní údaje je při práci s dobře organizovaným korpusem snadné a má to své výhody ve srovnání s usuzováním na základě pouhých neupřesněných dojmů. Se složitějším statistickým aparátem běžný uživatel korpusu pracovat nemusí, ten je nutný jen pro (polo)automatické anotování.
2. Uspořádání a poloautomatické anotování korpusu
Textový korpus češtiny je v počítačích uchováván v jednotném tzv. základním formátu. Tento formát je definován jako specifický případ standardního formátu SGML (Standard Generalized Mark-up Language) a umožňuje strukturální anotaci korpusu na všech úrovních složitosti, od označení autora a žánru přes identifikaci slov až k anotaci struktury věty.
Korpus se skládá ze souborů (soubor je pojmenovaná jednotka, která je známa pod jednoznačně identifikovatelným jménem na daném počítači; lze ji tedy kopírovat, mazat, zpracovávat programovými prostředky jako jeden celek). Každý soubor obsahuje jeden nebo několik tzv. dokumentů. Dokumentem může být celá kniha, báseň nebo novinový článek, podle toho, co tvoří homogenní materiál. Dokumenty se dále člení na odstavce, věty, slova a interpunkční znaky. Nejmenší přímo identifikovatelnou jednotkou korpusu je věta; slova jsou v rámci věty řazena sekvenčně. Každý dokument má tzv. hlavičku, která obsahuje informace o dokumentu jako celku: autor, název, zdroj, rok vydání, žánr, styl apod. (viz Čermák – Kubíček, 1997–98). Soubor pak může obsahovat hlavičku, která je společná pro všechny dokumenty v souboru, např. rok vydání nebo autora.
Aby bylo možné operativně vyhledávat všechny výskyty jednotlivých jevů nebo tříd jevů relevantních pro lingvistický výzkum, pro aplikace nebo pro zdokonalování anotačních procedur atd., je korpus uspořádán v podobě textové databáze, opatřené potřebnými vyhledávacími programy.
Texty, které se získávají v elektronické podobě od nakladatelství, přicházejí v nejrůznějším formátu, který je třeba tzv. „vyčistit“ a převést do již zmíněného formátu SGML. Tato konverze obsahuje jak postupy čistě technické, jako např. odstranění dělení slov, nepodstatné formátovací a sázecí informace, tak i postupy již do značné míry lingvisticky motivované, např. identifikaci hranic slov a zejména vět, vytřídění cizojazyčných segmentů textu, vyčlenění omylem zařazených duplikátů téhož textu apod. Všechny tyto postupy jsou již plně automatizovány, probíhají pomocí programových „dávek“ bez lidského zásahu, i když např. dosud zkoumáme různé možnosti zlepšení procedury navržené pro identifikaci konce vět.
Další anotace textu je již záležitostí plně lingvistickou. Je samozřejmé, že čím hlouběji v této analýze jdeme, tím méně se lze spoléhat na metody plně automatické – koneckonců právě textový korpus má sloužit k jejich vývoji.
Dosud používané metody automatické analýzy nejsou, jak již bylo řečeno, stoprocentně spolehlivé. Provádět lingvistickou anotaci „ručně“ na korpusu o 100 miliónech slov ovšem také nelze, dokonce ani není možné korpus manuálně opravovat za použití automatických prostředků – to by trvalo desetiletí. Korpus se proto anotuje metodou tzv. „bootstrappingu“: nejprve anotujeme malou část korpusu (v případě morfologické anotace asi půl miliónu slov, na analytické úrovni asi 250 000 slov, na tektogramatické rovině ještě méně). Pak pomocí statistických metod a metod tzv. strojového učení „natré[171]nujeme“ programy, které se použijí (s jistou únosnou mírou chybovosti) na větší část, ta se opraví opět manuálně, příslušné analytické programy přetrénujeme s větším množstvím správně anotovaných dat, atd. až do takového rozsahu, který jsme schopni zvládnout z hlediska manuálních oprav. Zbytek korpusu se pak anotuje jen automaticky – doufáme přitom, že programy už budou dostatečně „informované“ a text anotují s minimálním počtem chyb. Je třeba podotknout, že „samoučící se“ metody jsou značně komplikované a náročné na specifikaci algoritmů i na vlastní programování. Tyto metody vycházejí z obecných metod používaných např. v základním fyzikálním a biologickém výzkumu, v sociologických modelech, v modelování chování finančních trhů apod. Kritickým momentem z teoretického hlediska je zde adaptace na možnosti rozhodování při analýze textu v přirozeném jazyce; z praktického hlediska jsou důležité požadavky na výpočetní kapacitu počítačů, která je z hlediska těchto metod vždy omezená.
3. Zvolené pojetí syntaxe
Při syntaktickém anotování korpusu vycházíme ze závislostní syntaxe, která charakterizuje větnou stavbu na základě valence, především valence slovesa, protože sloveso je chápáno jako vlastní centrum stavby věty. Vztah predikace (mezi slovesem a podmětem, popř. konatelem) vidíme jako jeden z druhů vztahu závislosti, podobně jako zejm. L. Tesnière nebo u nás Dokulil – Daneš (1958). Další aspekty lingvistického pojetí syntaxe, ze kterého vycházíme, byly popsány zejména u Sgalla – Hajičové – Buráňové (1980), u Panevové (1980), u Sgalla – Hajičové – Panevové (1986) a u Hajičové (1993).
Od uvedeného teoretického pojetí se aplikačně zaměřený přístup k anotování korpusu liší zejména ve věci tzv. povrchové syntaktické (mluvnické) stavby věty. Při počítačovém zpracování přirozených jazyků jak pro takové účely, jako je strojový překlad, tak pro značkování a anotování korpusů, se dnes téměř všude počítá s tím, že pro gramatickou analýzu stačí postup, který v zásadě každému výskytu slova i interpunkčního symbolu přiřadí uzel ve stromu reprezentujícím větnou stavbu. Tento postup se sice liší od našeho přístupu k větné stavbě tektogramatické (významové) i povrchové (mluvnické), ale řídíme se jím při práci na anotování korpusu, protože umožňuje poměrně rychlé vytvoření poloautomatické anotační procedury. Na jejím základě by zvolený postup mohl vést ke vzniku syntakticky anotovaného korpusu o rozsahu desítek milionů slovních výskytů, který by pro účely zmiňované v odd. 1 už měl značný význam.
Syntaktické značky pro český korpus jsou tedy určeny pro charakteristiku věty na rovině, kterou nazýváme rovinou analytické syntaxe (analytickou rovinou). Pro ni platí uvedená zásada „právě jeden uzel pro každý výskyt slova“; žádný další uzel (bez protějšku ve vnější podobě věty) nemůže být dodán (až na drobné výjimky, srov. odd. 4.1.). To je ovšem spojeno s některými bolestnými jevy, zejména s tím, že v syntaktických zápisech vět nejsou zachyceny elidované výrazy. To se týká jak nulových tvarů podmětových zájmen (přišli pozdě), tak elipsy v souřadných spojeních (červený a modrý inkoust, Jirka se stěhuje do Brna a Milan do Břeclavi). Obtíže, které tím jsou způsobeny, jsou zmírněny tím, že pro závislost na elidovaném členu máme v analytických syntaktických zápisech zvláštní symbol ExD, který usnadní rekonstrukci elidovaného výrazu při přechodu od syntaxe analytické k zápisům tektogramatickým. Začalo se už pracovat nejen na proceduře analytického značkování, ale taky na přechodu od analytických stromů k zápisům, které budou respektovat všechny zásady už vyzkoušeného přístupu k významové, tektogramatické stavbě věty.
[172]Menší obtíže působí zmíněná zásada „uzlu pro každé slovo“ tím, že analytické zápisy obsahují uzly nejen pro autosémantika, ale i pro slova pomocná, gramatická. To je spojeno s nutností řešit někdy jen na základě příležitostných konvencí otázku závislostní pozice pomocného slova (nebo i interpunkčního znaku), ale přechod k tektogramatickému zápisu je v tomto bodě poměrně snadný. Problematiku koordinace, a tedy i spojek souřadicích, řešíme zvlášť (viz odd. 4.4.).
Poznamenejme ještě, že v souhlasu s mluvnickou tradicí rozlišujeme značkování tvaroslovné a syntaktické (s uvedenými dvěma rovinami uvnitř syntaxe). Termíny jako ‘morfosyntaktický’ nepoužíváme, protože jsou dvojznačné (užívají se někdy ve smyslu slučovacím, tedy více méně souznačně s výrazy jako gramatický, ale jindy pro určitou užší oblast zachycující víc morfologie než syntaxe).
4. Syntaktické anotování korpusu
4.1. Některé specifické problémy analytické roviny
Jak už řečeno, přijímáme pro danou etapu (povrchového) syntaktického značkování z praktických důvodů zásadu, podle které každému výskytu slova i interpunkčního znaku (a jen takovému výskytu) odpovídá uzel. Výjimkou z této zásady je, že se předem přidávají uzly pro několik druhů jednotek, které se dají identifikovat docela obecně, před vlastní syntaktickou analýzou:
(i) pracujeme se zvláštním uzlem, který je kořenem (vrcholem) stromu a odpovídá větě jako celku (i pro účely její identifikace v souboru);
(ii) zvláštní nové uzly se vytvářejí pro příklonkové s, podle českého pravopisu psané jako koncovka; na základě lexikální identifikace tvaru bez této „koncovky“ (a nepřítomnosti tvaru s ní ve slovníku) se tak rozdělují tvary jako tys, žes, byls, obrázeks (nepověsil); podobně se „rozdělují“ tvary jako oč, nač, zač, bylť, odmítniž (ale ne budiž, neboť).
Východiskem syntaktického anotování je morfologicky analyzovaný, značkovaný korpus. Úspěšnost tvaroslovného značkování (jeho desambiguace) je ve srovnání s více méně obdobným postupem pro angličtinu na první pohled poměrně nízká; analýza složité flexívní morfologie je bohatší na chyby, zejména pokud je formulována tak, aby rozlišovala platnost pokud možno všech homonymních tvarů (viz Hajič – Hladká, 1997). Ale není patrně nutné požadovat všude jednoznačné řešení, ostatně ani běžné značkovací procedury pro angličtinu nerozlišují např. u slovesných tvarů většinu osob obou čísel. Pokud se v morfologickém značkování češtiny (nebo jiných flexívních jazyků) ponechá např. víceznačnost pádu a (u adjektiv) rodu, nebude se úspěšností tolik lišit od značkování textu anglického. Počet značek je při analýze flexívního jazyka daleko vyšší (přes 3000), zejména nebudeme-li se snažit o co nejúplnější desambiguaci, a bude tedy i tak víc příležitostí k výskytu chyb. Na druhé straně ale přinášejí morfematické značky u flexívního jazyka víc informace než u jazyka analytického, poskytují vhodnější podklad pro syntaktickou analýzu.
Každý slovní výskyt i interpunkční znak má své lemma, tj. identifikaci lexikální jednotky. Ta ovšem naráží na homonymii typu kolej, kohoutek; ale procedura počítá s řešením tvarové homonymie typu ženu, hnát, domů na základě statisticky podložené analýzy zároveň s řešením tvaroslovného značkování. Tato analýza rozliší i platnost homonymních tvarů téhož slova jako např. velkým, maže (indikativ a přechodník), ale homonymie tvarů jako pracoval, dělaje (mask. živ. a neživ.), které nebude rozlišena, protože snaha o to by vedla ke zhoršování úspěšnosti morfematické analýzy a ke snižo[173]vání její užitečnosti jako zdroje vstupních dat pro analýzu syntaktickou. Svá lemmata mají i interpunkční znaménka; lemmatem tedy bude rozlišen např. druh závorky (kulatá, hranatá atd. i levá a pravá).
Ke specifickým konvencím (vybraným tak, aby co nejméně narušovaly využitelnost korpusu pro výzkum a aby byly co nejvhodnějším vstupním zápisem pozdější tektogramatické analýzy) patří to, že u neslovesných výpovědí (zejména u nadpisů a jiných názvů) počítáme s elipsou slovesa.
Koordinace jako zvláštní druh syntaktického vztahu[3] se začleňuje do závislostní struktury specifickým způsobem, totiž tak, že uzel pro souřadnou spojku (reprezentující celou souřadnou konstrukci) má syntaktickou funkci Coord, zatímco jednotlivé koordinované členy jsou označeny podle postavení konstrukce ve stavbě věty s připojením specifického symbolu souřadnosti jako Sb_Co, Pred_Co, Obj_Co ap. Tak je možné zachytit i společné rozvíjení celého souřadného spojení, srov. příklad (7) v odd. 4.3., kde je tento jev zastoupen dvakrát. Obdobné konvence se týkají apozice a parenteze.
V současné etapě se zvlášť nezpracovávají sousloví ani frazeologické celky; jejich vnitřní struktura se zachycuje jen jako syntaktické vztahy obvyklého typu (např. vysoká škola jako substantivum s přívlastkem, krýt někomu záda jako spojení slovesa s objektem a adverbiálním určením – šlo by o volný dativ prospěchový). To je ovšem jen předběžný postup, který bude třeba nahradit zpracováním podstatně komplexnějším a líp zdůvodněným, protože frazeologii náleží v celkovém rozboru věty i promluvy velmi důležité místo.
Další konvence o analytické rovině se týkají zejména substantiva jako závislého na předložce, pomocného slovesa na významovém a slovesa vedlejší věty (i čárky) na podřadicí spojce. U pravidel pro vyznačení takových jevů jako interpunkce, uvozovky, závorky, pomlčky považujeme za hlavní, aby se neztrácela žádná informace, která může být relevantní pro výzkumné využívání korpusu nebo pro další stupeň analýzy (tj. zejména pro přechod k tektogramatickému anotování).
Jsme si vědomi, že procedura, jejímž výstupem jsou anotace na analytické rovině, zdaleka ještě nepřináší plnou syntaktickou analýzu věty. Zmíněná zásada uzlu pro každý výskyt slova i jiné okolnosti (zejména nemožnost doplňování systémových elips a při současném stavu výzkumu nezvládnutelná víceznačnost předložek, podřadicích spojek ap.) si vynucují určité zjednodušující konvence. Plné syntaktické anotace bude dosaženo teprve budoucím převedením zápisů do podoby tektogramatiky; ale už dnes vzniká bohatý materiál zaměřený na základní podobu zápisu větné stavby v podobě závislostního stromu (i když s nadbytečnými uzly pro pomocná slova a interpunkční znaky a s absencí uzlů pro slovní tvary elidované) a vyznačení základních typů syntaktických funkcí.
4.2. Poloautomatické anotování na úrovni analytické syntaxe
Zatím probíhá především „ruční“, intelektuální anotování souborů textů z korpusu jako přípravná fáze. Anotátoři, kteří užívají speciální grafický software v operačním systému MS Windows, uplatňují podrobné lingvistické instrukce. Výsledkem jejich činnosti má být asi 10 000 analytických zápisů psaných promluv; ty pak budou sloužit jako „trénovací data“ pro vypracování poloautomatické analýzy.
[174]Třídění analytických funkcí (tj. větných členů v chápání upraveném pro potřeby této roviny) můžeme probrat docela stručně podle užívaných zkratek:
Pred – predikát hlavní věty, i spona,
Sb – podmět,
Obj – předmět, a to (prozatím) bez rozlišení, přímý, nepřímý (např. dal mamince dárek) i ‘druhý’ – např. zvolili ho předsedou, za předsedu,[4]
Adv – nejrůznější druhy příslovečných určení, kromě několika výjimek, o kterých bude řeč níž,
Atv – doplněk, který tu chápeme jako závislý na slovesu jen tehdy, jestliže se vztahuje k nevyjádřenému členu, např. přišel bos (pak píšeme AtvV); jindy zachycujeme na analytické rovině specifický vztah doplňku k jinému větnému členu (protože jeho syntaktická závislost ke slovesu dané klauze se dá celkem snadno zjistit později, při převádění analytických zápisů na tektogramatické, kde půjde o specifický typ funkce), tedy vyznačujeme tu konvenčně (pseudo)závislost na přímém objektu u přivedli ho potlučeného, na nepřímém u dali mu to ještě spícímu, na příslovečném určení u psal tím perem už rozskřípaným, nebo u chodil v těch šatech už (v) hodně roztrhaných atd.,
Pnom – (přísudkové jméno podstatné např. v Jirka je šachista) i přídavné (např. Jirka je nemocný),
ExD – uzel, jehož řídící slovo je elidováno, není v povrchové podobě věty přítomné; může jít o substantivum neslovesné jednočlenné věty (nadpisu ap.) nebo např. o subjekt a příslovečné určení v eliptické větě jako (Jirka se stěhuje do Brna) a Milan (ExD) do Břeclavi (ExD); slovo, jehož funkce je označena jako ExD, je v závislostním stromu „zavěšeno“ na řídící slovo elidovaného výrazu, tedy o stupeň výš, než kde by bylo v tektogramatickém (nebo i v tradičním syntaktickém) stromu,
Atr – atribut (závisí na substantivu).
V dnešní etapě probíhá intelektuální anotování jako podklad pro budoucí (poloautomatickou analýzu.[5] Kde je pro anotátora syntaktická závislost dvojznačná (i se zřetelem ke kontextu, tj. kde nelze bezpečně rozhodnout, na kterém uzlu rozbíraný uzel závisí), tam jsou pro zkrácenou reprezentaci dvou (nebo víc) výsledných zápisů věty k dispozici tyto ‘dvojité’ symboly (vlevo se dává ta část symbolu, která podle odhadu anotátora s větší pravděpodobností odpovídá větné stavbě podle úmyslu mluvčího):
ObjAtr, AtrObj (uzel se zachycuje jako závislý na substantivu, protože pro objektovou platnost se závislé sloveso zpravidla dá identifikovat jednoznačně), např. Dostal cenu Grammy za pěvecký výkon (AtrObj), Tvrdil nesmysly o tomto problému (ObjAtr),
AdvAtr, AtrAdv (s obdobným výběrem), např. Navštěvoval kavárny v Londýně,
AtrAtr (se závislostí k pravému z konkurujících si substantiv), např. řada problémů z morfologie.
Symboly pro pomocná slova (i některá slova jim blízká) a pro interpunkční značky:
AuxV – pomocné sloveso být v préteritu, ve futuru, v pasívu i v kondicionálu (včetně tvaru býval ap.),
AuxT – částice se u reflexív tantum, např. smát se, pospíšit si,
AuxR – reflexívní částice, kde ji nelze považovat za objekt (u tzv. zvratného pasíva, jako vyjádření všeobecného konatele), např. Píše se o tom v novinách,
AuxC – podřadicí spojka,
AuxO – tzv. náladové slovo (např. To prší), dativ etický (Tam ti pršelo),
AuxP – předložka nebo část víceslovné předložky, např. z (AuxP) hlediska (AuxP), se (AuxP) zřetelem (AuxP) k (AuxP),
AuxZ – zdůrazňovací slovo, rematizátor (právě, jen ap.),
AuxY – sekundární část složeného spojovacího výrazu (např. buď ve spojení s primárním (a)nebo), pokleslá vsuvka,
AuxX – čárka,
[175]AuxG – pomlčka, závorka,
AuxK – koncový interpunkční symbol, tj. tečka, středník atd.,
AuxS – kořen (vrchol) celého stromu.
4.3. Příklady
Uvedeme teď několik příkladů analytických zápisů vět v podobě závislostních stromů; místo lemmat a údajů o morfologických kategoriích zjištěných předchozí tvaroslovnou analýzou uvádíme pro lepší přehlednost tvary slov:
Podobu analytického stromu je možné posoudit podle příkladu uvedeného v obr. 1.
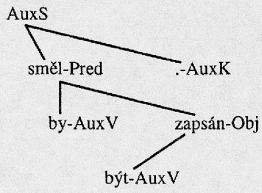
Obr. 1.
Závislostní strom pro větu Směl by být zapsán.
Další příklady uvádíme z typografických důvodů v linearizované podobě, místo hran stromu píšeme dvojice závorek, do kterých zahrnujeme závislý člen; mezi lexikální a gramatickou část hodnoty uzlu dáváme středník.
(1) Bazén byl již napuštěn(ý). – spona (výsledný stav)
AuxS ((bazén;Sb) byl;Pred (již;AuxZ) (napuštěn;Pnom)) (.;AuxK)
(2) Kniha byla přeložena Alenou Maxovou. – pasívum (děj)
AuxS ((kniha;Sb) (byla;AuxV) přeložena;Pred ((Alenou;Atr) Maxovou;Obj)) (.;AuxK)
(3) Má uvařeno. – Mathesiovo perfektum na této rovině rozbíráme, jako by šlo o doplněk
AuxS (má;Pred (uvařeno;AtvV)) (.;AuxK)
(4) Dal mu knihu. – přímý a nepřímý předmět
AuxS (dal;Pred (mu;Obj) (knihu;Obj)) (.;AuxK)
(5) Mohl by přijít. – modální výrazy
AuxS (mohl;Pred (by;AuxV) (přijít;Obj)) (.;AuxK)
(6) Dům, který je drahý, si nekoupíme. – vztažná věta
AuxS ((dům;Obj ((AuxX) (který;Sb) je;Atr (drahý;Pnom) (AuxX))) (si;Obj) nekoupíme;Pred) (.;AuxK)
(7) Devizové rezervy ČNB jsou na vysoké úrovni a stále rostou, takže si to můžeme dovolit. – souřadnost a podřadnost (vedlejší věta závisí na koordinované konstrukci přísudků, stejně jako společný podmět)
AuxS ((((devizové;Atr) rezervy;Sb (ČNB;Atr)) jsou;Pred_Co (na;AuxP ((vysoké;Atr) úrovni;Adv))) a;Coord ((stále;Adv) rostou;Pred_Co) ((,;AuxX) takže;AuxC (můžeme;Adv ((si;Obj) (to;Obj) dovolit;Obj)))) (.;AuxK)
[176]5. Výhledy
Počítá se s tím, že rozsah anotované části korpusu v dohledné době dosáhne čtvrt milionu vět se zápisem analytických struktur. Další zlepšování automatické procedury si vyžádá velké úsilí. Lepší budou anotace tvaroslovné, které brzy obsáhnou podstatně širší část korpusu.
Připravují se první formulace základních složek dalšího stupně poloautomatického anotování, převádějícího údaje z tzv. analytické roviny na rovinu tektogramatickou. Půjde přitom zejména o podrobné třídění druhů doplnění, jak aktantů (konatel, adresát, patiens, původ a výsledek), tak volných určení (místních, časových, směrových, způsobových, podmínkových, příčinných, zřetelových aj.). Dalším úkolem této etapy bude zpracování aktuálního členění, tj. rozlišení prvků kontextově zapojených a nezapojených (i dvojznačných) a analýza vztahu mezi povrchovým a hloubkovým slovosledem, zejména řešení neprojektivních spojení (převedením příklonek a jiných výrazů do jejich pozic odpovídajících jejich syntaktické funkci a stupni výpovědní dynamičnosti; kde je tato pozice dána specifickým rysem, např. v kontrastivním tématu, bude uzel stromu opatřen příslušným údajem, indexem).
V téže etapě bude třeba aspoň v základní rovině zpracovat otázky frazeologie, a také elementární prvky problematiky nadvětného kontextu.
Dalším rozsáhlým polem čekajícím na zpracování jsou mluvené komunikáty a jejich v mnohém specifická syntax (nejasné hranice mezi větami, častá vybočení z vazby, nedokončené konstrukce, slovosledné odchylky aj.) i složité problémy jejich stylistického bohatství a rozvrstvení. Nebude zdaleka snadné zajistit kompatibilitu anotace písemných textů a mluvených diskurzů, jejichž zpracování se jistě neobejde bez většího rozsahu jevů nerozhodnutelných.
Všechny tyto problémy bude možné postupně řešit na základě poloautomatických procedur, rozboru jejich výsledků a jejich využití pro zlepšování procedur. K hlavním zřetelům při formulaci prvních podob těchto procedur patří ohled na to, aby bylo možné je využívat pro monografické zpracování co nejširšího okruhu bohemistických otázek, a to ve spojení s nejrůznějšími koncepcemi syntaxe; povaha procedury by měla zajišťovat, že nebude obtížné uplatnit ji ve spojení s jakoukoli základní koncepcí analýzy větné stavby.
Pro nynější práci na podobě tzv. analytické roviny z toho vyplývá, že vytváření trénovacího souboru pro rozsáhlou poloautomatickou syntaktickou anotaci českých vět má být založeno na proceduře, ve které jsou jednoznačně odlišeny závislostní hrany od jiných a neztrácí se nic ze vstupní informace ani z údajů získaných morfematickým značkováním.
LITERATURA
ČERMÁK, FR.: Jazykový korpus: prostředek a zdroj poznání. SaS, 56, 1995, s. 119–140.
ČERMÁK, FR. – KUBÍČEK, P.: Jazykový korpus a škola. Český jazyk a literatura ve škole, 1997–98, s. 84–92.
DOKULIL, M. – DANEŠ, F.: K tzv. významové a mluvnické stavbě věty. In: O vědeckém poznání soudobých jazyků. Academia, Praha 1958.
HAJIČ, J. – HLADKÁ, B.: Morfologické značkování korpusu českých textů stochastickou metodou. SaS, 58, 1997, s. 288–304.
HAJIČOVÁ, E.: Issues of Sentence Structure and Discourse Patterns. Karlova univerzita, Praha 1993.
[177]JANÁTOVÁ, Z.: Complex dependency structures and graphs. PBML, 56, 1991, s. 5–36.
KUČEROVÁ, J.: The extension of the condition of projectivity for structures with coordination. PBML, č. 63, 1995, s. 67–84; č. 65–66, 1996, s. 67–92.
PANEVOVÁ, J.: Formy a funkce ve stavbě české věty. Academia, Praha 1980.
PETKEVIČ, V.: Underlying Structure of Sentence Based on Dependency. Karlova univerzita, Praha (v tisku).
SGALL, P.: Teorie valence a její formální zpracování. SaS, 59, 1998, s. 15–29.
SGALL, P. – HAJIČOVÁ, E. – BURÁŇOVÁ, E.: Aktuální členění věty v češtině. Academia, Praha 1980.
SGALL, P. – HAJIČOVÁ, E. – PANEVOVÁ, J.: The Meaning of the Sentence. Reidel, Dordrecht – Academia, Praha 1986.
R É S U M É
Syntax in the Czech National Corpus
In cooperation between the Institute of the Czech National Corpus, Faculty of Philosophy, Charles University and several other research groups, an annotated version of the corpus is being prepared. After morphemic tagging of the Czech corpus has been ensured, its syntactic annotation will be included. The basic background for this is seen in the Functional Generative Description with its tectogrammatical (underlying) syntax. However, before this level can be achieved, a version of surface syntax, specified as the analytic level (with trees containing a node for every word occurrence, not reflecting the deleted items) is being formulated.
[*] Práce na této stati probíhala v rámci projektů GA ČR č. 405/96/K 214 a MŠMT ČR VS 96151.
[1] Terminologicky rozlišujeme mezi značkou (a. ‘tag’) a anotací (‘annotation’) tak, že o (více méně jednoduchých) značkách mluvíme uvnitř jednotlivých rovin, zejména u tvarosloví, kdežto anotace chápeme jako složitější soubory značek. V tomto článku ovšem uvádíme příklady anotování převážně jen v jejich složce syntaktické, nevracíme se k morfematickým značkám stručně popsaným v článku Hajiče a Hladké (1997) a nevěnujeme pozornost značkování lexikálně-sémantickému nebo stylistickému.
[2] Termín ‘korpus’ užíváme dál jen ve smyslu počítačového souboru textů uloženého a uspořádaného tak, aby bylo možné snadno v něm vyhledávat výskyty jednotlivých výrazů z promluv, které jsou v něm obsaženy, i symbolů užívaných pro jejich lingvistické třídění a charakteristiku.
[3] V tektogramatice odpovídají koordinovaným konstrukcím hrany dalšího rozměru, viz Sgall (1997); k formálnímu zpracování komplexních zápisů vět zachycujících i koordinaci viz Petkevič (1987), Janátová (1991) a nyní zejm. Kučerová (1995–96).
[4] Jako „předmět“ zachycujeme na této rovině i infinitiv ve složených slovesných tvarech s modálním a fázovým slovesem, a taky původce děje u pasíva, aby byla vyznačena aktantová povaha tohoto členu (tektogramaticky chápaného jako konatel) a jeho různost od prostředkového doplnění.
[5] Poznamenejme ještě, že analytické stromy obsahují i neprojektivní konstrukce, které v tektogramatických zápisech vět nemají místo. Počítáme s možností řešit jejich popis na základě přemísťovacích pravidel mezi hloubkovou strukturou (strom) a morfematickým řetězem.
Slovo a slovesnost, volume 59 (1998), number 3, pp. 168-177
Previous Ladislav Nebeský: Prostor a jazyk
Next Karel Kučera: Vývoj účinnosti a složitosti českého pravopisu od konce 13. do konce 20. století
© 2011 – HTML 4.01 – CSS 2.1