
Hodnocení vlivu příbuzného jazyka na slovní zásobu českého nářečí (Na materiále českých nářečí na Duruvarsku v Jugoslávii)
Pavel Jančák
[Články]
Évaluation de l’influence d’une langue apparentée sur le lexique d’un dialecte tchèque (basée sur le matériel des dialectes tchèques de la région de Daruvar en Yougoslavie)
Při studiu otázek jazykové interference jeví se účelné postihovat míru cizích prvků pronikajících do ovlivňovaného jazyka také statistickým šetřením, neboť nám to umožňuje sledovat složitý proces ovlivňování i ze stránky kvantitativní. V dosavadní bohaté literatuře o této problematice se však statistické metody zatím příliš neuplatňovaly. Příčinu lze vidět jednak v tom, že se k statistickému šetření v daném případě dobře hodí hlavně takové jazykové útvary, které jsou už v určitém pokročilejším stadiu bilingvismu,[1] a že materiál, na němž se má probíhající proces interference demonstrovat, musí být dostatečně rozsáhlý.
Náš materiál, získaný při studiu jazyka jednoho z největších českých (dále č.) zahraničních ostrovů na Daruvarsku (dále Dar.) v Jugoslávii,[2] splňuje tyto požadavky celkem dobře. Jednak proto, že rozhodující většina příslušníků č. osídlení, trvajícího zde v průměru až asi sto let uprostřed charvátského a srbského (dále sch.) jazykového prostředí, je v současné době v stadiu kolektivního bilingvismu, jednak proto, že při výzkumu, konaném pro Český jazykový atlas (ČJA) paralelně v třech obcích na Dar., se podařilo sebrat poměrně rozsáhlý a vnitřně diferencovaný materiál, který je zároveň vhodný i pro sledování prvků pronikajících z příbuzného jazykového prostředí.[3] Celkový stupeň sch. vlivů na daruvarskou češtinu (dále dč.) je ovšem zatím poměrně malý, takže ještě nejsou podmínky pro uplatnění statistických metod při sledování cizích prvků u jevů hláskoslovných a tvaroslovných, tedy v oblasti, kde se zatím statistických metod při studiu jazykové interference užívá častěji. Můžeme-li v našem případě užít statistických metod i při sledování cizích vlivů v oblasti slovní zásoby, je to proto, že se opíráme o poměrně velký a vnitřně diferencovaný vzorek vybraných lexikálních jednotek a že materiál získaný na Dar. dává možnost celkového i dílčího srovnávání.
Komparabilnost materiálu je zajištěna jak už samým zaměřením dotazníku a uspořádáním jeho hesel, tak výběrem informátorů a metodickým postupem při výzkumu (podrobná charakteristika viz Sch-dč. 330). Ukázalo se, že toto zaměření výzkumu, původně určeného pro porovnávání jazykového stavu v různých oblastech č. nářečí, lze s úspěchem aplikovat i na zajišťování a porovnávání míry ovlivnění č. nářečí v jinojazyčném prostředí. Na pozadí konfrontace s jazykovým stavem v nářečích na mateřském území představuje jazykový stav ve zkoumaných třech obcích na Dar., v nichž je shodou okolností zároveň i různý stupeň cizího ovlivnění, tři různé výsledky téhož procesu serbokroatizace, probíhajícího v dané oblasti zhruba za týchž pod[303]mínek a sledovaného na souboru slov základní, převážně tradiční slovní zásoby, představovaného všemi hesly atlasového dotazníku.[4]
Konfrontuje se materiál z těchto tří daruvar. obcí:
Velké Zdence (Veliki Zdenci — dále značka Z) — enkláva relativně nejmladšího osídlení střčes. (oblastně příznakového) nářečního typu (na rozdíl od ostatního Dar., kde převažuje typ svč.); č. osídlení je zde většinou z l. 1880—90 (rodičovská generace dnešních nejstarších informátorů přišla sem jako docela malé děti; informátoři většinou znají ještě svůj původ). Obec je smíšená (podle soupisu z r. 1961, viz Mirk. 32n., 444 Čechů, tj. 33 %).
Ivanovo Selo (lid. Pémije — značka S) — nejstarší č. obec na Dar. se stabilizovaným širším oblastním typem svč.[5] (založ. 1825; předkové našich informátorů jsou už po několik generací zdejšími rodáky). Obec je téměř úplně č. (k č. národnosti se však hlásilo jen 623 obyv., tj. 81 %), ale leží už na samé periférii č. osídlení na Dar. v přímém sousedství s obcemi charvátskými a srbskými.
Dolany (Doljani — zn. D) — reprezentující okrajový nář. typ svč., resp. výchč.; č. osídlení — podobně jako jinde na Dar. — je zde převážně asi z l. 1860—80 (rodičovská a často i prarodičovská generace dnešních informátorů se již narodila zde, východisko kolonizace se většinou již nezná). Obec je smíšená (503 Čechů, tj. 50 %) a v blízkosti města Daruvaru, kde sch. obyvatelstvo výrazně převažuje.
Považujeme-li každé slovo dotazníku ČJA, podle něhož se výzkum prováděl, za samostatnou jednotku a registrujeme-li přitom všechny změny dané novým jazykovým vývojem č. nářečí v sch. prostředí (bez ohledu na to, zda jde jen o přejetí prvků hláskoslovných nebo slovotvorných, zda jde už o výměnu cizích lexémů nebo o zanikání č. slov z důvodů mimojazykových), dospějeme k závěru, že v tomto souboru lexikálních hesel, zahrnujícím rovnoměrně všechny důležité věcné okruhy jádra slovní zásoby průměrného venkovského mluvčího, se cizí vliv projevil v 23,12 % případů (389 z 1682 lexikálních jednotek). Přitom v jednotlivých zkoumaných obcích je celkový stupeň ovlivnění různý: v Z činí jen 8,20 % (128 slov), v S 17,30 % (291) a v D 19,26 % (324). Vedle těchto celkových výsledků umožňuje nám vnitřní diferencovanost materiálu i některá statistická šetření dílčí, která mohou z jiné stránky ukázat na některé důsledky cizího vlivu pro systém ovlivňovaného jazyka a také přispět k osvětlení úlohy některých faktorů nového jazykového vývoje v cizím prostředí.
1. K takovým zajímavým výsledkům patří zjištění, v jaké míře se projevuje cizí vliv vždy v rámci jednotlivých slovních druhů.
Výběr hesel pro dotazník ČJA je zaměřen na sledování nářeční diferenciace ve všech oblastech jazyka a výrazně zde převládají substantiva; ze zastoupení ostatních slovních druhů v tomto souboru je však zřejmé, že tento dotazník může být vcelku vhodným podkladem i pro tato statistická šetření. Z celkového počtu 1682 hesel v dotazníku připadá totiž na substantiva 64,60 % (1080 hesel), na slovesa 17,87 % (301), na adjektiva 7,07 % (119), na adverbia 4,86 % (82), na zájmena 1,60 % (27), na spojky a jiné spoj. výrazy 1,42 % (24), na číslovky 1,12 % (19), na interjekce 0,77 % (13) a na předložky 0,65 % (11); částic je minimálně a neuvádějí se samostatně.[6]
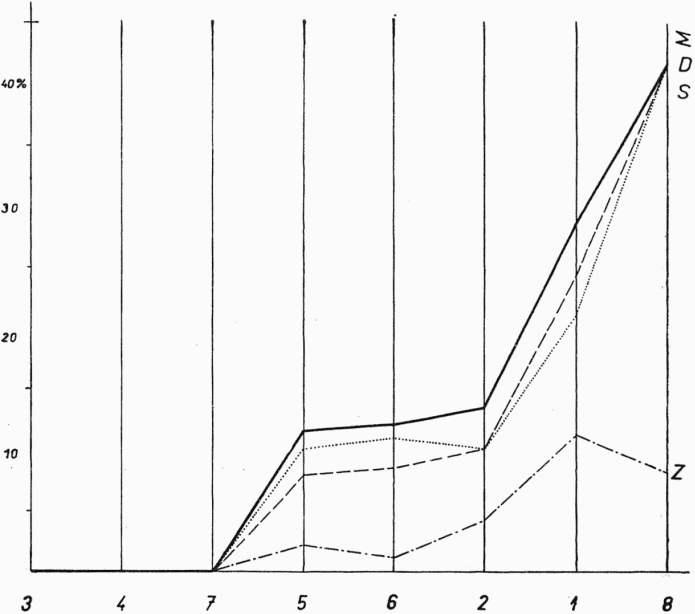
[304]Procento cizích vlivů, které ukázal náš materiál u jednotlivých druhů slov, uvádí graf 1 (s. 305).[7] Je zřejmé, že se tu rýsují tři skupiny slov. Nejvíce podléhají cizím vlivům spojky (41,66 % ovlivněných podob) a subst. (28,56 %), střední míru cizích vlivů vykazují adj. (13,44 %), adv. (12,19 %) a slovesa (11,62 %), zcela bez vlivu jsou zájmena, číslovky a předložky.[8] Podle poměrného zastoupení v celém souboru ovlivněných hesel připadá na jednotlivé slovní druhy tento podíl: subst. 79,92 %, slovesa 8,97 %, adj. 4,11 %, adv. 2,57 %, spojky 2,57 %, interj. 1,79 %, zájmena, číslovky a předložky 0 %.[9]
Pokud jde o substantiva, je jejich postavení nesporné.[10] Skutečnost, že substantiva patří k nejvíce ovlivňovaným slovním druhům, vyplývá z jejich základní funkce pojmenovávat substance a je obecně známa ze všech prací rozebírajících bilingvní materiál. Přitom naše zjištění se opírá o poměrně značný absolutní počet substantiv (1088 slov), protože výběr hesel pro dotazník ČJA je vedle základní slovní zásoby zaměřen také na běžně užívanou starou zemědělskou terminologii. Poněkud překvapující dominantní postavení spojek a spojovacích výrazů vůbec zřejmě souvisí s vyšší mírou cizích vlivů v syntaxi, jež se ovšem projevuje ani ne tak v přejímání cizích konstrukcí (Mirk. 314) jako právě daleko častěji v přejímání spojovacích výrazů (Sch-dč. 344); z 24 spoj. výrazů zařazených do dotazníku podlehlo cizímu vlivu 10, takže relativní celková míra ovlivnění je dokonce výrazně vyšší než u substantiv. Jen v Z, v obci s nejmenším stupněm cizího vlivu, je pořadí obou slovních druhů obrácené. Znamená to tedy, že syntaktické vlivy se začínají projevovat až při pokročilejším stupni bilingvismu, kdežto u substantiv pronikají cizí prvky už od samého začátku soužití jazyka s cizím prostředím. Zároveň je však třeba mít na zřeteli, že počet spojek a spoj. výrazů je omezen, takže zjištěná celková míra cizího vlivu — jako ostatně u všech slovních druhů s omezeným počtem slov — může být i na tomto faktu závislá.
U slovních druhů se středním stupněm ovlivnění očekávali bychom snad — jak bývá v bilingvním prostředí obvyklé — vyšší míru cizího vlivu u adverbií; avšak řada adverbií, u nichž k přejetí dochází (baš, bárem, makar, sigurno, još, onda, obično), nebyla do dotazníku ČJA zařazena. Skutečná míra přejatých adverbií — a ukázal by to např. statistický rozbor textů — je podle našich pozorování tedy i na Dar. vyšší,
[305]Procento cizího vlivu u jednotlivých druhů slov
|
| 27 | 19 | 11 | 301 | 82 | 119 | 1088 | 24 |
|
|
|
|
|
|
|
|
|
|
| Σ% | 0 | 0 | 0 | 11,62 | 12,19 | 13,44 | 28,56 | 41,66 |
| D | 0 | 0 | 0 | 7,97 | 8,53 | 10,08 | 24,26 | 41,66 |
| S | 0 | 0 | 0 | 10,29 | 10,97 | 10,08 | 20,95 | 41,60 |
| Z | 0 | 0 | 0 | 2,32 | 1,21 | 4,20 | 11,03 | 8,33 |
Slovní druhy jsou vyznačeny arabskou číslicí, míra cizího vlivu v jednotlivých obcích tenkými liniemi (Z — čárkovaně, S — tečkovaně, D — čerchovaně), silná linie udává vliv celkový. Pod grafem se pro každý slovní druh zvlášť uvádí počet sledovaných lexikálních jednotek a pak zjištěné procento cizích vlivů (celkově a pro jednotlivé obce).
Graf. č. 1
než je patrno z naší statistiky. Naopak u sloves vystihuje náš materiál míru cizího vlivu vcelku dobře, protože slovesa zařazená do dotazníku ČJA patří k základní slovní zásobě a jejich počet je i pro náš účel dostatečný. Ze zjištěných výsledků vyplývá zvlášť závažný rozdíl v míře cizího vlivu mezi slovesy a substantivy.[11] To, že slovesa [306]nepodléhají cizím vlivům v takové míře jako substantiva, zřejmě souvisí s celkovým rozdílným charakterem obou slovních druhů. Dost překvapující je však relativně větší míra cizích vlivů u adjektiv, vyplývající zřejmě ze skutečnosti, že jde o češtinu v příbuzném jazykovém prostředí, kde pronikání cizích prvků probíhá přirozeně, protože při užívání tvarů — na rozdíl od přejímání z jazyků nepříbuzných[12] — nečiní zvláštní potíže zařazovat přejatá adjektiva k příslušným morfologickým typům.
Ze slovních druhů, které zůstaly zatím bez vlivu, má zřejmě obecnou platnost zvláště zjištění o zájmenech.[13] Odpovídá to jejich celkové povaze a zároveň je to i v souladu se skutečností, že v dané fázi bilingvismu nepodléhá ještě dč. cizím vlivům v morfologii (Sch-dč. 343). Také údaje o předložkách vcelku souhlasí s očekávaným výsledkem; zřejmě to souvisí s jejich blízkostí k morfologii. Ovšem zcela bez vlivu předložky nejsou, jak je patrné z dokladů zachycených při výzkumu ze spontánního hovoru informátorů mimo soubor dotazníkových hesel (zvl. např. téměř důsledně užívané za, ‚pro’, ‚na’; další příklady viz Mirk. 291); nebereme-li v úvahu frekvenci předložkových vazeb, kde je cizí vliv častý, jde však zatím jen o několik málo výpůjček. Pokud jde o číslovky, je vzhledem k různorodosti tohoto slovního druhu jejich postavení ve statistikách problematické, v našem materiále se však dospělo k výsledku vcelku jednoznačnému, hlavně proto, že dotazník obsahuje jen nejběžnější základní, řadové a neurčité číslovky, vybrané většinou pro sledování nářečních rozdílů při skloňování. Tím se vysvětluje, že se tu cizí vliv zatím vůbec neprojevuje. Jinak právě naopak patří číslovky k případům, kdy k pronikání cizích vlivů dochází poměrně často, zvl. např. při uvádění letopočtů, dat a při počítání vůbec, neboť to je úzce spjato se složkou organizačně správní, tedy s oblastí, v níž se prestižní postavení ovlivňujícího jazyka jakožto jazyka správního projevuje nejmarkantněji.[14] Je ovšem možné, že k pravidelnému uplatnění tohoto cizího vlivu u číslovek dochází až v pokročilejším stadiu bilingvismu, protože např. v dč. nejsou zatím ještě ani tyto případy tak časté.
2. I když je zřejmé, že v lexiku se závislost jazyka na společenských podmínkách projevuje nejmarkantněji a že mimojazykové důvody mají proto na přejímání slov výrazný vliv, přesto je konkrétní stanovení nejvíce ovlivňovaných oblastí slovní zásoby velmi komplikované, protože na výsledném vlivu se může podílet řada nejrůznějších činitelů a jejich působení může být za různých podmínek různé. Na druhé straně však — i jen když srovnáváme slovenské a české práce z oblasti jazykových kontaktů — přece jen cítíme, že také působení mimojazykových vlivů na pronikání cizích prvků do lexikálního systému ovlivňovaného jazyka probíhá podle jistých obecněji platných zákonitostí. Ovšem konkrétní konfrontace je znemožněna tím, že některé i dost důkladné popisy materiál neanalyzují,[15] a pak hlavně proto, že neexistují jednotné tematické indexy, které by posloužily jako vhodná základna pro takovou konfrontaci.
[307]Částečný vhled do této problematiky umožní nám věcně významové uspořádání hesel v našem dotazníku. Řazení hesel je ovšem volné a je dáno hlavně metodickými hledisky pro potřeby terénního výzkumu.[16] Přesto však i při letmém pohledu na míru přejatých podob v jednotlivých tematických oddílech je závislost ovlivňovaných slov na věcně významových okruzích patrná.
2.1 V následujícím oddíle uvádíme v pořadí příslušných hesel dotazníku ČJA, řazených podle věcně významových okruhů, přehled všech případů, kdy v některé nebo ve všech zkoumaných obcích už došlo v dč. k ovlivnění sch. jazykovým prostředím. Číslo v závorce uvádí pořadí dané položky v dotazníku; hesla, u nichž k ovlivnění nedošlo, se neuvádějí. (Chybějící čísla však nemohou sloužit k průběžné orientaci o počtu slov, k nimž cizí vliv ještě nepronikl, protože v dotazníku se samostatnými čísly označují nikoli hesla, nýbrž i různé sledované tvary téhož slova.) Jiný slovní druh než subst. se za pomlčkou označuje příslušnou číslicí.
Za číselným označením hesel a slovního druhu se pak v rámci sledovaných slovních významů v zestručněné formě (hláskové a podobné varianty se většinou vypouštějí) uvádějí přejaté nebo ovlivněné podoby slov, popř. původní č. ekvivalenty užívané ve zkoumaných obcích; zásah cizích vlivů se vyznačuje kurzívou. Kde je to nutné, připojuje se význam. Stav a způsob užívání těchto podob se pak paralelně pro každou obec zvlášť (v pořadí Z S D) označuje buď nulou (cizí vliv v dané obci ještě nepronikl), nebo dvojmístným číselným, resp. písmenným symbolem (např. 95, C4). Značkami Z, S, D se příslušnost ekvivalentů k jednotlivým obcím označuje jen tam, kde není patrna z číselných symbolů. Při tomto označování se vychází ze skutečnosti, že u příbuzných jazyků je možno v postupném pronikání cizích prvků do ovlivňovaného jazyka stanovit různé stupně cizího vlivu (viz též dále v odd. 3) od pouhého přejímání formálních prvků až po výměnu cizích lexémů (stupeň ovlivnění se označuje cifrou 1—9 na prvním místě symbolu). Dále se označuje i míra zdomácnění ovlivněných nebo přejímaných podob (a to číselnou stupnicí 1—5 na druhém místě symbolu). Jakkoli je toto určování vzhledem k časté variabilitě užívaných podob jen přibližné, přece jen bylo možno při výzkumu aspoň rámcově stanovit, zda příslušná přejatá podoba žije paralelně s původním č. ekvivalentem jako dubleta (1 — řídká, 2 — běžná, 3 — převažující), nebo zda už je to označení jediné (4 — č. výraz se už jen pamatuje, zvl. z mluvy zemřelé generace, popř. je petrifikován ve frázích a ustálených spojeních, 5 — č. výraz zcela zanikl). Zvláštními typy jsou případy, kdy při přejímání sch. slov dochází zároveň u č. ekvivalentu k významovému posunu (označují se písmeny A, B, C na druhém místě symbolu) a zanikání slov z důvodů mimojazykových (označují se podle stupňů symbolem C1—C5).
Přehled všech stupňů ovlivňování zároveň s celkovou kvantifikací podle jednotlivých typů je uveden v tabulce 2; podrobný rozbor materiálu z tohoto hlediska viz Sch-dč. 335n.
1. Osada. (4) vopčina SD, mňesnej vodbor ZD 85 85 85; (6) starešina 85 85 85; (10) vopčina, opčina - obec 82 85 85; (11) kotár - okres 92 95 95; (27)-5 čitat - číst 0 25 0; (31) čitáňi - čteňi 0 22 0; (35) téka, kňíška ‚sešit‘ C2 95 95; (37) tinta - ingoust 0 95 92; (38) gumička SD, radír S - guma 0 95 95; (39) krajda - křida 0 85 0; (42) izložba - vejstava 0 95 0; (43) vároš - mňesto 0 92 0; (47) mlikárna, mlikara - mlíkárna 0 15 15/25; (60) pivovara, pivara - pivovár 0 25 22; (64) vúz - auto 0 0 32; (67) brána S, rampa ZD ‚závory‘ 65 65 65.
2. Obydlí. (86) kúča - barák 93 95 93; (101) hajda - chajda, barabizna 0 0 11; (111) présná cihla S, presňák D - vepřák 0 92 92; (112) škarba, škarbl D, sanduk S - kalfas 0 95 95; (113)-5 frajkat - nahazovat 92 95 95; (120) rítek - došek 0 95 0; (121) ‚břidlice‘ C5 C5 C5; (127) ďíra za seno házeňi - vitíř Z, viklíř D 03 C5 C3; (128) nástřeši - vokap 0 0 82; (131) tavan - húra, púda 91 95 94; (135) podrum - sklep 0 92 0; (136) gaňek - zápraš Z, záhrobeň D 9B 95 9B; (162) kachlik, cvjetňák - kvjetňik 0 85 65; (171) loket - visací zámek 0 65 62; (179)-6 šírem - dokořán 0 95 0; (181)-5 vokoupat se - vikoupat se 0 0 22; (182)-2 holej - nahej, nahatej 0 35 32.
[308]3. Domácnost. (184) kotlik za vodu, kotliček - kamnovec 0 45 42; (185)-2 bakrovej - mňeďenej 0 0 92; (203) šťípanice - šťepina 42 45 45; (208) šupa za dřívi D, drvárňice S - dřevňik, kúlna 0 8B 3B; (211) uhel - uhli 0 0 21; (224) loučka, lučka - louč 0 0 24; (235) kanta - vokúvek 93 95 95; (258) čaba, čabar - štandlik 0 0 92; (266) korice - deska 0 92 95; (272) stolice SD, židlice T - židle, židlička 22 32 31; (273) naslaňač - lenoch 0 0 91; (280) plachta - poslamka 0 35 32; (282) vaňkuš - polštář 0 95 0; (283) poulek, povlek ZD, vrch S - cejcha 31 45 31; (285) stolňák - ubrus 41 45 45; (309) kanťička ‚bandaska‘ 95 95 95; (317)-5 pomejt (stolky) S - umejt (nádobí) 0 2B 0; (325) kuvača - vařečka 0 95 0; (326) klechtačka - kvedlovačka 0 C4 42; (329) ríbeš (na turky) - strouhátko, struhadlo 0 9B 0; (331) solenka - slánka 21 0 2B; (345) ‚necičky‘ - kopaňa 9C 9C 9C.
4. Jídlo a pití. (401) bílí žgance - kucmoch, škubánki Z 0 94 0; (402) šufnudle - slejški, šulanki 82 C5 85; (404) bramboračka - bramborová placka 0 25 0; (419) loj - luj 0 15 12; (420) safaládi - buřti 92 C5 C5; (427) krupki (z kukuřice) - krupki 0 C1 C1; (428) čočka 0 C5 C4; (438) kajgana - pečení vejce 0 0 92; (448) poklop - vrcholec, korbílek 0 42 42; (454) švajckes - sejr 0 0 95; (461) kopaňka - vošatka 9B 9C 9B; (463) štruca ZS, vekna D ‚podlouhlý bochník‘ 35 35 35, (475)-6 tenko - tence 0 25 22, (480) houska ‚žemle‘ - houska 0 C1 0; (481) kifl - rohlik 0 91 0; (490) pekmez - povidla 0 95 0; (491) posipánki - posejpáňi 0 51 0; (520)-5 topit - škvařit ZD, viškvářet S 0 62 0; (524) slaňina - špek 35 35 33.
5. Oděv a obuv. (534)-2 zelenkasti - zelenavej 0 0 22; (548) pantalóni - kalhoti 0 9A 0; (549) pláťení kalhoti 0 C5 C5; (558) trégeri - šandi 0 0 91; (559) kravátka - šálka 0 C5 23; (562)-2 holohlavej ‚prostovlasý‘ 35 35 35; (564) minduše - olingre 0 95 0; (572)-2 običnej - običejnej 0 0 22; (584)-2 čvrstej - peunej 0 93 0; (608)-5 vizout - zout 0 22 22.
6. Hospodářská usedlost. (616) grunt - statek 35 35 33; (620) gazda - hospodář, pantáta Z 94 92 93; (621) gazdarice - hospodiňe, pajmáma Z 94 92 93; (628) sedlačka - selka 0 25 22; (629)-2 sedláckej - selskej 0 25 2A; (630) služebni - čelátka ZD, chasa Z 0 C5 43; (631) sluha ZS, slúga SD - chasňik Z, pacholek SD 41 42 42; (632) sluškiňe SD, sluška - ďevečka 22 25 23; (635) ‚podruh‘ C5 C5 C4; (637) stupec - sloup 0 0 91; (639) šlemeno S, štafl D - lígr 0 95 92; (640) bránka - lísa 0 3B 32; (641) brána - vrata 0 0 3B; (644) zaviradlo - závora 0 0 25; (650) úvoz - mlat 0 0 62; (651) párma - zádeň Z, přistodolek D 0 95 92; (660) šiváč, pošiváč D - vošiťí Z, svúra SD 0 82 82; (662) dreš - mašina, mláťička 0 0 92; (663)-5 mašinat - mašinovat 0 25 0; (664) ‚sýpka‘ - hambár 9C 9C 9C; (697) koňiček - formánek 0 0 45; (698) škarič - ramena 0 92 92; (699) zadňi škarič - gder 0 95 92; (700) puza, podvujka - podňíška 0 0 92; (701) osovina - náprava 0 0 82; (702) doleňi polička - akštuk 0 65 62; (703) polička - šárka 0 62 65; (709) taška - cuchta 0 0 62; (711) ‚brzdící špalek‘ C5 C5 C5; (712) bremzovat ZS, hemovat D - šlajfovat 92 92 92; (713) vobloha - loukoť 0 0 41; (714) palec - špice 0 0 62; (715) puška - vejtočka 0 0 63; (718) dlouhej vúz S, vús v lotrách D -žebřiňák 0 72 92; (719) drúgi S, drúšce D - bidla Z, richťini D 0 95 92; (720) šipka - mečik 0 6B 0; (726) kisna - hnojňík 42 45 45; krátkej vúz ‚fasuněk‘ C5 75 C5; (729) zábatek - čelo 0 0 91; (732) platon ‚plochý vůz‘ 95 95 95; (736) tački - kolečko 0 95 0; (738) lótrica - žebřiček 0 0 92; (740) ‚nůše‘ C4 C4 C4.
7. Dobytek. (745) svinec - chlívek 0 41 42; (749) žlábek - korito 0 0 32; (759) ‚opálka‘ C5 C5 C5; (800) pápek ‚pazneht‘ 95 95 95; (817) poušťí Z, bjehá se S, hledá řepce D - de ke koňum Z, g řepcum D 62 C2 0/C3; (837) hámi - chomouti 9B 9C 9B; (838) vohlavina - vohláuka 0 0 22; (840) žvala, žvale D - uďidlo ZD, čaňki S 0 92 92; (841) uzdi - vopraťe 0 35 33; (849)-2 levej kúň, levák - pocedňí C3/3 C3 C3; (850)-2 pravej kúň, pravák - náručňí C3/3 C3 C3; (852) bičála S, bičalice D - násatka 0 85 83; (853)-9 hajdi Z, hajde SD - vji, vije 92 95 92; (854)-9 oha - ou ZS, ej D 92 0 93; (855)-9 hajs - čehi 0 0 9B; (856)-9 štijoha - hot 0 0 9B; (857)-9 curuk - curik 25 25 0; (867)-5 mrská se - prská se 0 55 55; (869) jarec - kozel 0 95 95; (875) krmača - sviňe 0 0 91; (882)-2 je suprasná - sprasná ZD, soupraší S 0 0 11; (886) živinár - miškář 92 93 0; (887)-5 vištrojit, vijalovit -vimiškovat 0 92 0; (897) kuja - čuba, čupka 0 0 91.
8. Drůbež. (939) múček - záprdek 0 0 91; (943) sedadla - bidilko 0 0 42; (951)-5 gágá - kejhá 0 95 0; (955) podlíšťata 0 C5 C5; (956) čopor - hejno 0 92 91; (963) puran ‚krocan‘ 95 95 95; (964) púra ‚krůta‘ 95 95 95.
[309]9. Polní práce. (994) leďina - ouhor 92 92 95; (997) hlava - slubice 42 43 45; (1006) koňik - schlavi 0 0 45; (1007) karika - houžeu S, voko Z 0 0 95; (1008) škarič - drábec 0 0 93; (1014) drúg - paprsek 0 92 0; (1023) kosa z háčkem S, s kváčkem D - kosa 0 5B 9B; (1028) kosa ze sejtkem Z, maďarka D ‚hasák‘ C3 C5 55; (1043) korito Z, řbet D - podřatki 42 0 C3; (1060) kamara SD, kulatej a dlouhej stoh Z - stoh 55 9B 9B; (1082) koruska Z, gravorice S ‚směska‘ 95 95 C5; (1083) koruza ZD, kokorice S 95 15 95; (1097) trap ‚krecht‘ 95 95 95.
10. Zahrada a sad. (1104) šlivňák, vočňák - zahrada 0 85 0; vrt - zahrátka 92 95 0; (1105)-5 štijat - rejt 0 0 91; (1123) kanta - konev 0 95 95; (1133) paradajz ‚raj. jablko‘ 95 95 95; (1138) kerelába - kedlub 0 95 95; (1142) šnitlik 0 C5 0; (1143) sremkiňe Z, turkiňe ZD - turek 0 25/95 25; (1145) dřevo - strom 0 32 32; (1169) slíva - šveska 0 32 0; (1170) rogáč ‚bouchoř‘ C5 C5 95.
11. Krajina. (1208) pašňák - pastvíšťe 0 85 81; (1209) zajedňice ZS, pášňa - vobecňi pastvisko 95 95 92; (1220) uvala - oužlabina 0 91 0; (1237) bara - močál Z, mokřina D 0 95 0; (1239) močvara - bažina 0 92 92; (1249)-2 plitkej - mňelkej 31 35 35; (1250) izvor - pramen 0 0 91; (1256) plámka - láfka 0 0 9B; (1257) járek - strouha 33 0 35; (1259) šlajz - splau 92 95 95; (1262) plivat - plavat 0 0 62; (1265) mňeká cesta - polňí cesta 0 72 72; (1268) kolotočina - kolaj 0 0 93; (1272) drum - silňice 0 91 0; (1273) cestár, drumár S - cestář 0 15/95 11; (1274) járek ZD, graba S - příkop 35 93 33; (1275) závoj - zátočina 0 62 0; (1276) álej 0 C5 0; (1277) ludek S, cesta oužlabinou - hliboká cesta C3 95 C2.
12. Les a rostlinstvo. (1281) šikara SD, braňevina ZD ‚mlází‘ 95 95 95; (1282) borik D, borovice S - smrček 0 C2 83; (1283) smreka - borovice 0 C2 85; (1284) borovice ‚modřín‘ C5 C2 C5; (1285) mejlí 0 C5 C5; (1295) ‚jeřáb‘ C5 C5 C5; (1299) íva 15 15 15; (1301) lipa - lípa 0 0 12; (1302) stáblo, déblo - ťelo 0 95 94; (1306) grána S, gráň D - kmen ‚větev‘ 0 95 95; (1307) gráňka - kmínek Z, vjetvičky D 0 95 93; (1308) borovicoví, borikoví graňki ‚chvojí‘ C3 C3 C3; (1309) pichláki SD, jehlički D - jehličí 0 C2 C2; (1310) stelivo C1 C5 C5; (1312) suchár Z, suchí dřevo D - souš 23 C3 C3; (1316) lugár ‚hajný‘ 95 95 95; (1323)-5 rušit - kácet 0 61 61, (1327) klada - kláda 0 0 15; (1328) krčovina Z, virušenej les D 65 C5 C3; krčovina Z, šikara S, braňevina D ‚paseka‘ 95 95 95; (1329) páň - pařez 0 0 92; (1330)-5 krčit - dobejvat, tahat 0 C5 62; (1333) ‚borůvka‘ C5 C5 C5; (1334) ‚borůvčí‘ C5 C5 C5; (1335) jahodovi lisťi - jahodoví C3 0 C3; (1337) malina, modrá malina S - černá malina ‚ostružina‘ 0 C2 C2; (1342) modrák ZD, křemenáč S 0 C4 0; (1344) mlíčňice ‚ryzec‘ 85 C5 85; (1346) votrauná houba - prašifka 0 C3/42 0; (1347) muchara - mochomúrka 0 25 25; (1353) keře - křovi 0 C3 0; (1359) pugéta - puget Z, kitka ZD 2A 25 2A; (1367) chrpa C4 C5 C5; (1369) puzavec - šlatec 0 0 93; (1373) ivančice SD, svatojánská kitka Z - velká sedmikráska ‚kopretina‘ 7A 95 95; (1374) potočňice - pomněnka 0 0 85; (1375) žabinec S, potočňice D, žlutá kitka SD - žluťák ‚blatouch‘ 0 65/C3 85/C3; (1378) bokvice - celňik 0 0 93; (1380) kiselák S, kiselice D - šťovik 0 4A 44; (1382) mateř židouská - mateřidouška 0 52 0; (1383) číček - bubák ‚plod lopuchu‘ 95 0 95; (1384) šáš - rákos 95 0 0; šiška ZD, šíba S - pendrek ‚květenství orobince‘ 35 95 33.
13. Živočišstvo. (1389) škvor Z, střihauka S, ušák D C4 0 0; (1390) vodňi leptir, vodňí múra S - haďi hlava ‚šídlo‘ 03 C3 C3; (1394) chrušt - bapka, chroust D 0 0 13; (1398) šáka báka - sluňíčko Z, barunka SD 91 0 93; (1400) brabenečňik S, brabenči hňízdo D - brabeňíšťe 0 25 21; (1402) košňice - oul 8B 8B 8B; (1411) obád - brunďivár 0 95 95; gluván, malej obád D, velká moucha Z - koňská mucha C3 95 92; (1413) mucha - moucha 0 0 13; (1414) leptir - múra S, motovidlo D, motíl 0 0 93; (1416) gubar - housenka 0 0 92; (1419) mréža - pavučina, paučina SD 0 0 82; (1421) púž, spúž - šnek 0 0 93; (1422) púž, spúž - slimák Z, hubař D 92 0 95; (1426)-5 kreketá - rachá ‚kváká‘ 0 92 95; (1427) punoglávec - pulec 0 95 93; (1428) krastača ZS, gubavá žába D - rapucha 92 95 95; (1429) zelembáč - ješťerka 0 0 8A; (1430) slepič - slepák 25 23 22; (1442) ‚špaččí budka‘ C5 C5 C5; (1446) palčič, carič - paleček ‚střízlík‘ 92 22 25; (1448) šéwa - chocholouš 0 0 93; (1452) žúna, klobavec D, datl S - datel 0 12 95/55; (1453) trčka - koroteu 0 0 93; (1454) róda - čáp 93 95 95; (1456) slepičák - jestřáb 52 55 0; (1457) ťuwik - kulich Z, kalous S 0 0 95; (1458) šišmiš, slepej miš ‚netopýr‘ 95 95 95/75; (1459) štakor - ňemkiňe 0 0 93; (1460) krťice - krtek 0 25 25; (1461) krtorowina - krťina 0 0 25; (1462) lasice - kolčava 21 0 25; (1464) ďivokej zajic, polňi zajic S - zajic 0 22 22; (1466) jazavec - jezevec 0 15 15.
[310]14. Čas a počasí. (1472)-5 prošel - minul 0 42 0; (1492)-5 smrkuje se - stmívá se 0 2A 22; (1496) zjezďička — hvjezďička 0 15 15; (1505)-6 ňegdi - dřiu 0 42 0; (1516) tejden dňi - tejden 0 0 2; (l519)-2 prošlej - minulej 45 45 43; (1531) rujan S, devátej mňesic D - záři 0 95 94; (1542)-6 na rok, na příšťí rok D - napřezrok 23 2A 25; (1544) povjetrňice - vjetřice, vejr Z 0 0 22; (1545) magla - mha 0 83 0, (1547)-5 je mrhavo - mží 0 23 0; (1549)-6 je vošklivej den - je vošklivo 0 C3 0; (1563) vijavice - váňice, vjeje se 0 85 85.
15. Lidské tělo. (1591) brástka S, srózanej ksicht D - vrásek 0 93 93; (1599)-6 slabo - slabje 0 25 22; (1608) šilhoňa S, zrakavec D - šilhavej 0 22 83; (1609)-5 ďívat se zrakavje - šilhat 0 0 93; (1622)-5 klímá se D, klimbá se S - hejbá se 0 91 92; (1647) mozoul - pliskejř 0 C2 0; (1651) prsteňák C5 25 25; (1653) kršňaka - kršňa S, levačka 0 22 0; (1668) chrpteňača D, chrpteňica Z ‚páteř‘ 95 C5 95; (1698)-6 čerstvo - čerstva, richle 0 0 21, (1701)-5 žúrit se - tumlovat se, pospíchat 0 92 0; (1728)-5 čučet Z, čúčat SD - seďet na bopku 93 95 95; (1733)-5 zaspat - usnout 0 65 63.
16. Duševní vlastnosti. (1769)-2 strašlivej S, plašlivej - bojácnej 0 45 42; (1770)-5 pokazit - skazit 0 25 22; (1771)-6 pitomo - pitomňe 0 C5 21; (1773) klepňice, klepačka D, klepača S - klepna, drbna 0 22 22; (1784)-5 ustrašit S, uplašit D - polekat 0 42 43.
17. Rodina. (1798) tája Z, táta ZD - taťinek 81 0 81; (1799) majka Z, máma ZD - maminka 81 0 81; (1800) očuch - očim 0 85 0; (1812) báka - babička 0 0 83; (1813) únuk - vňuk, mňuk S 0 12 0; (1815) snáša - nevjesta 0 92 0; (1827)-2 slobodnej - svobodnej 0 15 0; (1839) človjek - múž 0 32 32; (1840)-2 krupná - široká, s ouťeškem 0 92 0; (1841) babica - porodňí bába Z, babička D 22 25 23; (1842) kúm - kmotr 92 0 92; (1843) kúma - kmotra 92 0 92.
18. Věkové stupně. (1854) dvojki - dvíčata 0 21 0; (1867) dúda - dudlik 81 85 85; (1869)-5 hrát se - hrát si 22 22 23; (1870) béba - pana 0 0 92; (1871) lopta - mičuda Z, mič S 94 9B 95; (1874) budem se naháňet ‚honěná‘ C3 C3 C3; (1881)-5 grúdat se - kuličkovat se Z, puškovat se D 0 85 0; (1884)-5 šličuchat se ‚bruslit‘ 95 95 95; (1885) rodle - sáňki 9B 0 91; (1886)-5 saňkat se, sáňkovat se Z 25 25 25; (1904) parňák - je se mnou starej ‚vrstevník‘ 0 92 92.
19. Nemoc a smrt. (1920) buleta - boule 0 8A 0; (1928) gripa - skřipka 95 95 93; (1939)-5 vozdravit se S, vozdravit D - vistonat se 0 82 82; (1941)-5 živit - žít 0 23 23.
20. Na vesnici nyní i dříve. (1949) zádruga ZS, zádruha D ‚družstvo‘ 95 95 95; (1952) polár D, polák - hlídač C5 25 23; (1953) spremišťe - hasická kulna 0 95 C5; (1954)-5 šprícat - tříkat 0 92 93; (1963) kamata - interes SD, ourok ZD 0 93 93; (1971) dučán - kvelb 95 95 94; (1972) mesňice - u řezňika 0 85 85; (1973) auzlog ‚výloha‘ 95 95 95; (1976) škarnicl - pitlik 0 9B 9B; (1992) ras 0 0 C5; mrceňíšťe - mrchovíšťe 0 85 85; (1994) flašinet 0 0 C5; (1996) choďí vot kuče do kuče ‚obec. chudý‘ C5 C3 C5; (2008) sudec 25 25 25; (2011) rešt, zátvor - arest, kreminál 92 22 23/95.
21. Zábavy a zvyky. (2018) rakije - kořalka 0 92 93; (2019) slivová kořalka, s. rakije - slívovice 0 C3 C3; (2020) čaša ZD, kupice S - skleňička 92 95 93; (2025) litra - litr 0 25 25; (2027) pušit - kouřit 0 91 0; (2028) duankesa - pitlik 0 95 0; (2029) kégla - kuželka 0 0 92; (2030) kule - koule 0 15 12; (2035) doviďéňa D, naschledanou - zbohem 0 72 72/92; (2057) preslica - přeslice 0 0 13; (2058) štrengle - přadeno 0 0 95; (2059) kadlec C5 0 0; (2067) smažeňice, smažinka D - kobliha 45 45 42; (2068) uskrz - velkonoce 0 0 93; (2076) ‚mazanec‘ C5 C5 C5, (2086)-2 nepoznatej - cízej 0 81 0; (2099) božič - vánoce 91 95 92; (2102) prvňi den svátku - bóží hod C3/2 0 C3; (2103) druhej den svátku - Šťepána C3/2 0 C3/2; (2109) pop - falář 95 92 93; (2116) kór, kóruš D - kruchta 35 33 35/85.
Gramatické dodatky. (2459)-8 da, ať - abisme 0 62/92 62/92; da - dibisme 0 95 92; (2524)-6 chťel nechťel SD, chceš nechceš S - chťíc nechťíc 0 25 25; (2551)-6 da - jo 0 92 92; (2554)-9 nekať - ajci 0 0 82; (2555)-9 evo - heleť 0 0 92; (2594)-8 i - a 0 32 32; (2595)-8 než, nežli - ale 62 65 65; (2596)-8 a gdebi, a kamoli - natož bi 0 85/95 85/95; (2601)-8 da ne - dibi ne, nebejt 0 92 92; (2602)-8 makar - třeba, i diž 0 95 95, (2603) makar D, da i SD, dibi i SD ‚i kdyby‘ 35 95 35/93; (2605)-8 da, ať - abi 0 65/95 65/95; (2611)-8 co ste to nevjeďeli? - copak 0 32 35.
2.2 Poučné je srovnání věcně významových okruhů, do nichž jsou seskupena hesla dotazníku, podle toho, v jaké míře k nim pronikly cizí vlivy. K tomuto srovnání jsou nejvhodnější substantiva, protože u ostatních slovních druhů se neprojevuje cizí vliv
[311]Substantiva ve věcně významových okruzích podle míry cizího vlivu
| Tematický okruh (podle dotazníku ČJA) | Počet subst. | Procento cizího vlivu | |||
| Z | S | D | Σ | ||
| 16. Duševní vlastnosti | 13 | 0 | 7,69 | 7,69 | 7,69 |
| 15. Lidské tělo | 49 | 4,08 | 12,24 | 8,16 | 12,24 |
| 5. Oděv a obuv | 38 | 0 | 10,53 | 7,89 | 13,16 |
| 19. Nemoc a smrt | 15 | 6,67 | 13,33 | 6,67 | 13,33 |
| 9. Polní práce | 82 | 9,76 | 10,97 | 14,63 | 15,85 |
| 14. Počasí a čas | 37 | 0 | 10,81 | 13,51 | 16,22 |
| 4. Jídlo a pití | 97 | 5,15 | 5,15 | 11,34 | 17,48 |
| 7. Dobytek | 71 | 5,63 | 12,68 | 16,90 | 18,45 |
| 10. Zahrada a sad | 52 | 5,77 | 19,32 | 11,54 | 19,23 |
| 8. Drůbež | 26 | 7,69 | 15,38 | 23,08 | 23,08 |
| 3. Domácnost | 86 | 9,30 | 17,44 | 19,77 | 23,26 |
| 2. Obydlí | 46 | 10,87 | 23,91 | 23,91 | 28,26 |
| 21. Zábavy a zvyky | 69 | 13,04 | 18,84 | 26,09 | 28,99 |
| 17. Rodina | 34 | 14,71 | 14,71 | 20,59 | 29,41 |
| 18. Věkové stupně | 19 | 21,05 | 26,32 | 31,58 | 36,84 |
| 11. Krajina | 41 | 12,19 | 31,71 | 29,27 | 41,49 |
| 6. Hospodářská usedlost | 97 | 13,40 | 27,83 | 40,21 | 42,27 |
| 12. Les a rostlinstvo | 89 | 22,47 | 35,96 | 40,45 | 43,82 |
| 1. Osada | 33 | 18,18 | 42,42 | 33,33 | 45,45 |
| 13. Živočišstvo | 68 | 19,12 | 25,00 | 47,06 | 50,00 |
| 20. Na vesnici nyní a dříve | 26 | 26,92 | 46,09 | 53,93 | 53,93 |
Tabulka č. 1
na dostatečném počtu případů. Z řady jednotlivých okruhů uspořádané vzestupně podle míry cizího vlivu (viz tab. 1) ukazuje se obecná tendence, že nejméně podléhají cizím vlivům slova, jejichž význam se více váže na domácí neveřejné prostředí a na tradiční okruhy života a práce uchovávané i v novém prostředí vcelku beze změny; naopak ty sémantické okruhy, které jsou úzce spjaty s vnějším světem a se životem v novém prostředí a které jsou vázány na živý každodenní kontakt s místním sch. obyvatelstvem, podléhají cizím vlivům nejvíce.
Jak je patrno z tab. 1, podle míry ovlivnění se vyčleňují tři rozdílné skupiny tematických okruhů. K okruhům s nejmenším vlivem (do 20 %) patří jednak „duševní vlastnosti“[17] a „lidské tělo“, „oděv a obuv“, „nemoc a smrt“ (vesměs méně než 15 %), jednak „polní práce“, „čas a počasí“, „jídlo a pití“, „dobytek“, „zahrada a sad“ (nad 15 %). Střed tvoří okruhy s 20—30 % ovlivněných slov, např. „domácnost“ (zařízení bytu) a „obydlí“ (zařízení domu) nebo „rodina“, „zábavy a zvyky“. U okruhů s největším vlivem dosahuje míra ovlivnění až okolo 50 %. Sem patří zvl. výrazy vztahující se k tamní přírodě („krajina“, „les a rostlinstvo“, „živočišstvo“), pracovnímu prostředí („hospodářská usedlost“, obsahující též pracovní nástroje, zvl. např. terminologii vozu) a společenskému životu („na vesnici nyní i dříve“, čast. např. též v odd. „hosp. usedlost“). Hodně z těchto přejímaných výrazů přichází do dč. prostřednictvím dětského světa, kde zpravidla dochází k ovlivňování zvlášť intenzívnímu (odd. dětských her je v okruhu
[312]Typy cizího vlivu a jeho kvantifikace u substantiv
| Typy cizího vlivu | Z | S | D | ||||
| počet | % | počet | % | počet | % | ||
| A, B. Přejímání cizích prvků a slov |
|
|
|
|
|
| |
| a) | formální obměny | 11 | 3,53 | 34 | 10,93 | 43 | 13,82 |
|
| 1. klada, zvjezďička | 2 | 0,64 | 9 | 2,89 | 15 | 4,82 |
|
| 2. sedlačka, mlikara | 9 | 2,89 | 25 | 8,04 | 28 | 9,00 |
| b, c) lexémy formálně české | 20 | 6,40 | 37 | 11,89 | 48 | 15,42 | |
|
| 3. holej ‚nahý‘ | 8 | 2,57 | 11 | 3,53 | 18 | 5,79 |
|
| 4. stolňák ‚ubrus‘ | 7 | 2,23 | 11 | 3,53 | 15 | 5,14 |
|
| 5. slepičák ‚jestřáb‘ | 2 | 0,64 | 4 | 1,29 | 2 | 0,64 |
|
| 6. mňeká cesta ‚polní cesta‘ | 1 | 0,32 | 5 | 1,61 | 3 | 0,96 |
| c) | 7. puška ‚zděř u kola vozu‘ | 2 | 0,64 | 6 | 1,93 | 9 | 2,89 |
| d) | lexémy formálně cizí | 59 | 18,97 | 107 | 34,41 | 137 | 44,69 |
|
| 8. vopčina ‚obec‘ | 9 | 2,89 | 18 | 5,79 | 26 | 8,36 |
|
| 9. kúča ‚dům‘ | 50 | 16,08 | 89 | 28,62 | 113 | 36,33 |
| C. | Zánik českých slov z důvodů |
|
|
|
|
|
|
|
| 1. houska ‚žemle‘ | 1 | 0,32 | 2 | 0,64 | 1 | 0,32 |
|
| 2. malina ‚ostružina‘ | 1 | 0,32 | 5 | 1,61 | 2 | 0,64 |
|
| 3. virušenej les ‚paseka‘ | 8 | 2,57 | 11 | 3,53 | 11 | 3,53 |
|
| 4. vdát se do podruže | 3 | 0,96 | 3 | 0,96 | 3 | 0,96 |
|
| 5. ‚borůvka‘ ø | 17 | 5,47 | 28 | 9,00 | 22 | 7,09 |
Rozlišení jednotlivých typů: (1) hláskoslovné varianty; (2) slovotvorné varianty; (3) vztah mezi sch. a č. ekvivalentem je obdobou polysémie; (4) metonymická pojmenování; (5) samostatné č. tvoření; (6) kalky; (7) mezijazyková homonymie; (8) cizí ekvivalenty geneticky příbuzné; (9) nepříbuzné ekvivalenty; (C1) č. slovo označuje blízký předmět; (C2) č. slovo zaniká — označení sémanticky blízkým slovem; (C3) opis, (C4) jen ustálená spojení; (C5) zánik č. slova bez náhrady.
Tabulka č. 2
„věkové stupně“), popř. ze školského prostředí (je v odd. „osada“; v této souvislosti lze též připomenout vliv školy na terminologii rostlin a živočišstva).
Hlavní tendence při uplatňování cizího vlivu jsou přitom zvlášť průkazné v některých detailech. Tak např. v odd. „dobytek“ se většina přejatých subst. týká koňského postroje a koní vůbec, kdežto hesla vztahující se ke krávě zůstala zatím cizího vlivu ušetřena. Stejně tak v odd. „oděv a obuv“ se většina výpůjček týká mužského oděvu, ale např. mezi desíti hesly vztahujícími se k domácímu spravování prádla není ani jediné přejetí. Rovněž u nejméně ovlivněných okruhů „lidské tělo“ a „duševní vlastnosti“ bychom většině přejetí mohli přisoudit společnou motivaci, že jde o slova označující předměty, které jsou nějak závažné při společenském styku (‚šilhavý člověk‘, ‚levá ruka‘, ‚prsteník‘; ‚klepna‘).
[313]3. Vedle zjišťování míry cizího vlivu podle příslušnosti slov k tematickým okruhům je možno na souboru substantiv, u nichž se projevil cizí vliv, sledovat, jak se při procesu pronikání sch. prvků do dč. projevuje jazykové příbuzenství, a ukázat tak, že při ovlivňování příbuzných jazyků se vedle závislosti cizího vlivu na faktorech spole-
Závislost cizího vlivu na jazykových a mimojazykových faktorech
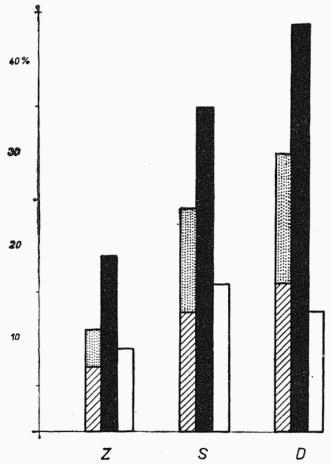
Tečkovaný sloupec — formální obměny (a); šrafovaný sloupec — lexémy formálně české (b, c); černý sloupec — lexémy formálně cizí (d); bílý sloupec — zánik č. slov z důvodů mimojazykových (C).
Graf č. 2.
čenských významně uplatňují i faktory jazykové. U příbuzných jazyků, kde část slovní zásoby i část slovotvorných a morfologických prostředků je společná, je totiž možno při posuzování cizích vlivů, které zároveň představují i jakousi stupnici „cizosti“ přejímaných prvků v č. slovní zásobě, sledovat různé stupně ovlivňování od pouhého přejímání formálních (hláskoslovných nebo slovotvorných) prvků při společných lexémech (a) přes různé typy přejímání cizích lexémů (b, c, d) až po zanikání č. slov z důvodů mimojazykových (C). Kvantifikace sch. vlivů podle uvedených stupňů ovlivnění je uvedena v tab. 2 na s. 312.
Přestože mezi různými typy ovlivnění zůstává přejímání cizích lexémů (d) i u příbuzných jazyků frekvenčně nejvýraznější (v D 44 % z ovlivněných slov), připadá ve zkoumaných obcích zpravidla více než dvě třetiny této hodnoty na souhrn typů, u nichž můžeme počítat se spoluúčastí faktorů jazykových (srov. na grafu 2): jde jak o případy (a), kdy vzhledem k shodě lexémů v obou ovlivňujících se jazycích se mohou uplatnit jen prvky formální (přitom varianty slovotvorné [2] jsou častější než hláskoslovné [1]), tak o různé typy přejímaných lexémů po formální stránce připomínajících č. slova; z nich jsou frekvenčně významné zvl. některé typy [3, 4], u nichž [314]je mezi přejímaným a původním č. ekvivalentem možno zároveň vidět i jistou souvislost sémantickou (b), kdežto případy bez této souvislosti (c) jsou přes svou výraznost obsahovou poměrně málo početné.
Zato se při změnách č. lexikálního systému výraznou měrou (v S 16 % ovlivněných slov) uplatňují v dč. faktory mimojazykové, vyplývající ze skutečnosti, že původní
Výskyt ovlivněných podob ve zkoumaných obcích u daných slovních významů
| Lexikální jednotky s cizími vlivy | Typy pozitivního výskytu cizích vlivů |
Celkem | |||||||
|
| Počet | +++ | ○++ | ○○+ | ○+○ | +○+ | ++○ | +○○ | |
| z celého | absol. | 116 | 114 | 78 | 59 | 16 | 3 | 3 | 389 |
| souboru | % | 29,82 | 29,31 | 20,06 | 15,16 | 4,11 | 0,77 | 0,77 | 100 |
| z toho | absol. | 99 | 85 | 65 | 41 | 15 | 3 | 3 | 311 |
| substantiva | % | 25,45 | 21,83 | 16,72 | 10,55 | 3,86 | 0,77 | 0,77 | 79,95 |
Vysvětlení symbolů + + +, ○ + + atd. viz v pozn. 19.
Tabulka č. 3
lexikální systém č. kolonistů se na Dar. musel částečně adaptovat vzhledem k poněkud odlišnému systému reality: č. slova, která neměla oporu v novém systému reality, postupně zanikají (C2—3) nebo už zanikla (C4—5).
4. Paralelní výzkum, prováděný týmž souborem lexikálních jednotek ve třech dar. obcích s různým stupněm cizího vlivu, umožňuje nám na konkrétním porovnatelném materiále alespoň částečně sledovat některé fáze postupně probíhajícího procesu ovlivňování. Že tento proces postupuje zákonitě, je ostatně zřejmé už i ze všech výše uvedených grafů a tabulek: linie označující míru cizího vlivu v jednotlivých obcích probíhají většinou paralelně a číselné údaje se diferencují stupňovitě; také směr narůstání cizího vlivu — až na některé výjimky[18] — odpovídá pořadí obcí při celkové míře cizího vlivu (Z S D).
Ještě markantněji se jeví charakter tohoto postupujícího procesu v nerovnoměrné frekvenci typů pozitivního výskytu ovlivněných podob sledovaných ve zkoumaných třech obcích, a to vždy v rámci jednotlivých slovních významů. Z postupného pronikání cizího vlivu totiž vyplývá, že zatímco u některých hesel se setkáváme s projevy cizího vlivu jen v jedné nebo ve dvou obcích, u jiných slovních významů pronikl cizí vliv už do všech tří obcí. Seřadíme-li všech sedm typů, určených z možných kombinací pozitivního výskytu,[19] podle frekvence (viz tab. 3), zjišťujeme, že nejčetnější je typ s pozitivním výskytem ovlivněných podob ve všech třech obcích (+++ 30 %). Z ostatních jsou frekvenčně významné jen typy s ovlivněnými podobami v druhé a třetí obci (○++ 29 %, ○○+ 20 %, ○+○ 15 %), kdežto [315]další kombinace s ovlivněnými podobami v první obci (+○+, ++○, +○○) jsou z tohoto hlediska zanedbatelné. Směr narůstání cizího vlivu je z takto zaměřeného srovnání jednotlivých typů výrazně patrný (viz graf 3). Část lexika přejatá v první fázi (30 % všech ovlivněných podob) je společná všem třem obcím. Přitom u obce
Poměrné zastoupení typů pozitivního výskytu ovlivněných podob ve zkoumaných obcích
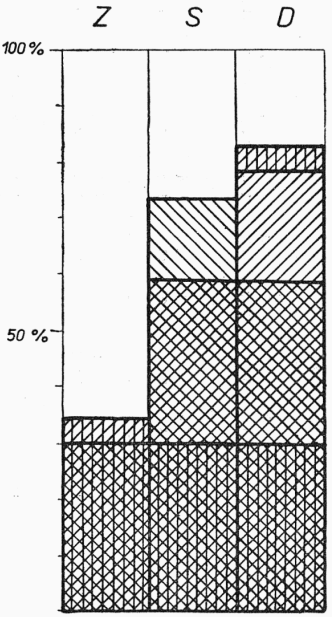
Příslušnost ovlivněných podob k jednotlivým zkoumaným obcím je vyznačena šrafami: Z — kolmé šrafy, S — levé šrafy, D — pravé šrafy.
Graf č. 3.
s nejmenším stupněm ovlivnění představuje tato část zároveň výraznou většinu všech ovlivněných podob vyskytujících se v této obci (80 %). V druhém sledu pronikají přejetí společná druhé a třetí obci, jež jsou stejně početná jako přejetí z první fáze. Třetí vrstvu tvoří změny vyskytující se jednotlivě jen v každé z těchto dvou obcí. Rozdíl v míře přejatých podob mezi těmito dvěma obcemi je dán především rozdílem právě v této třetí vrstvě.
Táž tendence se jeví, sledujeme-li v rámci jednotlivých typů nejen existenci nebo neexistenci těchto podob, nýbrž i to, jak postupuje proces zdomácňování přejímaných podob. Při výzkumu bylo totiž možno aspoň rámcově stanovit, zda se
[316]Zdomácňování přejímaných podob ve zkoumaných obcích
| Typy pozitivního výskytu | Z | |||||
| stupeň frekvence | celkem | |||||
| 1 | 2 | 3 | 4,5 | |||
| ○+○ | počet |
|
|
|
|
|
| ○○+ | % |
|
|
|
|
|
| ○++ | počet |
|
|
|
|
|
|
| % |
|
|
|
|
|
| +++ | počet | 8 | 27 | 13 | 68 | 116 |
|
| % | 6,90 | 23,28 | 11,21 | 58,61 | 100 |
| celkem* | počet | 13 | 36 | 17 | 72 | 138 |
|
| % | 9,42 | 26,08 | 12,32 | 52,18 | 100 |
| Typy pozitivního výskytu | S | |||||
| stupeň frekvence | celkem | |||||
| 1 | 2 | 3 | 4,5 | |||
| ○+○ | počet | 8 | 21 | 5 | 25 | 59 |
| ○○+ | % | 13,56 | 35,59 | 8,48 | 42,37 | 100 |
| ○++ | počet | 4 | 40 | 6 | 64 | 114 |
|
| % | 3,51 | 35,09 | 5,26 | 56,14 | 100 |
| +++ | počet | 0 | 16 | 10 | 90 | 116 |
|
| % | 0 | 13,79 | 8,62 | 77,59 | 100 |
| celkem* | počet | 12 | 77 | 22 | 81 | 192 |
|
| % | 6,25 | 40,10 | 11,46 | 42,19 | 100 |
| Typy pozitivního výskytu | D | |||||
| stupeň frekvence | celkem | |||||
| 1 | 2 | 3 | 4,5 | |||
| ○+○ | počet | 14 | 34 | 16 | 14 | 78 |
| ○○+ | % | 17,95 | 43,59 | 20,51 | 17,95 | 100 |
| ○++ | počet | 7 | 50 | 19 | 38 | 114 |
|
| % | 6,14 | 43,86 | 16,67 | 33,33 | 100 |
| +++ | počet | 3 | 13 | 23 | 77 | 116 |
|
| % | 2,59 | 11,21 | 19,83 | 66,37 | 100 |
| celkem* | počet | 27 | 100 | 64 | 133 | 324 |
|
| % | 8,23 | 30,87 | 19,75 | 41,05 | 100 |
Vysvětlení symbolů ○+○ ap. viz pozn. 19.
V celkovém součtu jsou zahrnuty i málo frekventované typy +○+, ++○, +○○, jejichž frekvence podle stupňů zde není uvedena.
Tabulka č. 4
[317]přejímaných a ovlivňovaných podob užívá ještě paralelně s původním č. ekvivalentem, nebo zda už je to označení jediné. Takto zjištěnou míru užívání vyjadřujeme u každého sledovaného hesla pomocnou frekvenční stupnicí (1—3 řídká, běžná a převažující dubleta, 4—5 bezvýhradné užívání). Celkovou kvantifikaci podle těchto
Poměr dubletně a bezvýhradně užívaných podob ve zkoumaných obcích (doplněk k tabulce 4)
| Typy | Z | S | D |
| ○+○ ○○+ |
| 0,84 | 2,43 |
| ○++ |
| 0,62 | 1,32 |
| +++ | 0,39 | 0,18 | 0,17 |
Tabulka č. 5
frekvenčních stupňů můžeme v každé zkoumané obci a pro každý typ výskytu zvlášt sledovat v tab. 4. Pro postižení hlavní charakteristiky daného typu výskytu přejatých podob jeví se jako nejdůležitější převaha podob užívaných bezvýhradně nad podobami dubletními (tedy poměr mezi frekvenčními stupni 2 a 5). Srovnáme-li relativní rozdíly poměru mezi těmito dvěma stupni (viz tab. 5), zjišťujeme, že ve směru od první obce k třetí (Z S D) a od nejfrekventovanějšího typu (+++) k typům méně frekventovaným (○○+, ○+○) jejich hodnota stoupá (srov. narůstající hodnotu tohoto poměru jak u typu +++, kde je rozdíl mezi obcemi, tak u obcí S nebo D, kde je rozdíl mezi jednotlivými typy). Ze srovnání vyplývá, že u nejfrekventovanějšího typu +++ měl proces zdomácňování přejatých podob zároveň možnost postoupit relativně nejdále (převažuje zde frekvenční stupeň 5 s bezvýhradným užíváním ovlivněných podob, a to v S a D daleko více než v Z).
Z našeho materiálu, který byl podkladem k statistickému rozboru frekvence přejímaných podob, je zřejmé, jak se se zřetelem ke kvantitě projevují hlavní vývojové tendence při přejímání slov v bilingvním jazykovém prostředí. Na rozdíl od situace ve spisovném jazyce, kde mívají přejímaná slova cizí specifický charakter,[20] stávají se přejímaná slova a tvary v dč. živou, zcela bezpříznakovou součástí slovní zásoby a fungují zde vedle původních podob č. vlastně jako pravá synonyma. Protože tedy nemají funkční uplatnění (nelze jich např. užít jako stylistického prostředku) a protože jde tedy o dvojí paralelní pojmenování, pak tam, kde má jazyk možnost se stabilizovat (např. v S), se této dubletnosti zbavuje jako nadbytečné. Při prestižním postavení ovlivňujícího jazyka se tak v daném případě děje zcela přirozeně postupným zánikem původních č. podob (srov. u typu +++ převahu stupně 5 ve všech obcích a situaci v S, kde se tato převaha projevuje u všech typů pozitivního výskytu přejímaných podob; naproti tomu situace v D, kde s výjimkou nejfrekventovanějšího typu +++ převažuje dubletnost, svědčí o tom, že zde tento proces probíhá daleko živelněji).
Závěr. Rozbor lexikálního materiálu z bilingvního prostředí na Dar., opírající se o statistická data, umožnil nám i z hlediska kvantitativního sledovat zvláště vzájem[318]ný poměr mezi jazykovými a mimojazykovými faktory při procesu ovlivňování. Ukázalo se, že přestože jde o příbuzné slovanské jazyky, převažuje při přejímání cizích prvků ten typ přejetí, který je bez jakékoli souvislosti s ovlivňovaným jazykem (viz graf 2). Dominantní postavení společenských faktorů je zvýrazněno ještě tím, že č. lexikální systém původních kolonistů se na Dar. musel přizpůsobovat už i poněkud odlišnějšímu systému reality. Dokonce se zdá, že míra cizích vlivů nepodmíněných jazykovým příbuzenstvím je v dč. možná ještě větší, než by měl v odpovídající fázi bilingvismu jazyk v nepříbuzném prostředí. Lze to vysvětlit tím, že v prostředí příbuzného jazyka nestaví se ovlivňovaný jazyk k přejímání cizích prvků tak negativně. Přičteme-li k tomu i samu celkovou hodnotu cizího vlivu podmíněného jazykovým příbuzenstvím, je zřejmé, že spoluúčast jazykových faktorů je při ovlivňování příbuzných jazyků významná.
Z obecných poznatků potvrzuje náš materiál několik známých skutečností, především fakt, že pronikání cizích prvků do systému ovlivňovaného jazyka probíhá nerovnoměrně. Výrazně to např. ukázal slovnědruhový rozbor přejatých podob (viz graf 1).
Pokud jde o faktory, na nichž je bezprostředně závislá míra cizího vlivu, vyplývá z možnosti srovnání mezi třemi obcemi s různým stupněm ovlivnění daným různými podmínkami, že důležité je především stáří kolonizace (srov. rozdílnou míru cizího vlivu mezi obcemi Z a D s rozdílnou dobou pobytu č. kolonistů na Dar.). Že ovšem tato podmínka neplatí absolutně, je zřejmé z toho, že obvyklý směr narůstání cizího vlivu u zkoumaných obcí (Z S D) neodpovídá pořadí obcí podle stáří kolonizace (Z D S). Rozdíl mezi obcemi S a D je v různé míře styku s cizím jazykovým prostředím (S ryze č. obec, D smíšená obec). Je tedy vedle stáří kolonizace důležitý i tento druhý faktor a výsledný vliv je dán hlavně kombinací obou těchto určujících faktorů.
R É S U M É
Zur Bewertung des Einflusses einer verwandten Sprache auf den Wortschatz einer tschechischen Mundart (Am Material der tschechischen Mundarten von Daruvar in Jugoslawien)
Der Einfluß des serbokroatischen Milieus auf tschechische Mundarten in der tschechischen Sprachinsel in der Umgebung von Daruvar in Jugoslawien ist bei Mitgliedern der alten Generation immer ziemlich klein, so daß das lautliche und morphologische System der tschechischen Mundart einstweilen fast unberührt bleibt. Am deutlichsten macht sich dieser Einfluß allerdings im Bereich des Wortschatzes bemerkbar. Da das Material, das bei Aufnahmearbeiten nach dem Fragebogen für den Tschechischen Sprachatlas in drei Orten mit verschiedenem Grad des fremden Einflusses gewonnen wurde, verhältnismäßig umfangreich und zugleich innerlich differenziert ist, haben wir die Möglichkeit, das Maß des serbokroatischen Einflusses auf den Wortschatz der tschechischen Mundart auch statistisch zu verfolgen. (Die drei Orte werden als Z S D bezeichnet.)
Bei verwandten Sprachen, wo ein Teil des Wortschatzes gemeinsam ist, kann man bei der Bewertung der fremden Einflüsse verschiedene Stufen der Beeinflussung verfolgen: von der einfachen Übernahme von formalen lautlichen oder Wortbildungselementen bei gemeinsamen Lexemen (a) über verschiedene Typen der Übernahme von fremden Lexemen, die in formaler Hinsicht an tschechische Wörter erinnern (bc) oder fremd sind (d), bis zum Untergang tschechischer Wörter aus außersprachlichen Gründen als Folge von einem etwas abweichenden System [319]der Wirklichkeit (C). Das Ganze all dieser Einflüsse kam in unserem Material in 23,12 % der Belege (389 von 1682 lexikalischen Einheiten) zum Ausdruck. Dabei ist in einzelnen Orten der Gesamtgrad der Beeinflussung verschieden: Z 8,20 % (128 Wörter), S 17,30 % (291), D 19,26 % (324). Die Quantifizierung der serbokroatischen Einflüsse nach den angeführten Graden der Beeinflussung ist in der Tafel 2 angeführt.
Auf dem Diagramm 2 kann man verfolgen, wie in den untersuchten Orten das wechselseitige Verhältnis zwischen den sprachlichen und den außersprachlichen Faktoren beim Prozeß der Beeinflussung zum Ausdruck kommt. Obwohl es sich um verwandte slawische Sprachen handelt, überwiegen die Typen der Übernahme, die ohne jeden Zusammenhang mit der beeinflußten Sprache sind (d — die schwarze Spalte, C — die weiße Spalte); aber auch der Gesamtwert des durch die Sprachverwandtschaft bedingten fremden Einflusses ist bedeutend (a — die punktierte Spalte, bc — die schraffierte Spalte).
Im Materialteil des Aufsatzes sind die angeführten Typen der Beeinflussung (bei jedem Stichwort in der Reihenfolge der Orte Z S D) durch die Ziffer 1—9 gekennzeichnet oder durch den Buchstaben C an der ersten Stelle des zweistelligen Symbols. An der zweiten Stelle dieses Symbols wird mit der Skala 1—5 der Grad der Einbürgerung der beeinflußten Gestalt angeführt (1—3 Dubletten werden mit dem tschechischen ursprünglichen Äquivalent benützt, 4—5 Untergang des tschechischen Äquivalents). Die Quantifizierung des Materials nach den Stufen dor Einbürgerung, die nach den Typen des positiven Vorkommens der beeinflußten Gestalten in den untersuchten Orten gegliedert ist (vgl. die Tafel 3 und das Diagramm 3), ist auf der Tafel 4 angeführt.
Von den allgemeinen Erkenntnissen bestätigt unser Material einige bekannte Tatsachen, vor allem aber die, daß die Durchdringung von fremden Elementen in das System der beeinflußten Sprache nicht regelmäßig vor sich geht. Das hat z. B. die Analyse der übernommenen Formen der Wortarten gezeigt (vgl. das Diagramm 1 — die betreffende Wortart ist durch eine Ziffer gekennzeichnet, das Maß des fremden Einflusses in den einzelnen Orten ist als dünne Kurven eingetragen, die starke Kurve gibt den Gesamteinfluß an). An Substantiven, die in der Regel zu den am meisten beeinflußten Wortarten gehören, kann gezeigt werden, wie die Abhängigkeit der beeinflußten Wörter von ihrer Zugehörigkeit zur bezeichneten Bedeutung zum Ausdruck kommt (vgl. die Tafel 1). Zu den wenig beeinflußten thematischen Bereichen gehören Wörter, deren Bedeutung enger mit dem häuslichen nichtöffentlichen Milieu und mit den traditionellen Lebens- und Arbeitsbereichen verbunden ist (z. B. seelische Eigenschaften und der menschliche Körper weniger als 15 %, Feldarbeiten und Vieh weniger als 20 %), während die semantischen Bereiche, die mit der Außenwelt und mit dem Leben im neuen Milieu eng verbunden sind, den fremden Einflüssen am meisten unterliegen (z. B. Wald und Pflanzenwelt, Ortschaft, Tierwelt bis 50 %).
Aus der Reihenfolge der Orte nach dem steigenden Maß der Beeinflussung, wie es in den Diagrammen zum Vorschein kommt, erhellt, daß das Maß des fremden Einflusses unmittelbar vom Alter der Kolonisation abhängt (nach Alter ist die Reihenfolge der Orte Z D S) und vom Maß der Kontakte mit dem fremden Sprachmilieu (S ist ein rein tschechischer Ort, Z und D sind gemischt). Das Ergebnis der Beeinflussung resultiert vor allem aus der Kombination dieser beiden bestimmenden Faktoren, so daß die gewöhnliche Richtung ihres Anwachsens bei den untersuchten Orten die Reihenfolge Z S D hat.
[1] Např. Frido Michałk studuje (hlavně na základě statistické analýzy textů) frekvenci některých výrazných jevů, zvl. hláskoslovných, v bilingvní oblasti lužickosrbské; viz čl. Přiňošk ke kwantifikaciji rěčneje interferency, Přinoški k serbskemu rěčespytnej, Budyšin 1968, 94—105 a řadu komentovaných německo-lužických nářečních textů Studien zur sprachlichen Interferenz I, II, Budyšín 1967, 1973.
[2] Viz zákl. monografii D. Mirkoviće Govori Čeha u Slavonii (Daruvar i okolina), Beograd 1968 (tam i další literatura o Dar.; zde dále zkr. Mirk.); rec. SaS 30, 1969, 431—437 a NŘ 53, 1970, 94—101.
[3] Na tomto materiále je též založen čl. Přizpůsobivost češtiny v srbocharvátském prostředí, Slavia 42, 1973, 329—346, přinášející jazykový rozbor sch. prvků v daruvarské češtině, tam i soupis důležitých č. a slov. prací z oblasti jazykových kontaktů (zde dále zkr. Sch-dč.). Tento čl. na něj navazuje.
[4] O dotazníku ČJA a o terénní práci s ním viz J. Voráč - M. Racková, Práce na českém jazykovém atlase, SaS 29, 1968, 312—318.
[5] P. Jančák, Čeština v Ivanově Sele v Jugoslávii, SaS 32, 1971, 241—257.
[6] Zatím chybí srovnání, jímž by se ověřila míra reprezentativnosti našeho souboru. Ze slovníkových lexikologických popisů jsou už k dispozici první údaje o zastoupení jednotlivých slovních druhů v SSJČ (byly vypočítány na základě údajů mechanografické laboratoře ÚJČ ze záznamů hesel SSJČ, a to z 199 767 jednotek základního hesláře): subst. 44,12 %, slovesa 23,14 %, adj. 22,58 %, adv. 7,45 %, interj. 0,69 %, čísl. 0,28 %, zájm. 0,14 %, spojky 0,13 %, předl. 0.09 % (značky aj. 1,38 %). Avšak i přes význačně odlišnou povahu, kterou tento úplný soupis spisovné č. slovní zásoby má, odpovídá mu v našem souboru aspoň pořadí prvních čtyř nejdůležitějších slovních druhů. K témuž pořadí prvních čtyř slovních druhů se dospělo i na základě statistické analýzy textů (viz J. Jelínek - J. V. Bečka - M. Těšitelová, Frekvence slov, slovních druhů a tvarů v českém jazyce, Praha 1961, s. 42; nebereme-li v úvahu zmíněnou výraznou převahu subst. v dotazníku ČJA, odpovídá náš soubor — i s ohledem na pořadí ostatních slovních druhů — spíše frekvenci hesel v dramatech, viz. tab. 5 na s. 46).
Nářeční slovní zásoba má ovšem v poměru k spisovné řadu specifických vlastností (viz Z. Sochová, Slovní zásoba nářeční a problémy jejího zpracování, SaS 28, 1967, 17—31). Uvážíme-li, že dotazník ČJA obsahuje z velké části hesla určená k sledování nářeční diferenciace, odpovídá plně tento soubor aktivní slovní zásobě průměrného venkovského mluvčího (odhadované podle Šmilauera a Weingarta asi na 5 000 slov, viz Sochová, s. 26). Také ze srovnání našeho souboru s údaji Leihenerovými (Cronenberger Wörterbuch, Marburg 1906) vcelku vyplývá, že percentuální zastoupení čtyř nejčetnějších slovních druhů je — až na vyšší zastoupení subst. v našem souboru — zhruba stejné (subst. 68/58 %, slovesa 20/27 %, adj. 7/10 %, adv. 5/5 %). Vyšší zastoupení subst. u minimalizovaných souborů je obvyklé (srov. např. Basic English, kde je z 850 slov 600 subst., 150 adj. a 100 ostatních).
[7] Za posouzení všech výsledků z hlediska matematickostatistického děkuji J. Králíkovi, prom. mat., z odd. matematické lingvistiky ÚJČ.
[8] Interjekce byla pro jednostranný výběr hesel a pro nízký absolutní počet z této statistiky vypuštěna.
[9] P. Beneš, Slavismy v rumunštině, SbPFFBU A18, 1970, 59—62 má mezi přejatými slovy 75 % subst., 16,7 % sloves, 6,7 % adj., 1 % adv. o 0,5 % číslovek, předložek a interj. Je zajímavé, že ač zde jde o přejetí z devíti jazyků realizovaných během staletí, odpovídá vcelku našim výsledkům nejen pořadí slovních druhů, nýbrž zhruba i vzájemná proporcionalita v míře ovlivnění.
[10] O důležitosti substantiv pro lexikální statistiku viz M. Těšitelová, On the Role of Nouns in Lexical Statistics, Prague Studies in Mathematical Linguistics 2, 1967, 121—139.
[11] Mezi hesly zasaženými cizím vlivem je podíl subst. výrazně větší (70,92 %) než ve výchozím souboru všech hesel (64,60 %); u sloves naopak je tento podíl o polovinu menší (8,97 % z původních 17,87 %).
[12] R. Šrámek, Působení neslovanského jazyka na české (lašské) nářečí, Slezský sb. 61, 1963, 158, upozorňuje, že strukturní odlišnost něm. a slovan. gramatické stavby je výraznou překážkou při přejímání něm. adjektiv.
[13] Z jiného hlediska dokumentoval různou stabilitu složek lexika už dříve ve svých příspěvcích A. Lamprecht, a to na materiále z lašských nářečí i na vztazích slovanských jazyků mezi sebou (viz zvl. K otázce základního slovního fondu v českém jazyce, SbPFFBU A 1, 1952, 58—81 a Osnovnoj slovarnyj fond i rodstvo jazykovych semej, SbPFFBU A 3, 1955, 5—10).
O stabilnosti zájmen svědčí podle Lamprechta shody ide. jazyků s jazyky uralskými, z pojmenovávacích slovních druhů jsou pak nejstabilnější základní slovesa. Stabilita zájmen je otřesena jen tam, kde jsou nahrazována zástupnými subst. typu pol. Pan.
[14] Dobře je to patrné např. v mluvě střelínských Čechů, kde se projevují vlivy dvou správních jazyků, dřív. němčiny a dnešní polštiny. Viz J. Voráč - P. Jančák, K dnešnímu stavu nářečí střelínských Čechů v Polsku, SlavPrag 4, 1962, 603.
[15] Např. K. Palkovič, Z vecného slovníka Slovákov v Maďarsku, Jazykovedné štúdie 2, 1957, 298—353 přináší velmi bohatý materiál, ale o konkrétní rozbor podle naznačených kritérií se nepokusil.
[16] Vedle slov pro příslušný rámcový věcně významový okruh charakteristických obsahuje dotazník také řadu slov z hlediska daných věcných významových kategorií nepříznakových a k jednotlivým okruhům jen volně připojených. Vzhledem k tomu, že tato vrstva slov je vcelku rovnoměrně rozřazena ke všem oddílům dotazníku, nebylo ani třeba daný soubor hesel pro statistické šetření zvlášť upravovat.
[17] Při označování jednotlivých okruhů se uvádějí v uvozovkách zestručněné názvy podle dotazníku ČJA.
[18] Např. ze sledu obcí Z D S (viz graf 2) je zřejmé, že zanikání č. slov bez náhrady z mimojazykových důvodů je přímo závislé na stáří kolonizace.
[19] K označení jednotlivých typů se užívá symbolů s kombinacemi znamének + (pozitivní výskyt cizího vlivu v některé obci) a ○ (obec bez vlivu) při zachovaném pořadí obcí Z S D; tak např. symbol + + + označuje typ s cizím vlivem ve všech třech obcích, symbol ○ + + typ s cizím vlivem v S a D, symbol ○ + ○ typ s cizím vlivem jen v D atd.
[20] Viz V. Blanár, Otázka prevzatých slov v slovanských jazykoch, Čs. přednášky pro VI. mezinár. sjezd slavistů, Praha 1968, 155—160.
Slovo a slovesnost, ročník 34 (1973), číslo 4, s. 302-319
Předchozí Šimon Ondruš: Stav a úlohy slovanskej a indoeurópskej historicko-porovnávacej jazykovedy v ČSSR
Následující Kolektiv oddělení jazykové kultury a stylistiky ÚJČ ČSAV: Účtování výsledků v současné sovětské a západní stylistice
© 2011 – HTML 4.01 – CSS 2.1