
Teorie sdělné promluvy
Jiří Krámský
[Discussion]
Теория языковой коммуникации / Théorie de la communication
I
Teorií sdělné promluvy rozumíme to, co je obsahem tzv. „communication theory“ (teorie komunikace). Od této teorie bychom měli lišit tzv. teorii informace („information theory“), avšak vzhledem k těsné souvislosti obou teorií není tento rozdíl většinou zachováván. Teorie informace je však zřejmě užším pojmem než teorie komunikace. Jestliže zavádíme[1] termín „teorie sdělné promluvy“, pak je to proto, abychom zdůraznili, že nám jde o sdělování prostřednictvím jazyka. Poněvadž však chceme vysvětlit základy teorie, které se týkají, jak uvidíme, daleko širšího rámce, než je promluva, budeme většinou používat termínu teorie komunikace nebo informace.
Jak naznačuje titul jednoho ze základních děl o informační teorii, totiž Mathematical Theory of Information, jehož autory jsou Claude E. Shannon a Warren Weaver, jde o teorii matematickou, která však, jak uvidíme, má určité, velmi důležité vztahy k lingvistice. V této studii nám půjde o to, abychom komunikační a informační teorii vysvětlili pokud možno v pojmech lingvistických a pokusili se určit její význam pro lingvistiku. Omezíme proto matematické termíny na nejmenší míru.
V širším rámci je teorie informace součástí tzv. kybernetiky, která je podle N. Wienera[2] „science of relations“. Jak píše Meyer-Eppler[3], je prvním cílem každého přírodovědeckého výzkumu procesů získání závazných výpovědí o procesu samém. Děje-li se bez spolupůsobení lidského jedince nebo je-li jím navozen pouze k účelům experimentálním, pak označujeme takový výzkum jako měření (Messung). O měření mluvíme i tehdy, vychází-li proces sice od lidského jedince, avšak probíhá nezávisle na svobodné vůli tohoto jedince. Proces, který je vyvolán vědomě, aby se jinému jedinci zprostředkovala zpráva, obsahuje jemnější kvality, než je pouhá energie: nazýváme je informací; ta se může prostřednictvím smyslových orgánů přenášet různým způsobem. U všech vyšších komunikačních forem, které nemají pouze funkci apelu nebo zprávy, nýbrž slouží představě věcného nebo smyslového obsahu, použije se znaků (Zeichen), které symbolizují význam toho, co se má představovat, nebo vytvářejí vztahy mezi významy. Tyto znaky tvoří zásobu (prearranged material, repertory), z níž se vybírá informace.
Sdělování pomocí řeči je jistě starší než zaznamenaná historie. Teprve však ve 20. století, které je věkem komunikace, dochází k soustavnějšímu vědeckému zkoumání problémů komunikace. R. 1924 a 1928 uveřejnil H. Nyquist dvě studie týkající se telegrafického přenosu a R. V. L. Hartley článek Transmission of Information (v Bell System Technical Journal, 1928, s. 535). Tyto práce sloužily za základ Shannonovi, který je spolu s Norbertem Wienerem vše[56]obecně pokládán za tvůrce teorie komunikace v dnešní její podobě. Shannon sám zdůrazňuje, že vděčí Wienerovi za filosofický základ pro svoji práci a Wiener opět poukazuje na to, že Shannonovi patří zásluha o nezávislé vypracování takových základních aspektů informační teorie, jako je pojem entropie.[4]
Doplňme ještě, že se v Sovětském svazu teorii komunikace dostalo značné pozornosti zejména v souvislosti s problémy strojového překládání (např. Kuzněcov, Ljapunov, Reformatskij, Zinder aj.), avšak pozornost se věnuje též kvantitativní lingvistice, jak o tom svědčí např. konference o jazykové statistice konaná v říjnu 1957 v Leningradu, o níž referuje V. A. Uspenskij v 1. čísle časopisu Voprosy jazykoznanija, 1958, č. 1, s. 170—173.
Že i u nás je živý zájem o teorii informace, ukazuje nám konference o teorii informace, statistických rozhodovacích funkcích a náhodných procesech, která se konala v Liblicích v listopadu r. 1956. Čeští vědci, převážně pracovníci Ústavu radiotechniky a elektroniky, podali zde spolu s cizími vědci, kteří se zúčastnili konference (D. Blackwell, B. V. Gněděnko, C. Rajski, H. Hansson aj.), řadu příspěvků k matematickým problémům teorie informace.[5] Pokud jde o lingvistický přístup k teorii informace, jsme dosud ve stadiu seznamování se s problémy. Právě účelem naší studie je seznámit čtenáře s problémy této teorie z hlediska lingvistického. Tím však, že zaujímáme i vlastní stanovisko k některým problémům teorie informace, chceme vyvolat diskusi a podnítit též u nás zájem o samostatný výzkum lingvistických problémů z hlediska této teorie.
Pojem komunikace a komunikační systém. S. S. Stevens definuje komunikaci (A Definition of Communication, JASA 22, 1950, s. 689—690) jakožto diskriminační reakci organismu na popud. Je to široká definice, která zahrnuje nejen psanou a mluvenou řeč, nýbrž i hudbu, divadlo, balet, malířství a ve skutečnosti vlastně všechno lidské chování.
Komunikačním systémem rozumíme tento systém:
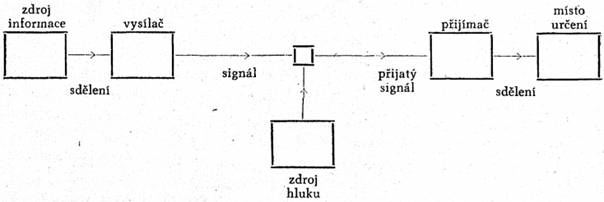
Skládá se v podstatě z těchto pěti částí:
[57]1. Zdroj informace, který tvoří sdělení, jež se má dopravit k příjemci. Zdroj informace vybírá žádané sdělení ze souboru možných sdělení. Vybraná sdělení mohou být psaná nebo mluvená slova, hudba, obrazy atd.
2. Vysílač, který zpracovává sdělení v signál, tedy tak, aby bylo schopno přenosu. Pokud jde o jazyk, jsou to slova, která přenášejí sled myšlenek. V psaném jazyku jsou to písmena nebo jiné symboly, v telegrafii je to sled teček, čárek a pauz.
3. Kanál, tj. prostředí, jehož se užívá pro přenos sdělení.
4. Přijímač nebo příjemce, který obyčejně provádí obrácenou operaci než vysílač: rekonstruuje sdělení ze signálu, např. dešifruje sdělení.
5. Místo určení, tj. osoba nebo věc, jíž je sdělení určeno.
Uveďme konkrétní příklady: Jde-li o telefon, je komunikačním kanálem drát, signálem elektrický proud v tomto drátě, vysílačem je vysílací telefonní přístroj. V telegrafii vysílač šifruje psaná slova ve sledy přerušovaného proudu různé délky (tečky, čárky, pauzy). V mluveném jazyku je zdrojem informace mozek, vysílačem je hlasový mechanismus vytvářející měnlivý zvukový tlak (signál), který je přenášen vzduchem jakožto komunikačním kanálem. Přijímač mění přenášený signál zpět ve sdělení a dopravuje toto sdělení dále k místu určení. V případě mluveného jazyka je tedy přijímačem ucho a s ním asociovaný nerv příjemce.
Do procesu přenosu mohou vstoupit ještě jiní činitelé, kteří určitým způsobem ruší přenos. Může to být např. zkreslení zvuku (v telefonu), zkreslení tvaru (v televizi) apod. Takové změny v přenášeném signálu se nazývají hluk (noise). O významu hluku se ještě zmíníme.
Základní pojmy komunikační či informační teorie, které je nutno vysvětlit, jsou pojem informace, entropie, nadbytečnosti a princip přenosu informace.
Pojem informace. Slova „informace“ je v této teorii užito v speciálním smyslu, který nesmíme zaměňovat s pojmem „významu“. Informace se nevztahuje k sémantickému obsahu sdělení. K účelům komunikace je význam sdělení irelevantní. Ve skutečnosti dvě sdělení, jedno mající význam a druhé bez jakéhokoli smyslu, mohou být, pokud jde o informaci, zcela ekvivalentní.
Slovo „informace“ se v teorii komunikace nevztahuje tak na to, co říkáme, jako na to, co bychom mohli říci. To znamená, že informace je mírou naší svobody při výběru sdělení. Pojem informace se vztahuje nikoli k individuálním sdělením (jako by se vztahoval pojem významu), nýbrž spíše k situaci jako celku; v této situaci máme při výběru sdělení určitou svobodu volby, kterou považujeme za standard nebo jednotku množství informace.
Množství informace je definováno v nejjednodušších případech tím, že se měří logaritmem počtu možných případů volby.
Poněvadž je pohodlnější užít logaritmu k základu 2 než obyčejného nebo Briggsova logaritmu k základu 10, je informace v případě dvou voleb proporční k logaritmu 2 k základu 2. Tato jednotka informace se nazývá bit (slova bylo poprvé užito J. W. Tukeyem a je kondenzací výrazu „binary digit“). Jsou-li čísla vyjádřena binárním systémem, jsou pouze dvě číslice, totiž 0 a 1, stejně jako deseti číslic, od 0 do 9, se užívá v decimálním číselném systému, který má za základ 10. Nula a jednotka mohou symbolicky představovat kteroukoli ze dvou případů volby, takže je přirozené spojovat „binární číslici“ neboli „bit“ se situací dvojí volby. Máme-li např. 16 alternativních sdělení, mezi nimiž můžeme volit, pak (ježto 16 = 24, takže log2 16 = 4), je situace charakterizována 4 bity informace.
Dosavadní výklad se týkal jednoduchých situací. Přirozenější a důležitější je situace, kdy zdroj informace volí z nějaké skupiny elementárních symbolů, při čemž sled, který vybereme, pak tvoří sdělení. Zde však vystupuje již do popředí úloha pravděpodobnosti, neboť tyto volby jsou, při nejmenším z hlediska komunikačního systému, ovládány pravděpodobnostmi, a to pravděpodobnostmi, které nejsou nezávislé, nýbrž v každém stadiu procesu závisí na předcházejících výsledcích volby. Tak např. v případě angličtiny, je-li poslední zvolený symbol the, pak pravděpodobnost, že další slovo bude člen nebo sloveso kromě verbálního tvaru, je velmi malá. Tento vliv pravděpodobnosti sahá přes více slov než dvě. Tak např. pravděpodobnost, že po třech slovech in the event bude následovat jako příští slovo that je dosti vysoká a že bude následovat slovo elephant je pravděpodobnost velmi nízká.
Proces, kdy se sled symbolů vytváří podle jistých pravděpodobností, se nazývá stochastický proces a zvláštní případ stochastického procesu, v němž pravděpodobnosti jsou zá[58]vislé na předchozích událostech, se nazývá Markovovův proces. Speciální třída Markovových procesů, která má primární důležitost pro teorii komunikace, jsou tzv. ergodické procesy. Ergodický proces je ten, který vytváří sled symbolů, při čemž každý symbol směřuje k tomu, aby byl representativní pro sled jakožto celek.
Entropie a nadbytečnost. Pojem entropie, zavedený ve fyzice téměř před sto lety Clausiusem a těsně spjatý se jmény Boltzmanna a Gibbse, který mu dal hluboký význam ve svém klasickém díle o statistické mechanice, stal se základním pojmem fyziky. Ve fyzice je entropie mírou stupně smíšení nebo nahodilosti částic, složek fyzikálního systému; je to vlastně nespořádaný stav systému.
Že informace je měřena entropií, je přirozené, když si uvědomíme, že informace je v teorii komunikace spojena s množstvím volnosti či svobody výběru, kterou máme při konstrukci sdělení. Tak pro komunikační zdroj stejně jako pro termodynamický soubor složek můžeme říci: „Tato situace je vysoce organizovaná, není charakterizována vysokým stupněm nahodilosti nebo výběru, tedy informace (nebo entropie) je nedostačující.“
Když vypočítáme entropii (nebo informaci neboli volnost výběru nebo volby) určitého informačního zdroje, můžeme ji srovnávat s maximální hodnotou, kterou by tato entropie mohla mít za předpokladu, že zdroj bude užívat stále týchž symbolů. Poměr aktuální entropie k maximální entropii se nazývá relativní entropie zdroje. Jestliže relativní entropie určitého zdroje je např. 0,8, znamená to zhruba, že tento zdroj je ve svém výběru symbolů, které mají tvořit sdělení, asi na 80 % tak svobodný, jak by mohl být s týmiž symboly. Odečteme-li od jedné relativní entropii, dostáváme nadbytečnost („redundancy“). Je to zlomek struktury sdělení, který je určen nikoli svobodnou volbou odesílatele, nýbrž spíše statistickými pravidly ovládajícími užití dotyčných symbolů. Tento zlomek sdělení je nadbytečný v tom smyslu, že kdyby chyběl, sdělení by stále ještě bylo v podstatě úplné; nebo alespoň by se dalo doplnit. Nadbytečnost angličtiny je asi 50—60 %, takže asi polovina písmen nebo slov, která volíme při psaní nebo hovoru, podléhá naší svobodné volbě a asi polovina je kontrolována (ač si toho zpravidla nejsme vědomi) statistickou strukturou jazyka.
Hodnota entropie, která se značí H, je největší, když dvě pravděpodobnosti jsou rovné (tj. když jsme úplně svobodni při volbě) a směřuje k nule, když není žádná svoboda volby.
Jestliže máme více než dva případy volby, pak entropie je největší, když pravděpodobnosti různých případů volby jsou téměř stejné. Předpokládejme na druhé straně, že jedna volba má pravděpodobnost blízkou jedné, takže všechny ostatní volby mají pravděpodobnost blízkou nule. To je situace, kdy je člověk velmi silně ovlivněn k určité volbě a má tudíž malou svobodu volby. Entropie H v takovém případě má velmi malou hodnotu, čili informace (svoboda volby, nejistota) je nízká.
Vidíme, že informace je tím větší, čím jsou více stejné pravděpodobnosti různých případů. Jiným důležitým způsobem vzrůstu entropie H je zvětšení počtu případů. Jestliže všechny případy volby jsou stejně pravděpodobné, pak čím více je těchto případů, tím větší bude entropie H. Informace je větší, jestliže vybíráme svobodně ze skupiny např. 50 standardních sdělení, než když vybíráme ze skupiny pouze 25 sdělení.
Přenos informace. K přenosu informace je nezbytný „komunikační kanál“. Jak jsme již řekli, je to prostředí užité k přenosu signálu z vysílače k přijímači. Může to být několik drátů, kabel, svazek rádiových frekvencí, paprsek světla atd.
Všimněme si nejprve, jak se informace přenáší. V případě, jako je telefonování, mění se slyšitelný hlasový signál v něco, co je sice jasně odlišné, avšak jasně ekvivalentní (střídavý elektrický proud v telefonním drátě). Přenosce však může provést mnohem složitější operaci na sdělení, aby vytvořil signál. Může užít např. nějakého kódu a šifrovat sdělení např. sledem čísel; tato čísla jsou pak poslána kanálem jako signál. Funkcí vysílače je tedy šifrovat sdělení a funkcí příjemce je dešifrovat toto sdělení. Nejúčinnější druh šifrování je takový, který je nejvhodnější [59]pro kanál, kdy tedy signálová entropie je rovna kapacitě kanálu. Musíme totiž brát v úvahu schopnosti kanálu ovládat různé signálové situace. Tak např. v telegrafii musí být mezi tečkami, tečkami a čárkami a mezi čárkami mezery, protože jinak by tečky a čárky byly nerozeznatelné.
Uvedeme-li do kanálu hluk, obsahuje přijaté sdělení určité zkreslení, jisté chyby, čili vykazuje zvětšenou nejistotu. Je to ovšem jiný druh nejistoty, než s jakým jsme se dosud setkali. Nejistota, která vzniká následkem svobodné volby při sdělení, je nejistota žádoucí, kdežto nejistota, která vzniká následkem chyb nebo vlivem hluku, je nejistota nežádoucí. Z toho plyne praktický důsledek: Poněvadž angličtina je asi na 50 % „nadbytečná“, bylo by možno ušetřit v telegrafii asi polovinu času řádným šifrovacím procesem za předpokladu, že bychom signály přenášeli bezhlučným kanálem. Je-li však v kanálu hluk, je jistá výhoda v tom, neužije-li se šifrovacího procesu, který eliminuje všechnu nadbytečnost, neboť právě nadbytečnost pomáhá bojovat proti hluku.
Souvislá sdělení. Kromě sdělení tvořených přetržitými symboly, jako jsou slova tvořena z písmen, věty ze slov, melodie z not, mohou být sdělení souvislá, jako je souvislá mluva se stálou variací výšky a energie. Teorie v tomto případě není rozdílná, pouze je nesnadnější a matematicky složitější; pokud jsou zde změny, jsou jen menší.
Všeobecnost teorie komunikací. Teorie komunikace je tak všeobecná, že není potřebí říci, o jaký druh symbolů jde, zda o písmena nebo slova, mluvená slova, noty, symfonickou hudbu nebo obrazy. Je dále tak hluboká, že vztahy, které odhaluje, lze aplikovat na tyto všechny i jiné formy komunikace. Základní vztahy platí všeobecně, ať má určitý případ jakoukoli speciální formu.
Teorie ta je ve skutečnosti základní teorií kryptografie, což je ovšem forma kódování. Teorie komunikace dále přispívá k překladu z jednoho jazyka do druhého a je též těsně spojena s teorií počítacích strojů.
Vysvětlili jsme stručně základní pojmy teorie komunikace, nutné k zjednodušenému porozumění teorii. To postačí i k dalšímu sledování výkladů, které se týkají aplikace teorie komunikace na problémy lingvistické.
II
Lingvistický výklad entropie a nadbytečnosti. V této studii se nemůžeme přirozeně zabývat všemi lingvistickými problémy, na které lze aplikovat komunikační či informační teorii. Soustředíme se proto hlavně na lingvistický výklad entropie a nadbytečnosti.
Jak jsme již řekli, o entropii mluvíme tehdy, když složky fyzikálního systému jsou smíšeny, kdežto jsou-li oddělené, jsou-li v činnosti nebo v klidu, mluvíme o „spořádaném stavu“ systému.
Podobný rozdíl můžeme předpokládat i pro lingvistický systém. „Spořádaný stav“ zde koresponduje s uváženým výběrem slov, při čemž každé slovo je vybráno nezávisle na ostatních. Ovšem píšeme-li o nějakém předmětu obšírně, musíme vzít v úvahu slova a gramatické vztahy, kterých jsme již užili, i těch, kterých potom užijeme, abychom se vyhnuli nežádoucímu opakování výrazu. Na námitku, že volíme-li nějaký výraz, abychom se vyhnuli jinému výrazu, je to již determinující akce, můžeme říci, že to je odlišný způsob determinace. Nevolíme výraz proto, že je nejlepší možný, nýbrž proto, že je stejně možný nebo vhodný jako jiný, kterému se chceme vyhnout.
Entropie je podle Shannona[6] statistický parametr, který měří, kolik informace je tvořeno průměrně pro každé písmeno textu v jazyce. Je-li jazyk transponován do binárních číslic (tj. 0 nebo 1) nejúčinnějším způsobem, je entropie H průměrný počet binárních čísel na písmeno jazyka. Na druhé straně nadbytečnost měří množství nátlaku (constraint), který vykonává na text struktura jazyka, např. v angličtině vysoká frekvence písmene E, silná tendence H následovat po [60]T nebo tendence U následovat po Q. Bylo vypočítáno, že bereme-li v úvahu statistické účinky nepůsobící více než přes osm písmen, je entropie zhruba 2,5 bitu na písmeno a nadbytečnost asi 50 %.
Tím, že kombinujeme experimentální a teoretické výsledky, můžeme vypočítat horní a dolní mez pro entropii a nadbytečnost.
Z této analýzy vyplývá, že v literární angličtině redukují statistické účinky (až do 100 písmen) entropii asi na 1 bit na písmeno S korespondující nadměrností zhruba 75 %. Nadbytečnost může být ještě větší, bereme-li v úvahu strukturu prostírající se přes odstavce, kapitoly atd. Ovšem vzrůstá-li délka, stávají se příslušné parametry nejistějšími a mnohem kritičtěji jsou závislé na typu textu.
Shannon a jiní badatelé uvážili při zjišťování nadbytečnosti jen omezení daná strukturou jazyka a nevzali v úvahu další omezení daná posluchačem a situací, v níž se mluvčí sám nachází. Proto, jak píší F. C. Frick a W. H. Sumby,[7] byla provedena informační analýza toho, co autoři nazývají „sublanguage“ jazyka užitého při kontrole letadla operatéry kontrolních věží letišť. Vezmou-li se v úvahu situační i lingvistické kontexty, stoupne nadbytečnost na 96 %.
Velmi instruktivní jsou pokusy s nadbytečností na tištěných textech, které popisuje Werner Meyer-Eppler (op. cit., s. 341—347). Jestliže v německém textu nahradíme všechny samohlásky čárkou, můžeme přes toto značné znetvoření textu více méně bez námahy uhodnout znění: M-N K-NN D--S-N S-TZ --CH -HN- V-K-L-L-S-N.
Důvod pro vysokou nadbytečnost německých textových slov je nutno hledat ve skutečnosti, že možnosti, s nimiž samohlásky a souhlásky tvoří slova určité délky, jsou v němčině jen velmi neúplně využity. Tak v případě M-N je možné jen jediné doplnění, totiž MAN, zatím co jiné myslitelné formy (MEN, MIN, MON atd.) se nevyskytují.
Předložíme-li nesystematicky porušené texty většímu počtu pokusných osob, můžeme získat číselné hodnoty pro nadbytečnost. Ukázalo se, že z německých tištěných textů byla uhodnuta více než polovina písmen, takže nadbytečnost obnáší přes 50 %.
Porušení textu se nemusí dít jen odstraněním celého znaku. Tak např. slovo NACHRICHTEN je podrobeno určitým zásahům. Ukazuje se, že i po odstranění poloviny každého písmene (může chybět buď horní nebo dolní polovina) zůstává slovo plně čitelné; také zde obnáší nadbytečnost asi 50 %. Různé porušení textu vyvolává různou čitelnost až nečitelnost textu. Proti tisku je u rukopisu nadbytečnost značně zmenšena, zde při vynechání částí znaku dochází téměř k úplné nečitelnosti.
Zajímavá je otázka zhuštění (komprese) tištěných textů. Podáváme-li telegram německy, mohli bychom ušetřit poštovné za více než polovinu písmen, protože příjemce by mohl na základě nadbytečnosti chybějící písmena uhodnout. Shannon ukázal, jak určitým kódováním lze nadbytečnost odstranit bez ztráty informace a zároveň dát zprávě minimální rozsah. Tento proces ukazuje Meyer-Eppler na slovu NACHRICHTENVERBINDUNGEN. První krok zhuštění pozůstává v tom, že v němčině nejhojnější páry písmen nahradíme řídce se vyskytujícími jednotlivými písmeny a místo řídce se vyskytujících jednotlivých písmen, která by se měla vyskytnout v textu, užijeme neužívaných párů písmen. P. Valério uvádí jakožto šest nejhojnějších německých diagramů: EN, ER, CH, ND, DE, IE.
Jestliže tyto diagramy nahradíme nejřidčeji užívanými jednotlivými písmeny: Y X Q J P V a jediné z těchto písmen, které se vyskytuje ve slově Nachrichtenverbindungen, totiž V, nahradíme digramem HC, pak vznikne NAQRIQTYHCXBIJUNGY.
Tímto prvním kódováním se délka slova redukovala z 23 na 18 písmen, aniž to je na újmu informace obsažené ve slově. Myšlenka nahradit a tím vyjádřit nejhojnější elementy vyskytující se v řeči pokud možno jednoduchými znaky a komplikovanější znaky řidčeji se vyskytujících elementů ponechat nalézá se ostatně již v Morseově abecedě. Je ovšem přizpůsobena frekvenční struktuře angličtiny a uvádí nejkratší znak, tečku, za E jakožto nejfrekventovanější anglické písmeno.
Účinnost kódu. Kód musí být účinný a ekonomický, pokud jde o úsilí vyžadované pro komunikaci. Jedním z nejdůležitějších axiómů v této věci je požadavek, že se má užít nej[61]menší kombinace elementů pro nejčastěji se opakující lingvistickou formu a že délka kombinací by měla být v obráceném poměru k frekvenci výskytu. Je zcela možné, aby kódový systém byl dobrý, pokud jde o užití kombinatorické metody, avšak neuspokojivý, pokud jde o ekonomii práce. Morseův kód například, ač plně využívá možností, které poskytuje dvoupísmenový kód, neaplikuje systematicky zmíněný ekonomický princip. Tento princip vyžaduje, aby se užilo všech krátkých kombinací a aby se nejkratší kombinace užilo pro nejčastěji se vyskytující písmena. První požadavek je v Morseově kódu splněn, avšak druhý nikoli, nebo jen částečně. Tak písmeno E, které se v hlavních evropských jazycích vyskytuje nejčastěji, je, jak jsme se již zmínili, znázorněno tečkou, avšak jak O tak K jsou obě znázorněna třemi elementy, ač se O v angličtině vyskytuje asi třikrát častěji než K.
Dvě z nejdůležitějších vlastností kódových symbolů jsou jejich trvání, na němž závisí rychlost komunikace a snadnost jejich tvoření, na níž opět závisí jejich pohodlné užití. V případě mluveného slova může se délka symbolu vyjádřit počtem slabik nebo hlásek a snadnost užití jistých hlásek počtem kombinací, v něž tyto hlásky vstupují.
Podstatnou vlastností kódových symbolů je, že mají distinktivní hodnotu, tj. že umožňují, aby se snadno a správně rozeznávaly různé projevy. Zatímco počet slabik je prvním a základním znakem pro rozlišování mezi slovy, jemnější rozlišení mezi slovy téže délky je dáno fonémy jazyka.
Nejprve se ptáme, zda počet slabik na slovo uspokojí požadavky dyadického systému kódování, a potom, zda délka slov v daném písemném projevu je k frekvenci jejich výskytu v tom poměru, který vyžaduje teorie pro účinné kódování a zda se různé jazyky v tom charakteristicky liší. V terminologii informační teorie to znamená, že vypočítáme kvantitu entropie H pro danou distribuci slovních výskytů podle počtu slabik. Čím větší je tato kvantita pro daný jazyk, tím více jsme oprávněni považovat jazyk za systém, který vyhovuje podmínkám účinného kódování. Účinnost kódu se měří kvantitou 1 — H/H', což je míra nadbytečnosti. Čím větší je tato kvantita, tím větší je komprese proti rovnoměrné distribuci. To umožňuje srovnávání různých jazyků, pokud jde o nadbytečnost, tj. pokud jde o možnost odhadu délky slov. Pro angličtinu činí výše komprese asi 50 %, jak již bylo řečeno, kdežto pro ruštinu pouze asi 30 % a pro němčinu asi uprostřed mezi těmito hodnotami.
Jiným důležitým problémem, jímž se zabývá G. Herdan, je stabilita distribucí slovní délky. Dochází k závěru, že se slovní délka v daném jazyku nemůže pokládat za homogenní. Jsou zde rozdíly podle stadia jazykového vývoje, podle dialektu a dokonce i podle jednotlivých spisovatelů. Dále bylo zjištěno, že se vzorky vzaté z jednoho a téhož jazyka vcelku liší méně než vzorek z jednoho jazyka přenesený do jazyka druhého. Překvapuje, že v anglickém textu bylo zjištěno, že délka vzrůstá s časem, neboť to zdánlivě odporuje obecné tendenci k jednoslabičnosti v angličtině. Můžeme to však vysvětlit tím, že se distribuční funkce slovníku mění s časem. Vzrůstající obohacování slovníku má za následek, že se slovní výskyty méně koncentrují na několik často užívaných, a proto kratších slov. To opět působí vzrůst průměrné délky slova s časem.
Herdan dále dokazuje relativní stabilitu slovní délky v daném jazyce v daný čas. Není podstatný rozdíl v ukázce z literárního jazyka a z hovorového jazyka, nezáleží na tom, zda materiálem byl souvislý text nebo izolovaná slova tohoto textu, zda šlo o prózu nebo verše. Výsledkem dosavadního zkoumání je, že slovní délka je určujícím faktorem pro frekvenci užití slov: čím kratší je slovo, tím častěji se vyskytuje.
Pokud jde o délku slova, pohybuje se historie jazyka po výslednici dvou sil: aglutinační a izolující. Necháme-li stranou čínštinu, jakožto jazyk téměř úplně izolující, a jazyky indiánské, jakožto představitele jazyků polysylabických, většina jazyků zaujímá v této věci střední postavení. I uvnitř téhož jazyka je postup k izolaci charakteristickým rysem a mocným faktorem v jeho vývoji. Poněvadž jmenované jazyky (angličtina, němčina, ruština) představují různá stadia vývoje k jednoslabičnosti nebo k izolaci, představují též různé stupně shody s požadavky účin[62]ného kódování. Poněvadž angličtina má největší nadbytečnost 1 — H/H', může se říci, že má největší kódovou účinnost, další je němčina a poslední ruština. Herdan se domnívá, že mechanismus tendence k jednoslabičnosti nutno hledat v principu účinného kódování. Poněvadž účinnost v kódování musí být důležitým činitelem v rychlosti a přesnosti sdělování myšlenek, zdálo by se, že statistická teorie informace vede k neočekávanému závěru, že jazyky se v této věci liší. Obecný názor je, že každý jazyk je více méně dokonalý v tomto ohledu pro toho, kdo ho umí užívat. Že by měl být objektivně určitelný rozdíl v „dokonalosti“ jazyka, je nový názor Herdanův. Pokládá-li 1 — H/H' za míru dokonalosti nebo účinnosti jazyka pro přenos myšlení, angličtina by podle něho byla nejvýše mezi zkoumanými třemi jazyky; pak by následovala němčina a ruština.[8]
Pokud jde o slovní délku měřenou počtem fonémů, je i zde zachován princip účinného kódování, podle něhož slovní délka a frekvence výskytu mají být v obráceném poměru. Nadbytečnost slovní délky měřené počtem písmen je značně menší, než je-li měřena počtem fonémů, což znamená, že odhady slovní délky vyjádřené fonémy jsou úspěšnější, než jde-li o slovní délku vyjádřenou písmeny. To se dalo očekávat, neboť skutečně distinktivní funkci má foném, nikoli písmeno. Nejprve nutno brát v úvahu počet fonémů na slovo a potom určité fonémy. První zpřesnění nás vede k závěru, že ze slov s týmž počtem slabik je nejčastěji užito těch, která obsahují méně fonémů. Druhé zpřesnění vede k zjištění, že nejenom kvantita fonémů (tj. jejich počet na slovo) určuje frekvenci užití slova, avšak též jejich kvalita. Ze slov obsahujících týž počet fonémů některá budou mít mnohem větší frekvenci užití než jiná a rozlišujícím rysem mezi takovými slovy je různost fonémů nebo fonémických kombinací.
Nejnovější článek Gustava Herdana[9] zpřesňuje pojem entropie, pokud se jí užívá v lingvistice. Autor zde za prvé konstatuje, že entropie H neměří v lingvistice informaci, nýbrž spíše její nedostatek, a že by se pro měření informace mělo užívat negativní entropie, tzv. negentropie. Za druhé, entropie H je logaritmická kvantita, a tudíž se nemůže interpretovat nelogaritmickými termíny; tzv. „bits of information“ nemají skutečně lingvistický význam. Autor transformuje tradiční výraz entropie v statistickou kvantitu všeobecné použitelnosti v lingvistice a nazývá ji mírou opakování (repeat rate). Míra opakování je při nejmenším rovna antilogaritmu negentropie (= negativní entropie), neboli antilogaritmus negentropie je dolní limit míry opakování nebo Yulovy charakteristiky K.
Užívajíce pojmu nerovnosti, můžeme vyjádřit např. rozdíl v entropii pro délku anglických slov vyjádřenou počtem písmen H = 2.628 a délku slov vyjádřenou počtem fonémů H = 2.274, když řekneme, že míra opakování pro určité slovní délky je alespoň 1 v 6.3 slovech, je-li délka slova měřena počtem fonémů. Jinými slovy, vezmeme-li dvě slova namátkou z velmi dlouhého textu a zjistíme délku slova, ukáže se, že slovní délka se opakuje mnohem častěji, je-li měřena fonémy.
Překlad z jednoho jazyka do druhého se může pokládat za bivariátní kódování sdělení, tedy za příklad dvojitého kódování. Identický projev je vyjádřen dvěma různými jazykovými kódy. Nejprve je zakódován v původním jazyce, z něhož jej překladatel musí dešifrovat, dříve než jej převede do kódu jazyka překladu. Je-li entropie vypočítána pro danou kvantitativní charakteristiku, jako je např. délka slova, nezávisle pro každý z obou jazyků, originál i překlad, získané hodnoty se budou zpravidla od sebe lišit a též od hodnoty bivariátní entropie, tj. od entropie vypočítané ze slovní délky překladových ekvivalentů (slov označujících týž pojem v obou jazycích). Přesněji, podmíněná entropie, tj. entropie pro slovní délku v překladových ekvivalentech slov v originálu určité délky, je menší než nepodmíněná entropie.
Tak pro překlad z francouzštiny do angličtiny činí podmíněná entropie 0,923 bitu a nepodmíněná 1,410 bitu; v překladu z němčiny do angličtiny první je 1,162 bitu, druhá 1,648 bitu; v překladu z ruštiny do angličtiny je první 1,153 bitu, druhá 2,000 bitu.
Tyto vztahy nejsou příliš jasné, jsou-li vyjádřeny pomocí entropie v její konvenční formě. [63]Vztah nerovnosti nám umožňuje učinit rozdíl mezi podmíněnou a nepodmíněnou entropií mnohem srozumitelnějším. Tímto vztahem vyjádříme rozdíly takto: pro překlad z francouzštiny do angličtiny je míra opakování slov ve francouzském originálu při nejmenším 1 ve 2,6 neboli přibližně 1 ve 3 a stoupá v překladových ekvivalentech alespoň k 1 ve 2; pro německo-anglický překlad je míra opakování slovní délky v originálu též přibližně 1 ve 3 a v překladových ekvivalentech stoupá opět alespoň na 1 ve 2 přibližně; pro rusko-anglický překlad je míra opakování slovní délky v originálu přibližně 1 ve 4 a stoupá v překladových ekvivalentech na 1 ve 2 (přesně 2,4).
Jedním z nejtěžších problémů komunikační teorie je problém strojového překladu. To by však bylo téma pro samostatný článek a nelze se jím dnes zabývat. Ostatně i zde jsme teprve na začátku řešení. (Srov. čl. P. Sgalla v tomto čísle SaS, s. 48n.)
III
Přínos teorie komunikace pro lingvistiku. V poslední části nám zbývá kritické zhodnocení přínosu teorie komunikace pro lingvistiku. Kolem r. 1950 byla situace taková, jak ji popisuje Oliver H. Straus:[10] „Dnes jsou badatelé v teorii komunikace rozděleni do dvou táborů. V jednom jsou inženýři a fonetikové, kteří pojednávají o fyzikálních zvucích neboli fónech, druzí jsou lingvisté, kteří se zajímají o fyzikální hlásky jen za účelem rozlišení v jazyce nebo dialektu, malé skupiny signálních jednotek zvaných fonémy, slova a celé promluvy.“ Od té doby se však oba tábory značně sblížily, navázaly kontakt, poznaly, že je toho dosti, co si mohou navzájem nabídnout, a tak v mnoha případech byla navázána plodná spolupráce. Byla provedena velká řada pokusů a formulována teoretická hlediska, která jsou ve shodě s hlediskem informační teorie. Pokrok v našem porozumění informačním aspektům řeči a jazyka patří k přínosu posledních let jak pro vznikající komunikační vědu, tak i pro lingvistiku.
Je celá řada lingvistických problémů, k jejichž řešení informační teorie přispěla, a řada problémů, které lingvistika dosud neviděla nebo které nemohla řešit svými dosavadními metodami.
Především jde o pojem „informace“. Pro teorii komunikace je irelevantní, jak bylo uvedeno, zda sdělení má nějaký význam nebo ne, neboť komunikačním inženýrům jde jen o to, aby se určitý signál dostal ze zdroje přes vysílač komunikačním kanálem k přijímači, jde jim o ryze fyzikální pochod, o věrnost přenosu, o způsob přenosu. Naproti tomu v lingvistice může jít, jak se domníváme, o dva případy: jednak máme zájem na tom, aby se určitá informace dostala ze zdroje informace k přijímači a na místo určení, čili jde nám v podstatě o totéž, oč jde komunikačnímu inženýru. Na druhé straně nám však musí jít o informaci v lingvistickém smyslu, tedy o význam, neboť v lingvistické komunikaci jde o přenos myšlenek vyjádřených řečí nebo psaným jazykem, nějakým způsobem kódovaným, aby se mohly přenášet. To je normální, běžný případ. Je ovšem pravda, že lingvistické sdělování nemusí mít vždy formu informace v sémantickém smyslu. Jsou někdy situace, kdy lingvistické sdělování neobsahuje žádnou informaci v sémantickém smyslu, nemá „význam“ v obvyklém smyslu toho slova. Sejdou-li se dva lidé a začnou mluvit třebas o počasí, nemusí to znamenat, že si chtějí sdělit informaci o počasí, nýbrž rozmluva má za účel jen navázání styků mezi dvěma osobami. Je mnoho situací, v nichž hovor sleduje docela jiný účel, než je sémantický obsah mluveného slova. V podstatě docházíme k závěru, že pojem informace v teorii komunikace a v lingvistice se nemůže úplně krýt a poměr těchto dvou pojmů je nutno v obou vědách vyjasnit.
Zdá se, že nejplodnějšími pojmy teorie komunikace jsou pro lingvistiku pojmy entropie a nadbytečnosti. Jsme přesvědčeni, že zde jsme plně oprávněni srovnávat stav systému fyzikálního a systému lingvistického. Je to otázka přímo základní, neboť se týká problému srozumitelnosti jazykového projevu, který byl doposud v tomto významu v lingvistice opomíjen. Je [64]sice pravda, že funkční jazykověda již svým základním hlediskem relevance či irrelevance jazykových jevů nebo určitých jazykových rysů v podstatě uplatňovala do jisté míry hledisko informační teorie, avšak teprve pojem nadbytečnosti ukázal význam tohoto problému v celé šíři a hloubce. Je však otázka, zda je vždy nadbytečné to, co je funkčně irelevantní nebo zda není nadbytečné někdy to, co je funkčně relevantní. Nadbytečnost je pro jazyk neobyčejně důležitá, neboť zvětšuje spolehlivost jazykové komunikace a činí ji odolnou vůči mnohým případům distorze čí zkreslení. Na druhé straně, jsou-li podmínky přenosu sdělení dobré, znamená velké množství nadbytečnosti mrhání časem.
Jde-li o komunikaci prostřednictvím mluveného jazyka, je věc daleko složitější, než jde-li o psaný nebo jakkoli kódovaný jazyk. Ani tento problém není informační teorií zanedbáván, i když není dosud tak podrobně prozkoumán jako jiné druhy komunikace.[11]
Fano správně poukazuje na to, že jde-li o komunikaci mezi dvěma osobami, potřebujeme vědět, kromě charakteristiky komunikačního systému externího těm dvěma osobám, též všechny možné charakteristiky těchto dvou osob v každém okamžiku přenosu. Zvláště potřebujeme znát podrobnosti o činnosti jejich hlasových a sluchových orgánů a o jejich minulé zkušenosti, které jsou uloženy v jejich mozku. To ovšem by bylo možné jen teoreticky, nikoli prakticky.
Při zjišťování informačního obsahu řeči jsou podle Fana možné dva rozdílné postupy. Jeden je založen na předpokladu, že informace vyslaná posluchači mluveným sdělením není znatelně větší než informace vyjádřená korespondujícím psaným sdělením. Tento předpoklad může být ovšem právem kritizován na základě faktu, že v psaném sdělení chybí charakteristika hlasu mluvčího a zvláště ty zvukové inflexe, které mohou někdy úplně změnit význam věty. Jsou to případy sdělení toho druhu jako To byl dnes pěkný den!, kde pronesené sdělení může mít zcela opačný význam než sdělení psané; vlastně každé sdělení dostává zvukovými vlastnostmi určitou další informaci, kterou psané sdělení nemá. Fano se snaží alespoň o částečné ospravedlnění tohoto předpokladu, avšak zdá se, že podceňuje úlohu zvukových vlastností, pokud jde o jejich vliv na informaci.
Druhý postup potřebuje k objasnění uvážení procesu vzniku vln řeči. V případě znělých hlásek vytvářejí hlasivky zhruba trojúhelníkovou vlnu pomalu se měnící amplitudy a periody. Tato vlna je filtrována hlasovým traktem, který si můžeme představit jako lineární síť. Přenosové vlastnosti této sítě se mění s časem přibližně v témže poměru jako perioda trojúhelníkové vlny, takže vlnu řeči můžeme pokládat za jakousi periodickou časovou funkci. Případ neznělých hlásek se liší od znělých jen tím, že za hlasivky musí být substituován zdroj hluku. Tak můžeme předpokládat, že kanálová kapacita požadovaná pro znělé hlásky je dostačující i pro hlásky neznělé. Zajímavá je myšlenka, kterou rozvádí Fano, že totiž různí mluvčí užívají v jistém smyslu různých kódů. Tyto kódy jsou uskladněny v mozku posluchače, který užívá v každém případě přiměřeného kódu. Novým kódům se stále učíme, když se setkáváme s novými lidmi, zvláště s lidmi patřícími k různým lingvistickým skupinám. Toto hledisko je v souhlase s pozorováním, že naše schopnost rozumět a úsilí požadované pro porozumění závisí na naší obeznámenosti s hlasem mluvčího. Kromě toho jsme si často vědomi „přehození (či přepojení) kódu“ (switching code) v našem mozku, zvláště když nastane změna jazyka. Identifikace vhodného kódu a naučení se novému kódu jsou velmi složité statistické procesy; vyžadují analytické a uskladňovací prostředky (storage facilities), které jsou k dispozici pouze v lidském mozku.
Fanovu charakteristiku procesu komunikace prostřednictvím řeči by bylo lze doplnit poukazem na jiného důležitého činitele, který má vliv na porozumění, a tudíž na informaci: je to rychlost promluvy, nikoli ovšem absolutní rychlost, nýbrž relativní rychlost ve vztahu k schopnosti při[65]jímající osoby reagovat přiměřeným způsobem na rychlost řeči; tato rychlost je u různých jedinců a za různých okolností různá; podrobnější pozorování v tomto směru by přispěla k celkové charakteristice komunikačního procesu řeči.[12]
Norbert Wiener si uvědomuje podobnosti i rozdíly mezi pojmem „informace“ v technice a v lingvistice. Při přenosu lingvistické informace rozeznává Wiener tři stadia: stadium recepce, stadium fonetické a stadium sémantické. Zde musíme být podle Wienera s měřením velmi opatrní, protože sémantické stadium obsahuje jako podstatnou část dlouhodobý ukládací aparát mozku, který nazýváme pamětí a my kombinujeme konstatování právě učiněné se vzpomínkou vzatou z paměti. Domníváme se, že Wiener nejlépe ze všech badatelů v teorii komunikace vystihl rozdíl mezi strojovou a lingvistickou komunikací, když píše, že to, co se stává jasným kvantitativním konstatováním ve strojové komunikaci, stává se v lingvistice konstatováním kvalitativním. Přitom však Wiener nevěří, že existuje nějaký základní protiklad mezi problémy komunikačních inženýrů a problémy lingvistickými.
John Lotz vidí v řeči nástroj sdělování sémantického obsahu, významu. Řeč se může analyzovat v znakové složky, které mají svou vlastní sémantickou referenci (tzv. sémiotická analýza); navrhuje pro ni termín sémantické spektrum. V lingvistice jsou podle Lotze nezbytné tyto sémiotické jednotky: morfém, slovo, fráze, věta a souvětí. Tyto jednotky tvoří sémiotickou hierarchii. Zvukové prostředky, které signalizují sémiotické jednotky, jsou různého druhu; např. vydržený, neklesavý přízvuk na slově three ve sledu morfémů one, two, three signalizuje neúplnost, klesající přízvuk, ukončenost věty. Rozdíl důrazu a rytmu v morfémové dvojici black-bird ukazuje, zda jde o zvláštní druh ptáka nebo specificky zbarvený typ celé třídy. Nebo způsob připojení může rozlišovat an aim od a name atd. Takové rysy nazýváme konstruktivní rysy. Druhý typ hláskových rysů jsou distinktivní či fonémické rysy, které neobsahují samy o sobě žádnou sémantickou informaci; slouží pouze výstavbě morfémů. Naproti tomu konstruktivní rysy obsahují informaci o tvoření sémiotických jednotek v jejich hierarchii. Oba druhy rysů jsou buď přítomné nebo nepřítomné; není tu možná gradace. Kromě těchto rysů, které určují jazykové společenství, uznává Lotz ještě třetí rys, nositele řeči, který je sociálně určen, tj. způsob mluvy. Tento rys je konstantní. Rovněž konstantními rysy jsou vlastnosti hlasových orgánů mluvčího. Konečně je tu proměnný faktor: výraz emočního poměru mluvčího.
Dále zdůrazňuje Lotz binární princip protikladů, ač správně přiznává komplikace, které vznikají při aplikaci binárního principu, máme-li tři elementy (např. i, e, æ v angličtině), které všechny obsahují společný rys; v takovém případě musíme podle Lotze zavést buď komplexní střední termín, nebo připustit trinární protiklady. Případ anglických samohlásek i, e, æ neodporuje binární teorii, poněvadž střední člen (e) je členem dvou binárních protikladů: je nekompaktní ve [66]vztahu k (æ) a nedifúzní ve vztahu k (i). Dodejme ještě, že i Trubetzkoj vycházel z binárních pritikladů, ovšem uznával i protiklady stupňové. Z hlediska teorie komunikace představují binární protiklady nejekonomičtější uspořádání promluvy jakožto prostředku, jímž jsou sdělovány informace.
Máme-li na závěr stručně shrnout naše stanovisko k teorii komunikace, pak musíme zdůraznit hlavně dvě věci:
1. Pokud se teorie komunikace zabývá sdělováním jazyka psaného nebo tištěného, je její aplikace na lingvistiku zcela oprávněná a je nutno přiznat, že dosavadní výzkumy ukázaly v tomto směru mnoho užitečného. Pojem nadbytečnosti pokládám za nejplodnější pojem informační teorie i z hlediska lingvistického. Je ovšem nutné zkoumat nadbytečnost ve všech rovinách jazyka, neboť nadbytečné nejsou jen hlásky, nýbrž i morfémy a celá slova. Ideálním stavem v jazyce by ovšem bylo, kdyby v něm nebylo nic nadbytečného. Víme však, že stejně slovo jako věta mohou být ve formě optimální a ve formě redukované. U slov je to např. v angličtině známý zjev gradace, pokud jde o větu, je to stylistická forma. Nadbytečnost zastává vlastně funkci kontroly informace.
2. Pokud se teorie komunikace zabývá sdělováním řeči mluvené, musíme být při její aplikaci velmi opatrní, neboť lidský činitel zde mnohonásobně komplikuje celý postup komunikace tak, že činí vypracování nějaké všeobecně platné teorie za nynějšího stavu bádání velmi problematickým. Nelze se proto divit, že dosud neexistuje opravdu široce založená studie, která by problém sdělné promluvy řešila v jeho celistvosti. To ovšem neznamená, že bychom se neměli pokoušet o takovou teorii, neboť dosavadní výzkum již dostatečně ukázal, že jazyk je v podstatě pravidelný a že individuální jednotky jazyka vykazují variace uvnitř této pravidelnosti. Kdyby tomu tak nebylo, byla by lingvistická komunikace nemožná.
[1] Z podnětu prof. B. Trnky.
[2] Cybernetics, or control and communication in the animal and the machine, New York 1949. Od téhož autora srov. The Human Use of Human Beings. Cybernetic Society, New York 1956.
[3] Werner Meyer-Eppler, Informationstheorie, Die Naturwissenschaften 39, 1952, s. 341.
[4] Z ostatních badatelů, kteří přispěli k rozvinutí teorie komunikace, zejména po stránce lingvistické, jmenuji alespoň Johna Lotze, R. M. Fano, Olivera H. Strause a S. S. Stevense, jejichž příspěvky jsou uveřejněny ve 22. svazku (r. 1950) časopisu The Journal of the Acoustical Society of America, dále B. Mandelbrota (Structure formelle des textes et communication, Word 10, 1954, s. 1—27) a P. Guirauda (Langage et communication. Le substrat informationnel de la sémantisation, Bulletin de la Société de linguistique de Paris 50, 1954, s. 119—133). V časopisu Die Naturwissenschaften je cit. článek o informační teorii od Wernera Meyer-Epplera. Podrobně se zabývá informační teorií též G. Herdan v knize Language as Choice and Chance (Groningen 1956). Řada dalších prací, např. George A. Millera, Language and Communication, Gunnara Fanta Discussion Symposion on the Applications of Communication Theory (Londýn 1952), D. Gabora Lectures on Communication Theory (1951), MIT aj., jsou nám nepřístupné, takže obraz, který si můžeme učinit o pokroku informační teorie, je již proto neúplný.
[5] Viz Transactions of the First Prague Conference on Information Theory, Statistical Decision Functions, Random Processes, Prague 1957.
[6] Prediction and Entropy of Printed English, The Bell System Technical Journal 30, 1951, s. 50—64.
[7] Control Tower Language, JASA 24, 1952, s. 595—6.
[8] Na slabinu této části Herdanových výkladů ukazuje zde stať Sgallova, s. 52.
[9] An Inequality Relation Between Yule’s Characteristic K and Shannon’s Entropy H, Journal of Applied Mathematics and Physics, sv. IX, seš. 1/1958, s. 69—73.
[10] The Relation of Phonetics and Linguistics to Communication Theory. JASA 22, 1950, s. 709.
[11] Máme zde však několik dobrých prací, z nichž jmenuji alespoň tyto: R. M. Fano, The Information Theory Point of View in Speech Communication, JASA 22, 1950, s. 691—696; John Lotz, Speech and Language, JASA 22, 1950, s. 712—717 a krátký, avšak významný článek Norberta Wienera Speech, Language and Learning, JASA 22, 1950. s. 696—7.
[12] Dodejme k tomu, že problémem srozumitelnosti se zabývá v poslední době řada studií, např.: J. M. Pickett, Perception of Vowels Heard in Noises of Various Spectra, JASA 29, 1957, s. 613—620; Davis Howes, On the Relation between the Intelligibility and Frequency of Occurrence of English Words, JASA 29, 1957, s. 296—305; Grant Fairbanks a Frank Kodman ml., Word Intelligibility as a Function of Time Compression, JASA 29, 1957, s. 636 až 641; G. Fairbanks, N. Guttman, M. S. Miron, Effects of Time Compression upon the Comprehension of Connected Speech, The Journal of Speech and Hearing Disorders, 22, 1957, s. 10—19; G. A. Miller a W. G. Taylor, The Perception of Repeated Bursts of Noise, JASA 20, 1948, s. 404—411. Z našich prací, pojednávajících o srozumitelnosti řeči hlavně z akustického hlediska, jmenujme alespoň tyto: J. Vott, J. Vachek a J. B. Slavík, Akustika hlediště v divadelním provozu, Praha 1943; J. B. Slavík, Akustika kinematografu, Praha 1943; J. Vachek, Jazykovědný pohled na sovětské zkoušky srozumitelnosti telefonního přenosu. Sb. prací fak. elektrotech. inženýrství ČVÚT 1956/57, 459n.; srov. i SaS 15, 1954, 165n.; 17, 1956, 40n., 110n., 178n. a 18, 1958, 62n. (Hála, Vachek, Borovičková, Romportl).
Informační schopnost člověka je předmětem studie G. A. Millera, The Magical Number Seven, Plus or Minus Two: Some Limits on our Capacity for Processing Information, The Psychological Review, 63, 1956, s. 81—97). Viz též Gordon E. Peterson, Fundamental Problems in Speech Analysis and Synthesis (Reports for the Eighth Intern. Congress of Linguists, Oslo, 319n.).
Slovo a slovesnost, volume 20 (1959), number 1, pp. 55-66
Previous Petr Sgall: Nové otázky matematických metod v jazykovědě
Next Antonín Vašek: Nová práce o valašském nářečí
© 2011 – HTML 4.01 – CSS 2.1